
이번 챕터는 Entity Resolution의 두 번째 단계인 Record Blocking이다. 앞서 데이터를 비교하고 매칭할 때는 모두 레코드들의 쌍을 비교하는 식의 방법을 사용했는데, 이는 데이터의 사이즈가 큰 경우에는 거의 불가능하다. 따라서 이 경우 연산량을 줄이기 위해 Record Blocking이 필요하다.
이전에는 영국 하원 의원 정보를 다뤘는데, 이번에는 그 사이즈를 키워서 영국에 등록된 회사의 중요 관리자(persons with significant control, PSCs) 명단을 사용한다. 영국에서 기업 등록소(Companies House)에서는 회사의 설립, 소유자 등과 관련된 정보를 의무적으로 등록해야 하며, 이를 공개한다. 이 데이터에 있는 PSCs 데이터와 영국 국회의원 정보를 비교해서 어느 국회의원이 영국 기업의 중요 관리자(PSCs)인지 파악하는 것을 목표로 한다.
1️⃣ Data Acquisition
Wikipedia Data
위키피디아 데이터는 Chapter2에서 했던 것 처럼 html table을 파싱해서 dataframe으로 변환한다. 교안에는 2019년 기준으로 되어 있지만, 실습은 2024년 기준으로 바꿔서 진행했고, 수정한 코드는 코랩 파일에 있다.
이전 데이터와 차이가 있다면, 의원들의 birthdate를 추가해줬다는 점이다. 하원 목록이 있는 테이블에 의원들의 이름은 모두 개별 url로 연결되어 있는데, 이 링크를 모두 수집한 뒤, 아래 함수를 통해 개별 페이지에서 생년월일을 가져와서 추가해준다.
def get_bday(url):
wiki_page = requests.get(url).text
soup = BeautifulSoup(wiki_page,'html.parser')
bday = ''
bdayelement = soup.select_one("span[class='bday']")
if bdayelement is not None:
bday = bdayelement.text
return(bday)UK Companies House Data
영국의 기업데이터는 이 사이트에서 JSON을 zip 파일로 제공한다. 이들을 모두 다운받은 뒤 하나의 파일로 concat 해준다.
2️⃣ Data Standardization
Wikipedia Data
우선 Birthday 컬럼을 정수 형태의 month, year 컬럼으로 분리해준다. 그리고 Chapter2에서 해준 것 처럼 Fullname을 Lastname, Firstname으로 분리하고 strip이나 개행문자 제거 등과 같은 기본적인 전처리도 진행한다.
df_w = df_w.dropna()
df_w['Year'] = pd.to_datetime(df_w['Birthday']).dt.year.astype('int64')
df_w['Month'] = pd.to_datetime(df_w['Birthday']).dt.month.astype('int64')또한 Splink 프레임워크를 사용하기 위해선 고유한 ID 값이 필요하기 때문에 테이블의 index를 unique_id 컬럼으로 만들어주고, 현재 회사 번호는 없지만, 추후 머지를 위해서 빈 열인 company_number를 추가한다.
df_w['unique_id'] = df_w.index
df_w["company_number"] = np.nan
df_w=df_w[['Firstname','Lastname','Month','Year','unique_id','company_number']]UK Companies House Data
기업 데이터에서는 우선 생년월일 정보가 없으면 매칭할 수 없기 때문에, 이 컬럼의 값이 비어있는 행은 모두 삭제한다. 이후 위키피디아와 같이 Month와 Year를 int로 바꾸고, 이름 형식도 똑같이 만들어준다.
df_psc = df_psc.dropna(subset=['data.date_of_birth.year',
'data.date_of_birth.month'])
df_psc['Year'] = df_psc['data.date_of_birth.year'].astype('int64')
df_psc['Month'] = df_psc['data.date_of_birth.month'].astype('int64')
df_psc['Firstname']=df_psc['data.name_elements.forename']
df_psc['Lastname']=df_psc['data.name_elements.surname']
df_psc['unique_id'] = df_psc.index
df_psc = df_psc[['Lastname','Fir3️⃣ Record Blocking and Attribute Comparison
가장 간단하게 Lastname, Firstname, Year, Month를 기준으로 exact matching을 진행하면 다음과 같이 89행이 도출된다.
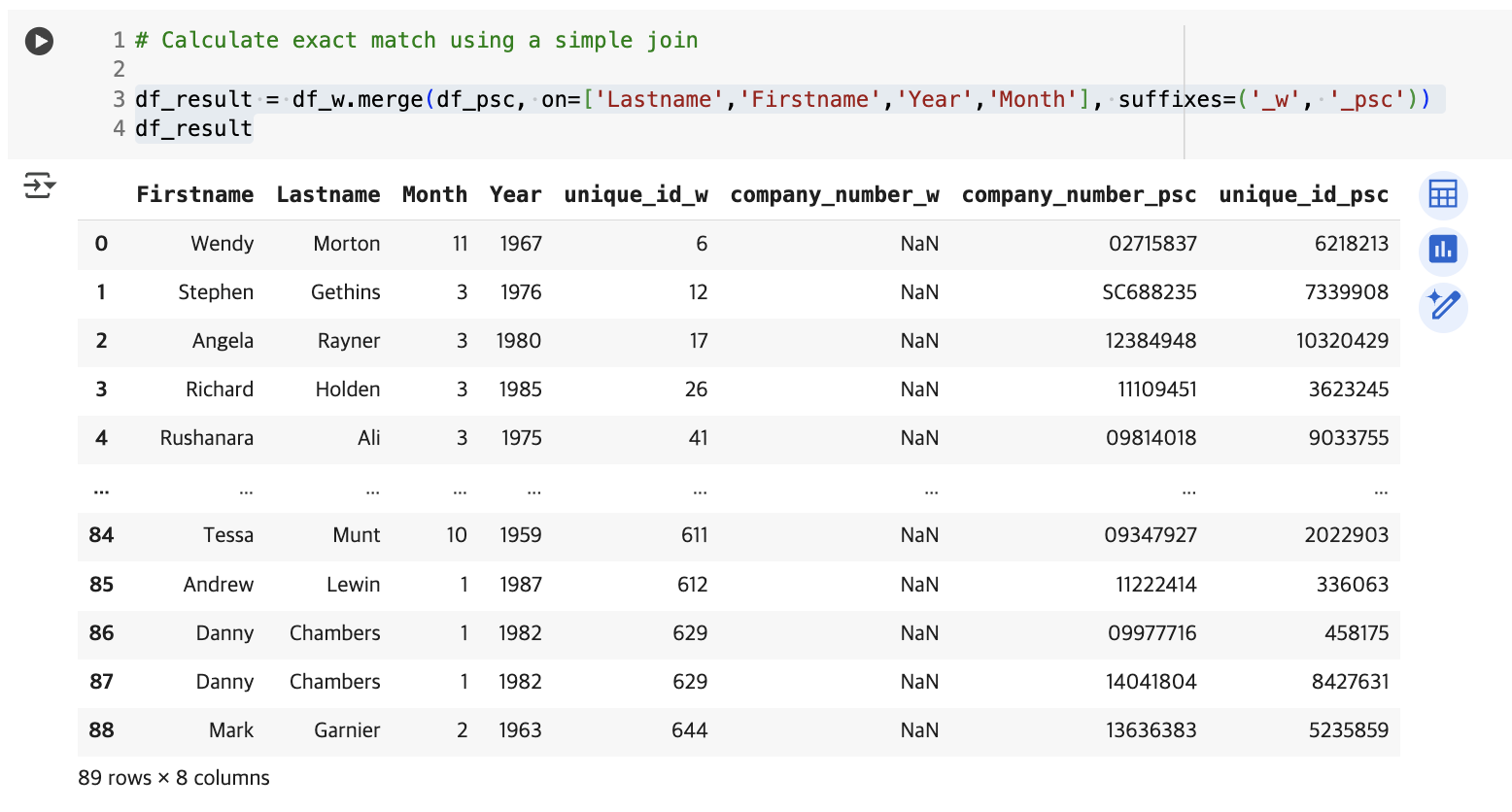
국회의원 데이터가 650행, 기업 데이터가 1000만 행 이상인 걸 고려했을 때 굉장히 적게 매칭된다는 것을 알 수 있다.
Record Blocking with Splink
Record Blocking은 두 데이터를 합칠 때 고려해야 하는 조합의 수를 줄여주는 방법이며, 이를 위해 Splink 라이브러리를 통해 EM(Expectation-Maximization)알고리즘을 활용한다. 물론, 일부 데이터만 활용하는 것은 정확도를 낮추는 방법이 될 수 있으므로 이런 위험성을 최소화하고 동시에 비교대상의 양을 최대한 줄이는 최적의 상태를 찾아야 한다.
Splink는 OR문 등을 사용해서 여러 조건 중 어느 하나라도 충족되면 해당 조합을 추가 비교대상으로 선택하는 '복합 규칙'을 만들 수 있다. 교안의 예제에서는 출생연도와 월이 일치하는 레코드만 선택하는 단일 블로킹 규칙을 사용한다. 교안의 Splink 코드는 4.xx 이하 버전이어야 하므로 3.9.15를 설치해서 사용했다.
from splink.duckdb.linker import DuckDBLinker
from splink.duckdb import comparison_library as cl
settings = {
"link_type": "link_only",
"blocking_rules_to_generate_predictions":
["l.Year = r.Year and l.Month = r.Month"],
"comparisons": [
cl.jaro_winkler_at_thresholds("Firstname", [0.9]),
cl.jaro_winkler_at_thresholds("Lastname", [0.9]),
cl.exact_match("Month"),
cl.exact_match("Year", term_frequency_adjustments=True),
],
"additional_columns_to_retain": ["company_number"]
}이전 챕터에서도 Splink를 사용했지만, 이번에는 설정하는 파라미터를 하나씩 살펴보겠다. 우선 백엔드 데이터베이스는 별도의 서버 연결이 필요 없는 DuckDB를 사용한다. 그리고 link_type은 link_only로 설정하여 서로 다른 두 데이터셋을 연결하는 작업을 수행하고(단일 데이터셋으로도 수행할 수 있음), blocking 후보로는 Year, Month를 둔다. 즉, Year과 Month가 일치하지 않는 사람들은 아예 비교하지 않겠다는 것을 의미한다. 이후 실제 비교 대상은 Firstname과 Lastname인데 이는 Jaro-Winkler를 통해 비교하고 0.9 이상일 경우 일치하는 조건을 설정한다. term_frequency_adjustments=True의 경우, 흔하지 않은 연도가 일치했을 때, 흔한 연도가 일치했을 때보다 더 높은 가중치를 부여하는 조건을 의미한다. additional_columns_to_retain은 비교가 끝난 후 최종 결과에 'company_number' 컬럼을 추가로 남기는 파라미터인데, 비교에는 사용하지 않고 나중에 결과를 분석할때 사용하기 위함이다.
Attribute Comparison
linker = DuckDBLinker([df_w, df_psc], settings, input_table_aliases=["df_w", "df_psc"])
linker.profile_columns(["Firstname","Lastname","Month","Year"], top_n=10, bottom_n=5)위에서 설정한 세팅값을 기준으로 프로파일링하는 코드이다. 프로파일링할 컬럼은 4개를 설정하고, 각 컬럼에서 가장 빈도가 높은 상위 10개와 하위 5개만 도출한다. 결과는 다음과 같은 시각화로 나타난다.
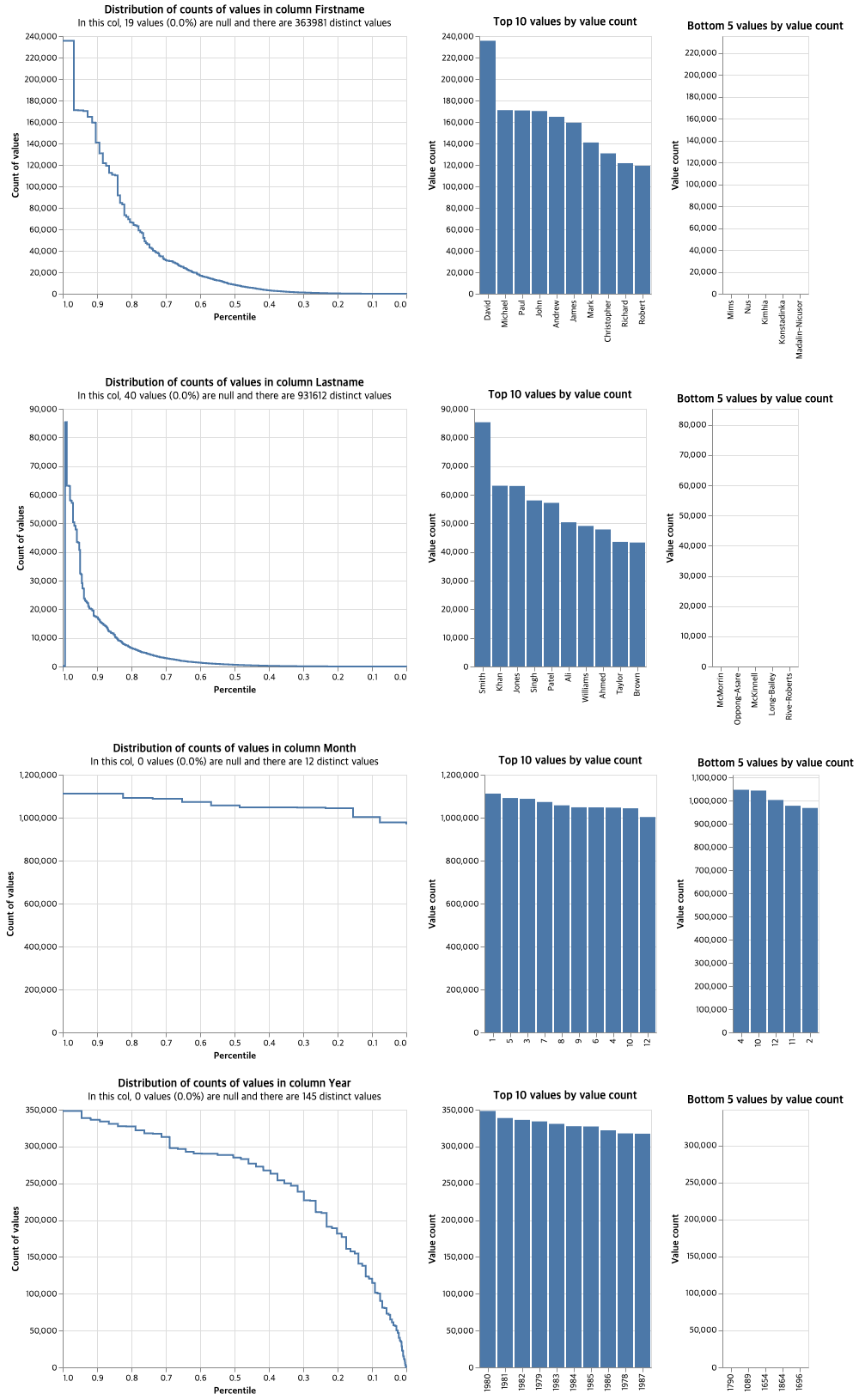
Firstname의 분포 그래프는 David, Michael과 같은 소수의 성이 매우 빈번하게 나타나고 대부분은 드물게 나타나는 롱테일 분포를 보인다. Lastname도 이와 유사한 양상이다.
Month는 비교적 균등하게 분포되어 있어 1월부터 12월까지 출생 빈도에 큰 차이가 없다고 볼 수 있고, Year는 특정 연도(80년대)가 다른 연도보다 더 자주 나타나고 있다. 앞서 드물게 나타나는 연도에 더 높은 가중치를 주기로 했기 때문에 이 부분에서 가중치가 부여될 수 있다.
다음은 m value와 u value를 통해 확률값을 추정하는데, 우선 두 레코드가 일치하지 않을 때 특정 속성이 우연히 같을 확률인 u value의 경우, 임의의 두 레코드 쌍을 비교하여 우연히 일치하는 경우가 얼마나 자주 발생하는 지를 계산한다. 이때 max_pairs는 1000만 으로 설정하여 최대 1000만개의 랜덤한 레코드 쌍을 비교하여 u value를 추정한다는 의미이다(실제로 전체 조합을 생성하면 이것보다 훨씬 많다).
# Estimate u values
linker.estimate_u_using_random_sampling(max_pairs=1e7)이후 진행하는 estimate_parameters_using_expectation_maximisation 역시 이전에는 True 파라미터를 줘서 모든 레코드값을 비교했는데, 이번에는 랜덤 샘플만 비교를 한다. 이때 앞서 추정했던 u value가 영향을 준다. EM 알고리즘은 반복적으로 계산을 하고 최종적으로 수렴되는 값을 도출하기 때문에 잘못된 초기값이 들어가면 local minimum(주변값들 중에서는 작은 값이지만, 전체를 보면 가장 작은 값이 아닌 것)에 빠질 수 있다. 따라서 앞서 랜덤 샘플링을 통해 u value를 미리 추정해서 넣어주면, EM이 더 안정적으로 수행될 수 있다고 한다.
** 수정
교안에서 1000만행을 샘플링하길래 똑같이 넣어줬는데, 교안에서 사용한 데이터셋과 차이가 있다는 사실을 간과했다. 실습에서 사용한 데이터셋의 전체 행 수는 약 425만행 정도 였기 때문에, 이 부분에서도 이보다 작은 값을 넣어줘야 샘플링하는 의미가 생긴다. 물론 1000만행을 넣어줘도 이 파라미터는 max값을 지정하는 부분이기 때문에 에러는 없지만, 샘플링이 되지 않고 전체 행을 다 계산하게 된다.
linker.estimate_parameters_using_expectation_maximisation
("l.Lastname = r.Lastname and l.Month = r.Month",
fix_u_probabilities=False)
linker.estimate_parameters_using_expectation_maximisation
("l.Firstname = r.Firstname and l.Year = r.Year",
fix_u_probabilities=False)위 코드에서는 Lastname과 Month로 먼저 Blocking을 하고, 그 안에서 다시 Firstname과 Year의 m, u value를 추정한다. 블로킹한 데이터에서는 Lastname과 Month는 모두 동일할 것이므로 m, u value를 추정할 수가 없으므로 블로킹에 사용하지 않은 다른 두 속성인 Firstname과 Year의 값만 추정하는 것이다. 반대로 Lastname과 Month의 확률값은 Firstname과 Year를 Blocking해서 계산한다. 각각 10번, 14번씩 iteration을 진행했고, 결과를 시각화하면 다음과 같다.
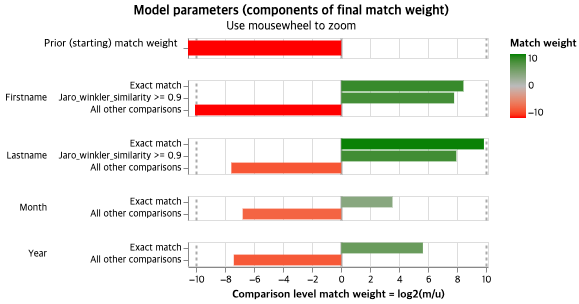
우선 prior match weight는 음수로, 매치되는 레코드쌍은 매우 적다는 것을 알 수 있다. 또한 Firstname과 Lastname의 경우, exact matching되거나 Jaro-winkler 유사도로 계산했을 때 유사한 정도가 높으면 동일한 인물일 가능성, 즉 가중치를 크게 주고 있지만, 그렇지 않을 경우에는 강력하게 음의 가중치를 주고 있다. Month은 양의 가중치도, 음의 가중치도 작은 것으로 보아 매칭에 큰 영향을 주는 속성이 아니라는 것을 알 수 있다.
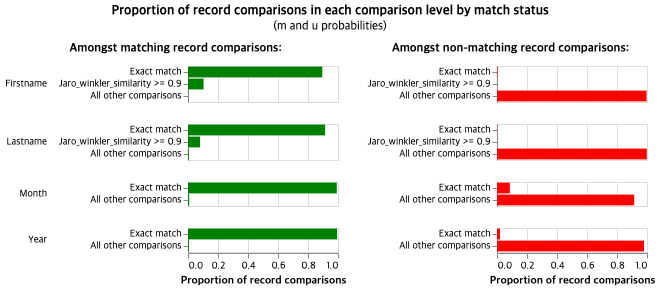
위 그래프틑 EM 알고리즘의 비교 수준을 나타내는데, 매칭이 되는 경우는 대부분 정확히 일치하는 경우가 많았다.
4️⃣ Match Classification
이제 각 속성에 대해 매칭 확률값(m, v)를 가지고 있으므로 이전에 settings에서 줬던 "blocking_rules_to_generate_predictions": ["l.Year = r.Year and l.Month = r.Month"] 블로킹 조건에 해당하는 레코드 쌍에 대해서 두 레코드가 같은 엔티티인지 예측하는 작업을 진행한다.
results = linker.predict(threshold_match_probability=0.99)
pres = results.as_pandas_dataframe()
pres = pres.rename(columns={"Firstname_l": "Firstname_psc",
"Lastname_l": "Lastname_psc",
"Firstname_r":"Firstname_w",
"Lastname_r":"Lastname_w",
"company_number_l":"company_number"})
pres = pres[['match_weight','match_probability','Firstname_psc','Firstname_w', 'Lastname_psc','Lastname_w','company_number','unique_id_r']]
pres예측하는 행은 month와 year가 같은 행 중에서 m, u, λ를 통해서 Firstname과 Lastname 속성을 기반으로 두 레코드를 비교하고 0.99 이상일때만 매치라고 판단한다. 그 결과 120행이 도출되었다. 이 중에서 Firstname이 같지 않거나 Lastname이 같지 않은 경우는 79행이 도출되었다.
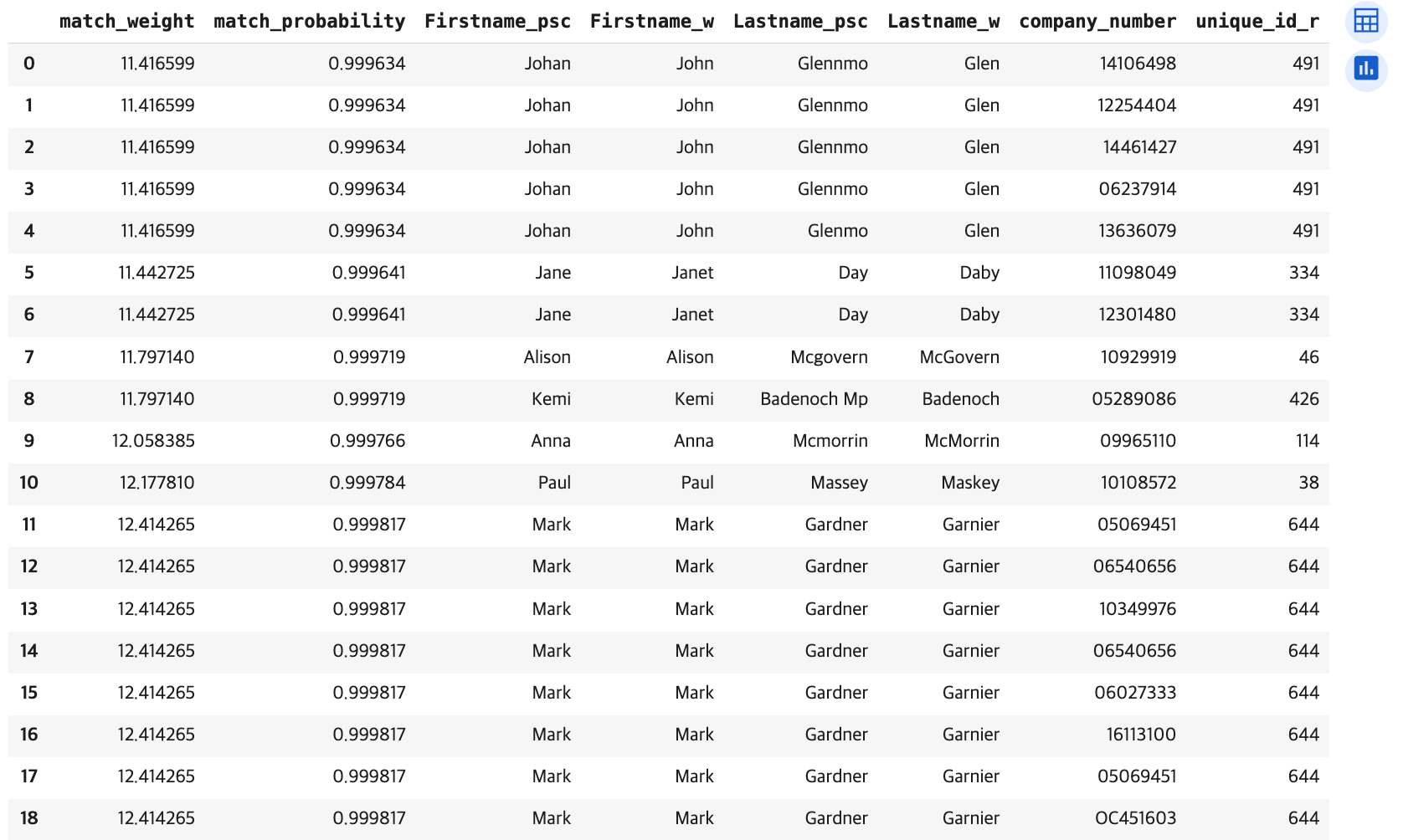
초기에 정규화를 진행해줬지만, 여전히 대소문자가 일치하지 않거나 정제되지 않은 부분들이 있다는 것을 확인할 수 있다.
df_pres = pres.groupby(['unique_id_r'], sort=False).agg(lambda x: list(set(x))).reset_index()
df_pres[(df_pres['company_number'].apply(len)>2) & df_pres['Lastname_psc'].apply(len)==1]이제 개별 국회의원(unique_id_r)에 대응되는 company_number을 확인하기 위해 groupby를 통해 확인해보면 다음과 같은 결과가 도출된다.
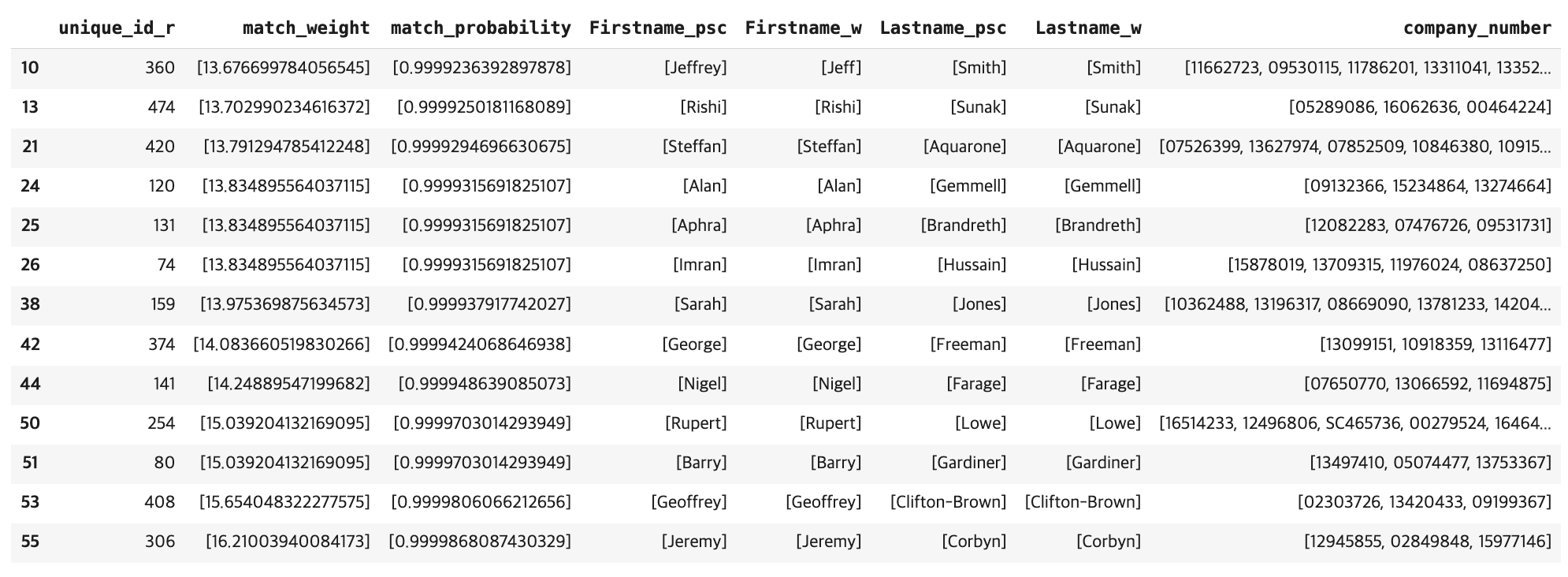
5️⃣ Measuring Performance
79개의 유사 매칭 중에서 실제로 진짜 매칭되는 것과 그렇지 않은 것을 구분하기 어렵기 때문에(교안에서는 가정을 통해서 Precision을 계산함) 이 부분은 실습에서 건너뛰도록 하겠다.
.
.
.
이 챕터에서는 확률론적 프레임워크에서 approzimate matching을 통해 두 데이터셋 간 이름이나 정보가 완전히 일치하지 않아도 유사도 기반으로 비교하며, 특히 Blocking을 통해 비교해야 하는 레코드 쌍을 줄였다. 또한 데이터 정제 과정이 entity resolution에서 얼마나 중요한지를 확인하고 이 작업이 반복적으로 이루어져야 한다는 것을 확인하였다.
