
- 스터디 책: Hands-On Entity Resolution
- 깃헙: https://github.com/mshearer0/HandsOnEntityResolution
- 실습 코랩 코드: https://colab.research.google.com/drive/1QlMTN6A2zLla32241AdOxlJux2tkk8HR?usp=sharing
Chapter5에서는 대규모 데이터셋에서 이름과 생년월일 기준으로 매칭하는 실습을 진행했다. 본 챕터에서는 회사의 주소 정보를 활용하여 일치하는 항목들을 식별하는 작업을 수행한다.
사용하는 데이터셋은 'Companies House register'의 영국의 회사들의 기본정보가 담긴 데이터와 해안경비청(UK Maritime and Coastguard Agency; MCA)에서 발행한 회사 이름 목록이다.
1️⃣ Data Acquisition & Standarization
데이터 수집은 이전 장에서 진행한 방식과 똑같다. MCA 데이터셋은 교안의 코드 그대로 실행하면 에러가 발생해서 try-except 구문을 추가해서 해결했다.
정제해야 하는 컬럼은 회사명, 주소 컬럼인데, 주소의 표기 방식은 굉장히 다양하므로 전처리가 까다롭다는 특징이 있다.

예를 들어, 위 테이블은 MCA 데이터의 일부인데, 각각의 구성요소의 개수(,로 구분된)가 다르며, 첫번째 혹은 두번째 요소는 건물정보가, 마지막 요소는 우편번호로 구성되어 있음을 알 수 있다. 따라서 이번 실습에서는 명확하게 파악할 수 있는 '우편번호'만 매칭에 사용하고, Chapter11에서 지오코딩이나 보다 정교한 자연어 처리를 다룬다고 한다.
Companies House Basic 데이터의 회사명 끝에는 'Limited', 'Ltd'와 같이 법인 형태가 붙어 있는 상황이다. 이때의 접미사는 일관되지 않아 표준화가 어렵기 때문에 이 부분을 아예 분리해주는 작업이 필요하다. 또한 회사명을 구분하는데 크게 도움되지 않는 불용어(stopwords)를 지정해서 이들을 미리 제거할 필요가 있다. 아래 함수는 회사명에서 제거할 불용어 리스트와 제거하는 코드이다.
def strip_stopwords(raw_name):
company_stopwords = { 'LIMITED', 'LTD', 'SERVICES', 'COMPANY', 'GROUP', 'PROPERTIES', 'CONSULTING',
'HOLDINGS', 'UK', 'TRADING', 'LTD.', 'PLC','LLP' }
name_without_stopwords = []
stopwords = []
for raw_name_part in raw_name.split():
if raw_name_part in company_stopwords:
stopwords.append(raw_name_part)
else:
name_without_stopwords.append(raw_name_part)
return(' '.join(name_without_stopwords), ' '.join(stopwords))MCA 데이터에서는 'Address' 컬럼에서 우편번호를 추출해야 한다. 아래 함수의 정규표현식을 통해서 Posecode를 추출하고, 컬럼명 변경이나 null 제거 등의 기타 기본적인 전처리를 진행한다.
def extract_postcode(address):
pattern = re.compile(r'([A-Z]{1,2}[0-9][A-Z0-9]? [0-9][ABD-HJLNP-UW-Z]{2})')
postcode = pattern.search(address)
if(postcode is not None):
return postcode.group()
else:
return Noner'([A-Z]{1,2}[0-9][A-Z0-9]? [0-9][ABD-HJLNP-UW-Z]{2})' 이 정규표현식의 의미는 우선 앞 부분에는 대문자 알파벳 2개 이하와 숫자 1개, 대문자 알파셋 또는 숫자가 1개 이하로 사용된 패턴을 추출하는 것이다. 예를 들어 SW1A나 CF14 등이 추출된다. 이후 공백으로 분리된 뒤 숫자1개 이하와 특정 대문자 알파벳 2개가 나오는 형태이다. 최종 형태는 'BT67 0SY', 'NG7 6BB' 등과 같다.
전처리를 마친 최종 데이터는 df_c가 560284행, df_m이 114행이다.
2️⃣ Record Blocking and Attribute Comparison
이제 Splink 패키지를 활용해서 blocking과 매칭 작업을 수행한다. 매칭에 활용하는 컬럼은 'Postcode'와 'CompanyName'이며, blocking_rules를 추가해서 비교 후보군을 줄인다. 이후 CompanyName을 jaro_winkler의 threshold가 0.8이하, 0.8과 0.9 사이, 0.9 이상, 1(exact match)의 구간으로 나눠서 비교하고, Stopwords도 0.9의 유사도 기준으로 측정한다.
from splink.duckdb.linker import DuckDBLinker
from splink.duckdb import comparison_library as cl
settings = {
"link_type": "link_only",
"blocking_rules_to_generate_predictions": [
"l.Postcode = r.Postcode",
"l.CompanyName = r.CompanyName",
],
"comparisons": [
cl.jaro_winkler_at_thresholds("CompanyName",[0.9,0.8]),
cl.jaro_winkler_at_thresholds("Stopwords",[0.9]),
],
"retain_intermediate_calculation_columns" : True,
"retain_matching_columns" : True
}
linker = DuckDBLinker([df_m, df_c], settings, input_table_aliases=["_m", "_c"])
시각화를 통해 확인해보면, Postcode가 같은 경우는 많고, CompanyName가 같은 경우는 매우 적다.
linker.estimate_parameters_using_expectation_maximisation("l.Postcode = r.Postcode")EM 알고리즘으로 추정할 때에는 PostCode만 기준으로 사용해서 진행한다. 그 결과 iteration을 12번 진행한 뒤 수렴된다.
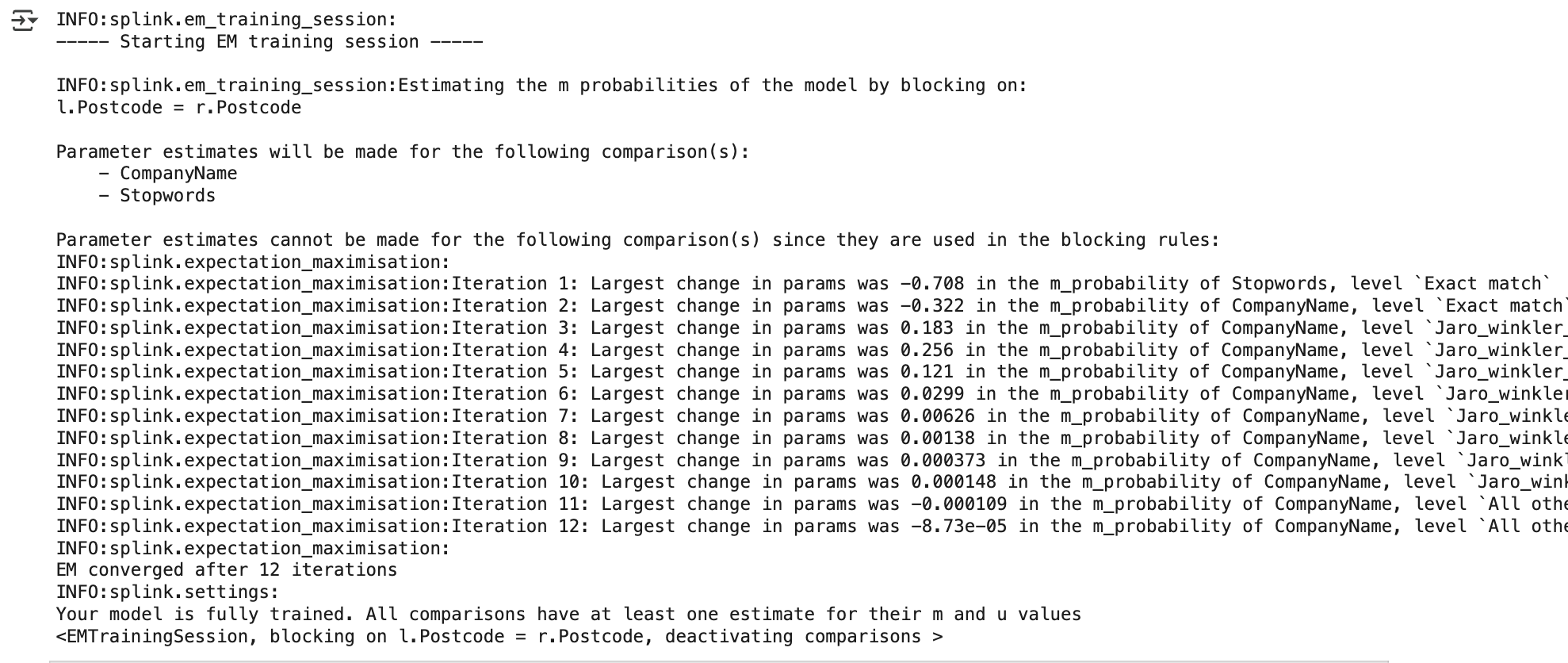
가중치 파라미터 시각화를 보면, CompanyName이 같은 경우는 드물기 때문에 가중치를 크게 준다.
3️⃣ Match Classification
이제 Splink를 사용해서 실제로 매칭을 수행할 때, 가능한 많은 잠재적 매칭을 찾기 위해 threshold를 0.05로 매우 낮게 설정한다. 그 결과 61개의 행이 도출된다.
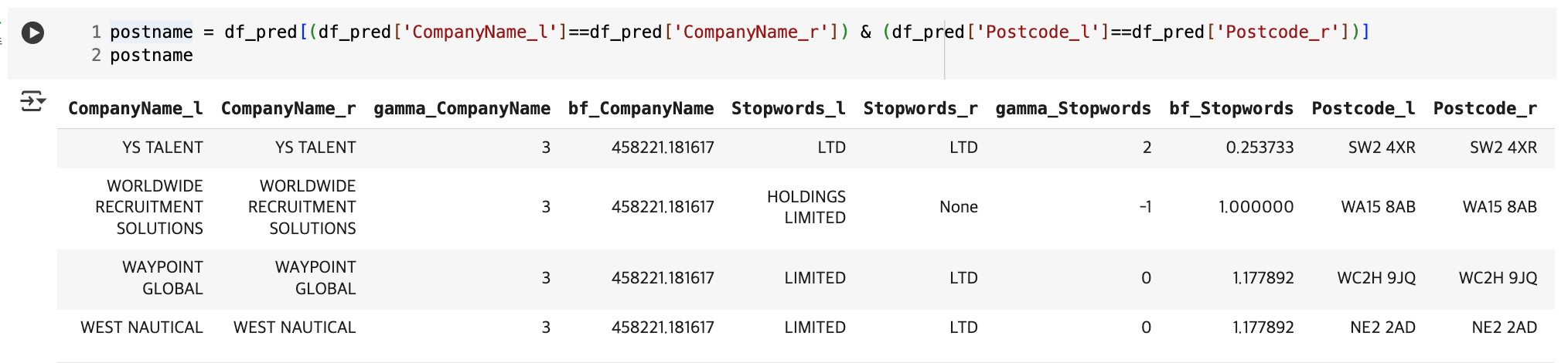
이 중에서 CompanyName이 같으면서 PostCode가 같은 행은 4개 행이며, 아래와 같이 unique_id를 기준으로 df_m에 join을 했을 때 매칭되지 않은 행만 남기면 100개의 행이 도출된다.
results = df_m.merge(df_pred,left_on=['unique_id'], right_on=['unique_id_r'],how='left',
suffixes=('_m', '_p'))
results[results['match_weight'].isnull()]매칭되지 않은 행들을 보면 unique_id_r이 전부 NaN인데, 이는 MCA의 어떤 레코드에 대해서도 Splink가 매칭되는 쌍을 찾지 못했다는 것을 의미한다.
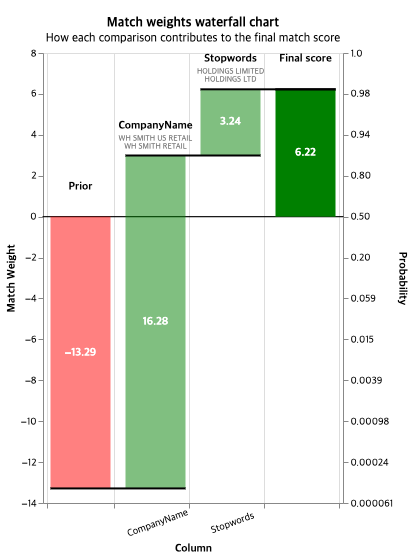
예측 결과에 대해 속성별로 매칭 점수가 어떻게 누적되었는지를 나타내는 Waterfall Chart를 봤을 때, prior 점수는 -13.29로 기본적으로 매칭될 확률이 낮다는 것을 알 수 있다. 또한 회사명이 'WH SMITH US RETAIL'와 'WH SMITH RETAIL'와 같이 유사하면 높은 가중치를 부여받고 Stopwords의 점수까지 더ㅗ해서 최종 점수는 6.22가 된다. 왼쪽 확률을 보면 약 98%의 확률로 매칭된다는 것을 알 수 있다.
4️⃣ Matching New Entities
만약 새로운 레코드가 생겼을 때 기존의 Splink 모델을 다시 훈련하지 않고도 매칭할 수 있는 방법에 대해서 설명한다. find_matches_to_new_records는 새로운 레코드에 대해 매칭 후보군을 찾아주는 모듈이고, match_weight_threshold=0은 가중치의 제한을 두지 않고 가능한 모든 후보를 반환한다는 의미이다.
record = {
'unique_id': 1,
'Postcode': "BH15 4QE",
'CompanyName': "VANTAGE YACHT RECRUITMENT",
'Stopwords' : ""
}
df_new = linker.find_matches_to_new_records([record], match_weight_threshold=0).as_pandas_dataframe()
df_new.sort_values("match_weight", ascending=False)그 결과 다음 3개의 행이 출력되었는데, 이 후보들은 CompanyName과 PostCode가 완전히 일치하진 않지만 근접한 후보들이라는 것을 알 수 있다. 블로킹을 했을 때는 필터링 되었겠지만, 수동으로 매칭한다면 매칭될 가능성이 충분히 있다는 것을 알 수 있다.

