
- 스터디 책: Hands-On Entity Resolution
- 깃헙: https://github.com/mshearer0/HandsOnEntityResolution
- 실습 코랩 코드: https://colab.research.google.com/drive/1CUtLQHb-RJtsaejtBbzxb_yObMLmJ2w5#scrollTo=izk0SWbS-tXr
지금까지 서로 다른 두 데이터를 활용하여 entity resolution을 진행했으며, 기준 데이터(e.g. 이전에 사용한 국회의원 데이터)에는 동일한 개체가 없다는 것을 가정했다. 그러나 현실 세계의 데이터를 보면, 동일한 개체는 여러 형태로 표현될 수 있다. 예를 들어 'Geoffrey Clifton Brown'은 09193367 이라는 고유한 숫자(주민등록번호 등) 혹은 아이디로도 구분될 수 있다. 또한 이전 장의 실습에서 진행했듯, 위키피디아와 PSC의 인물이 1:3관계로 매칭되었을 때, 실제로 PSC 데이터의 세명의 인물은 같은 인물일 가능성이 있다. 아래 그림과 같이 이러한 완계는 Node와 Edge로 표현되며, 하나의 Cluster로 나타낼 수 있다. 따라서 Chapter7에서는 이러한 클러스터를 어떻게 만들 수 있는 지에 대한 방법을 알아본다.
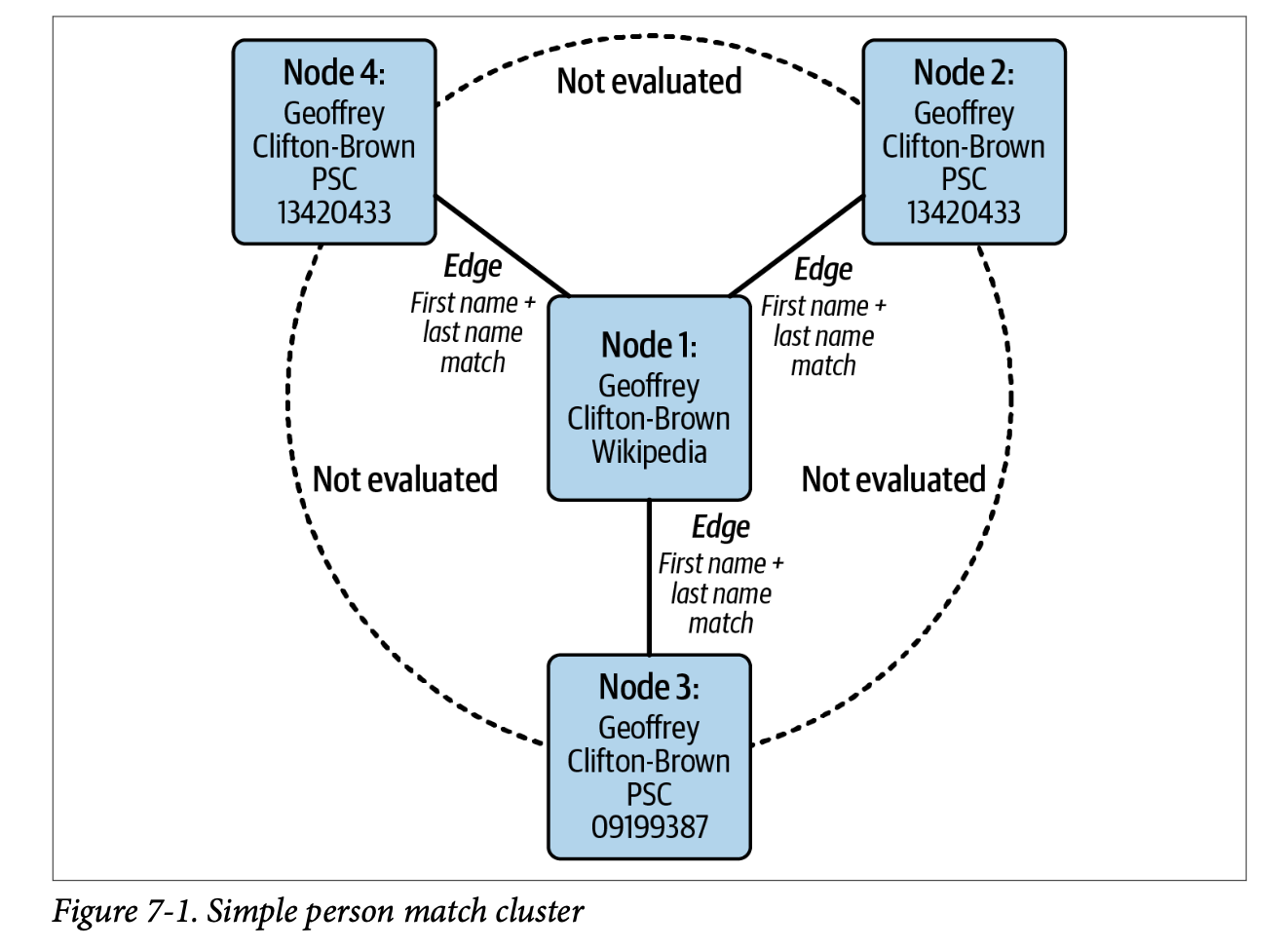
Simple Exact Match Clustering
우선, 완전히 일치하는 개체만 동일한 그룹으로 클러스터링 하는 방법에 대해서 간단하게 알아본다. 아래와 같이 이름, 성, 생년월일만 있는 작은 데이터에서 이름과 성을 기준으로 groupby를 하면 아래 테이블과 같이 묶이게 된다.
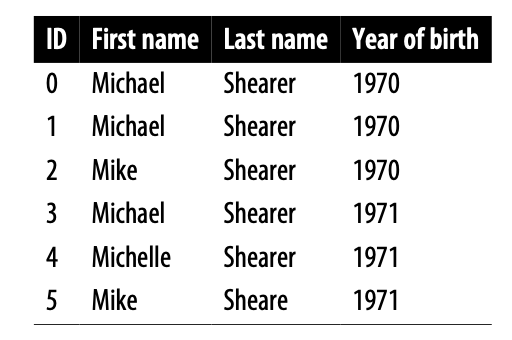
df_ms['cluster'] =
df_ms.groupby(['Firstname','Lastname']).ngroup()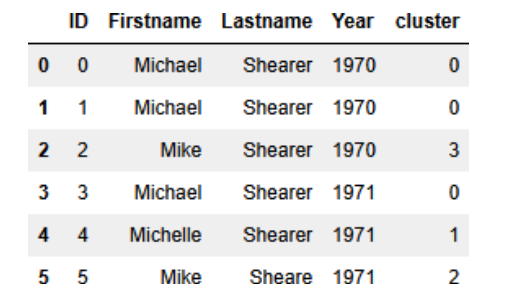
단순하게, Michael Shearer 이라는 이름이 같은 경우 0 클러스터로 묶인 것을 확인할 수 있다. feature에 Year까지 줬다면 ID 0, 1만 같은 클러스터로 묶였을 것이다.
Approximate Match Clustering
다음은 확률론적인 이름 매칭(Chapter3에서 했었던)을 활용한 클러스터링이다. 우선, 1:1 매칭으로 비교할 수 있도록 비교쌍을 아래와 같이 생성한다. 고유한 index를 가진 6개의 개체의 비교쌍은 15행이 도출된다(순서 중복을 제외하므로 n*(n-1)/2로 계산).
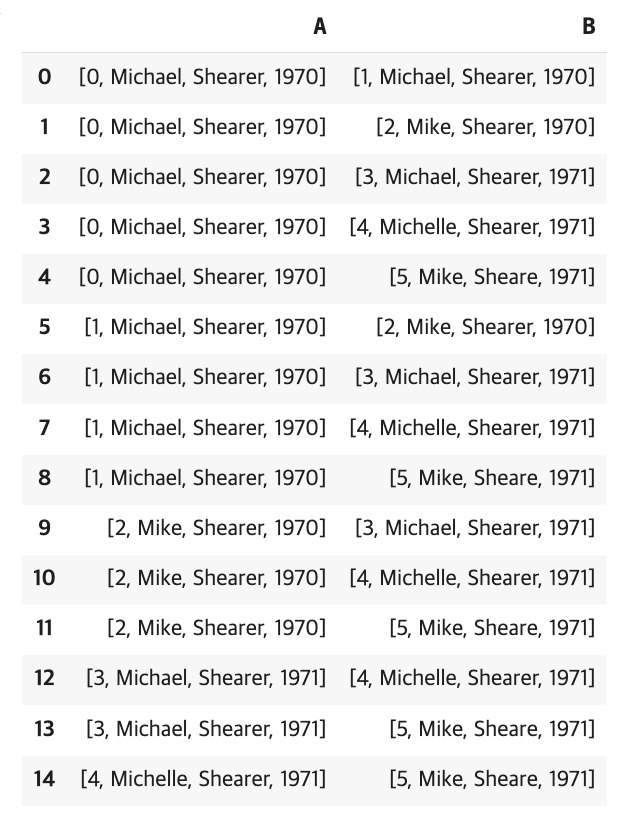
이후 리스트로 되어 있는 값들을 각각의 컬럼의 값으로 들어갈 수 있도록 전처리해준 뒤, 해당 테이블을 아래 is_match 함수를 통해서 매칭한다. 이 함수는 firstname과 lastname을 jaro_wrinkler 유사도를 통해 0.9 이상의 유사도를 갖는 행만 True로 반환하도록 한다.
import jellyfish as jf
def is_match(row):
firstname_match = jf.jaro_winkler_similarity(row['A']['Firstname'], row['B']['Firstname']) > 0.9
lastname_match = jf.jaro_winkler_similarity(row['A']['Lastname'], row['B']['Lastname']) > 0.9
return firstname_match and lastname_match
df_edges['Match'] = df_edges.apply(is_match, axis=1)
df_edges매칭 결과는 아래 표와 같다. ID0는 ID1, 3, 4와 매칭되고, ID1은 3, 4와, ID2는 5와, ID3은 4와 매칭된다는 것을 알 수 있다.
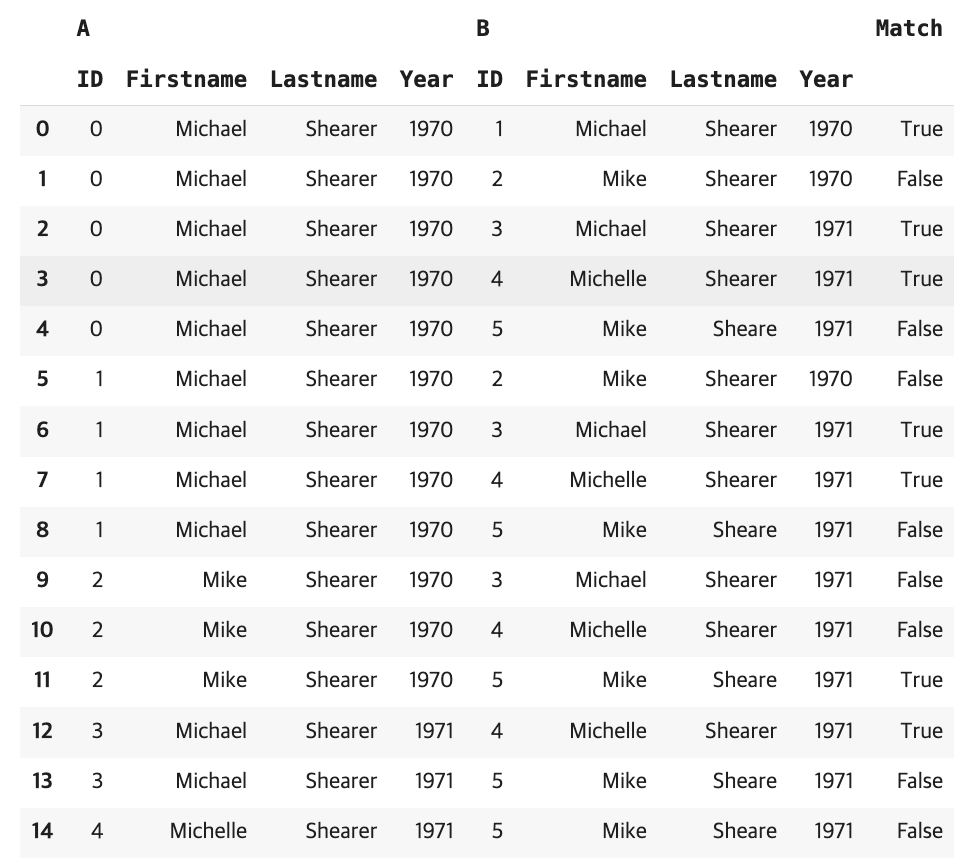
이 결과를 아래 코드와 같이 networkx라는 네트워크 분석을 라이브러리로 매칭 결과를 확인해보면 [{0, 1, 3, 4}, {2, 5}]의 클러스터 두 개를 도출할 수 있다.
import networkx as nx
G = nx.from_pandas_edgelist(df_edges[df_edges['Match']], source=('A','ID'), target=('B','ID'))
list(nx.connected_components(G))한편, 이 클러스터링의 문제는 정확하게 일치하지 않는 데이터까지 하나의 개체로 묶인다는 것이다. 예를 들어, ID 0, 1, 3, 4로 구성된 첫 번째 클러스터에서 firstname이 Michael과 Michelle 두개가 모두 있을 때, 대표 이름을 어떤 것으로 정해야 할지 선택해야 한다. 출생연도나 lastname도 마찬가지 문제가 있다. 이렇게 클러스터를 대표하는 가장 적절한 값을 선택하는 작업을 canonicalization이라고 하며, 이 분야는 활발하게 연구되고 있고 이 책에서는 깊게 다루지 않는다고 한다.
또한, 계산량과 trade-off 문제도 존재하는데, 레코드 수가 늘어날 경우 쌍별 비교 횟수가 급격하게 증가한다. 속성값이 충돌하는 문제는 가장 어려운 문제인데, 클러스터 내의 개별 개체들이 서로 다른 속성값을 가질 때, 클로스터를 정의할 단일 속성값 집합을 어떻게 결정할 것인가에 대한 문제이다.
Sample Problem
이제 더 큰 규모의 실제 데이터를 활용해서 클러스터링을 다시 진행해본다.
1️⃣ Data Acquisition
데이터는 Chapter5에서 사용한 기업의 중요한 결정을 하는 사람에 대한 데이터(PSC; Person of Significant Control)를 계속 사용한다.
2️⃣ Data Standardization
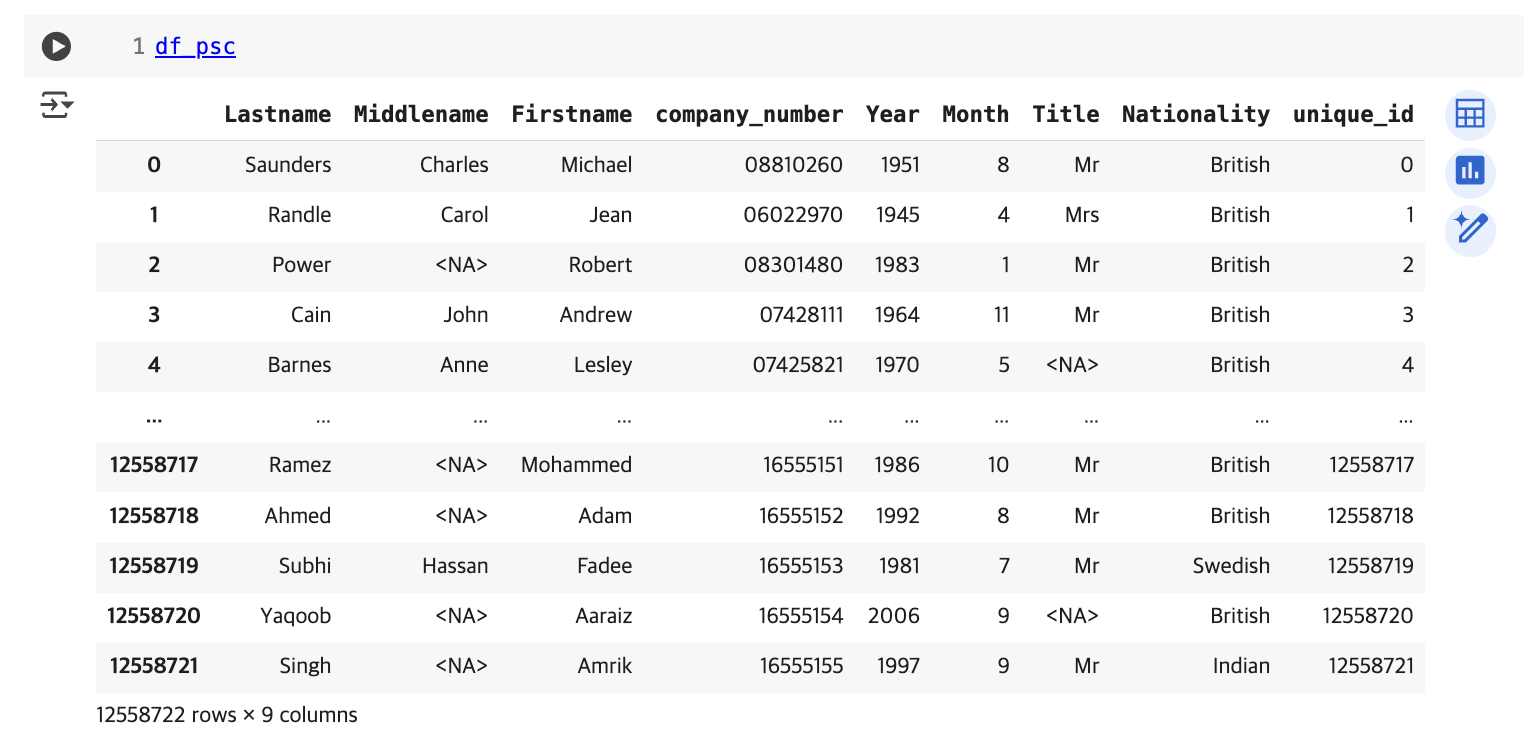
데이터 전처리 과정에서는 타입을 맞춰주고, 컬럼며명을 rename하며, index를 기준으로 unique_id 컬럼을 추가하는 작업을 진행한다.
최종 전처리를 마친 데이터는 다음과 같다.
3️⃣ Record Blocking and Attribute Comparison
from splink.duckdb.linker import DuckDBLinker
from splink.duckdb import comparison_library as cl
settings = {
"link_type": "dedupe_only",
"blocking_rules_to_generate_predictions": [
"l.Year = r.Year and l.Month = r.Month and l.Lastname = r.Lastname"
],
"comparisons": [
cl.jaro_winkler_at_thresholds("Firstname", [0.9]),
cl.jaro_winkler_at_thresholds("Middlename", [0.9]),
cl.exact_match("Lastname"),
cl.exact_match("Title"),
cl.exact_match("Nationality"),
cl.exact_match("Month"),
cl.exact_match("Year", term_frequency_adjustments=True),
],
"retain_matching_columns": True,
"retain_intermediate_calculation_columns": True,
"max_iterations": 10,
"em_convergence": 0.01,
"additional_columns_to_retain": ["company_number"],
}
linker = DuckDBLinker(df_psc, settings)이전과 마찬가지로, Splink 프레임워크를 사용하여 매칭을 하며, 확률적 예측과 exact 매칭 두 가지를 비교 방법으로 사용한다. 즉, 위와 같이 Lastname, Year와 Month가 정확히 같은 경우만 비교 대상으로 삼고, 나머지는 jaro_winkler 혹은 exact match로 비교하겠다는 것이다. 이러한 방식을 trade-off라고 설명하는데, lastname이 반드시 같은 경우만 비교한다는 점에서 효율을 높아지지만, 일부 오타나 표기 방식의 차이가 있는 경우를 놓칠 가능성도 높아지기 때문이다.
또한, link_type을 단일 데이터셋 내 중복 제거를 위해 dedupe_only로 주고, 수렴하는 값을 찾기 위한 최대 반복수 max_iterations를 10으로 설명하며, 수렴하지 않더라도 이전 단계와 비교했을 때 변화량이 0.01(1%) 미만이면 멈출 수 있도록 em_convergence를 설정한다.
4️⃣ Data Analysis
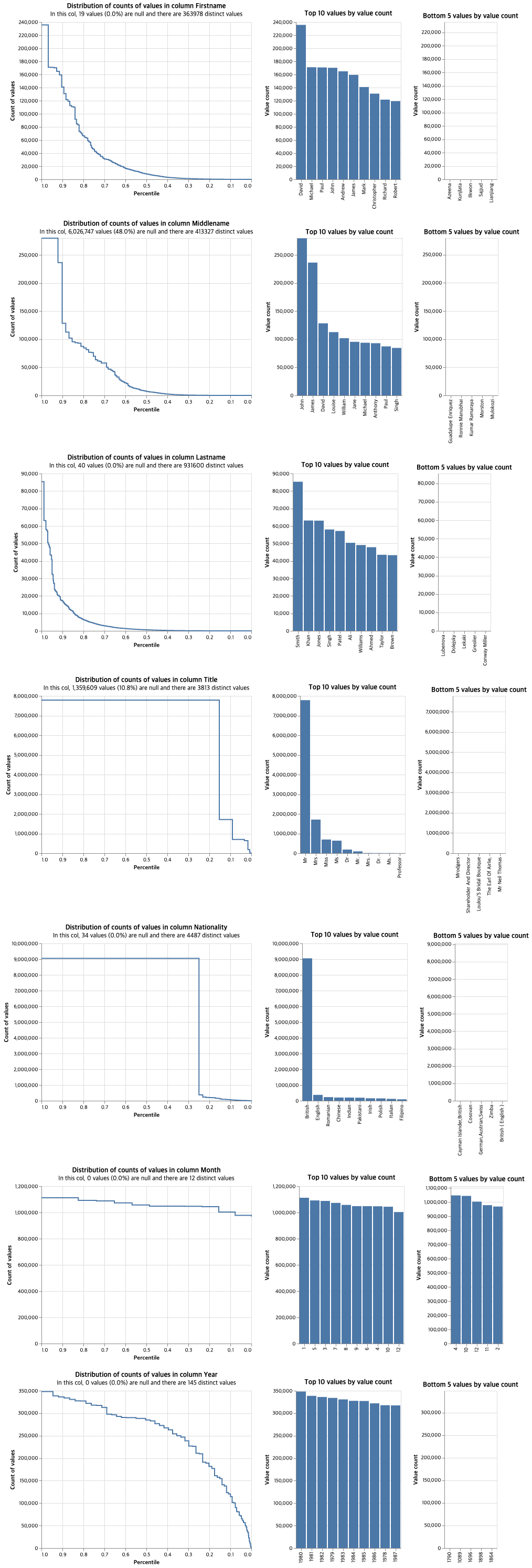
컬럼별 분포를 확인했을 때, firstname, middle, lastname은 모두 롱테일 분포를 보이고, Title과 nationality는 특정 값(Mr, Britsh)에 굉장히 치우친 분포를 보인다. Yearsms 1980년대가 우세하게 나타났다.
5️⃣ Expectation-Maximization Blocking Rules

이제 블로킹을 하기 위해서 몇가지 조합들을 테스트 해본다. 조건을 까다롭게 줄수록 매칭되는 행의 수가 적어진다. 위에서 언급했듯, 계산 효율과 최종 성능은 trade-off 관계이기 때문에 적절한 값을 잘 찾아야 한다. 이 과정은 다소 휴리스틱하게 진행되는 것 같다.
참고로, 교안에서도 언급되지만 블로킹을 할 때는 반드시 비교할 수 있는 속성을 남겨줘야 m(두 레코드가 실제 동일할 때 해당 속성 조건이 일치할 확률), u(두 레코드가 동일할 때 해당 속성 조건이 일치할 확률) 값을 계산할 수 있다.
linker.estimate_parameters_using_expectation_maximisation("l.Firstname = r.Firstname and l.Month = r.Month and l.Year = r.Year and l.Title = r.Title and l.Nationality = r.Nationality", fix_u_probabilities=False)sample 1000만개 행을 통해 u value를 계산하고 estimate_parameters를 수행한다. 다만 데이터의 양이 많은 만큼 코랩 무료 버전에서는 out of resource로 코드가 실행되지 않았고, 이후 내용은 교안의 설명을 기반으로 작성하였다.
6️⃣ Match Classification and Clustering
clusters = linker.cluster_pairwise_predictions_at_threshold(df_predict, threshold_match_probability=0.9)
df_clusters = clusters.as_pandas_dataframe()Splink에서 제공하는 cluster_pairwise_predictions_at_threshold 매서드를 활용해서 threshold를 0.9로 설정하고 클러스터링을 진행한다.
df_cselect = df_cgroup[(df_cgroup['Firstname'].apply(len) > 1) &
(df_cgroup['Title'].apply(len) > 1) &
(df_cgroup['Nationality'].apply(len) > 1) &
(df_cgroup['company_number'].apply(len) == 6)]cluster_id라는 컬럼이 생기고, 개별 클러스터의 아이디가 각 개체별로 부여된 테이블에서 다시 유효한 행만 필터링한다. firstname, title, nationality의 길이가 1보다 큰 경우와 company_number가 반드시 6글자인 행만 추린다.
7️⃣ Cluster Visualization
이제 클러스터링한 결과를 기반으로 간단한 시각화를 진행한다. PSC 데이터로 동일한 인물로 클러스터링 했을 때 확인할 수 있는 정보는, 개별 클러스터에 포함된 회사의 수를 통해 '영국 기업에 대한 지배력은 얼마나 집중되어 있는가?'에 대한 결과를 알 수 있다.
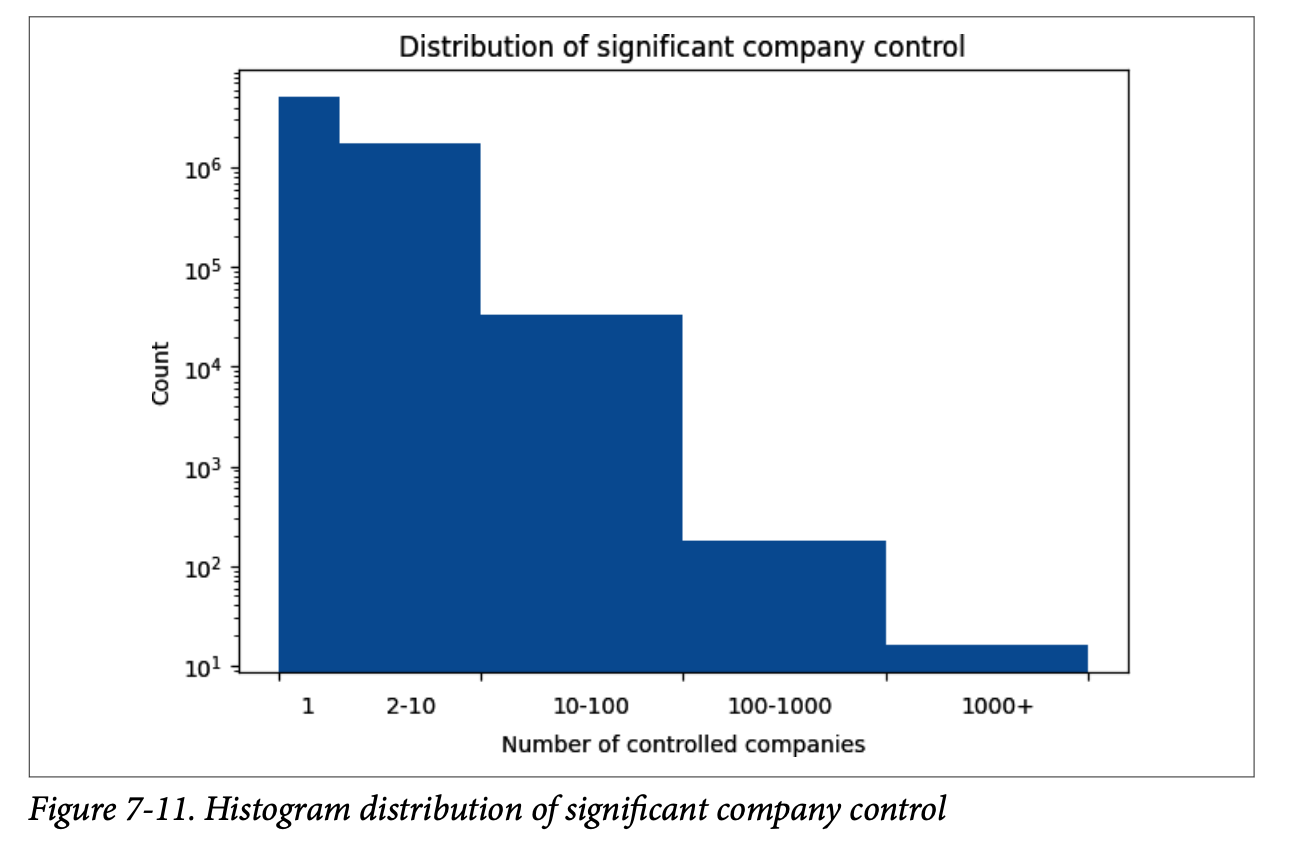
위 histogram 결과를 보면, 대부분 하나의 회사에 속해있고, 그 다음으로는 2~10개의 회사를, 그리고 아주 소수는 10개 이상의 회사에 속해있었다. 극소수이지만, 데이터상으로는 1000개가 넘는 회사에 영향력을 미치는 개인도 존재하는 것으로 나타났는데, 일반적으로 이럴 가능성이 매우 낮기 때문에 클러스터링 결과를 의심해볼 수 있다.
8️⃣ Cluster Analysis
Splink에는 cluster studio datshboard 기능이 있는데, 이를 통해서 동적으로 클러스터링 결과를 확인할 수 있다고 한다. 코랩으로는 앞서 linker 부분 실행이 안됐기 때문에(제공하는 json을 활용한 predict도 안됐음) 직접 테스트 해보진 못했다.
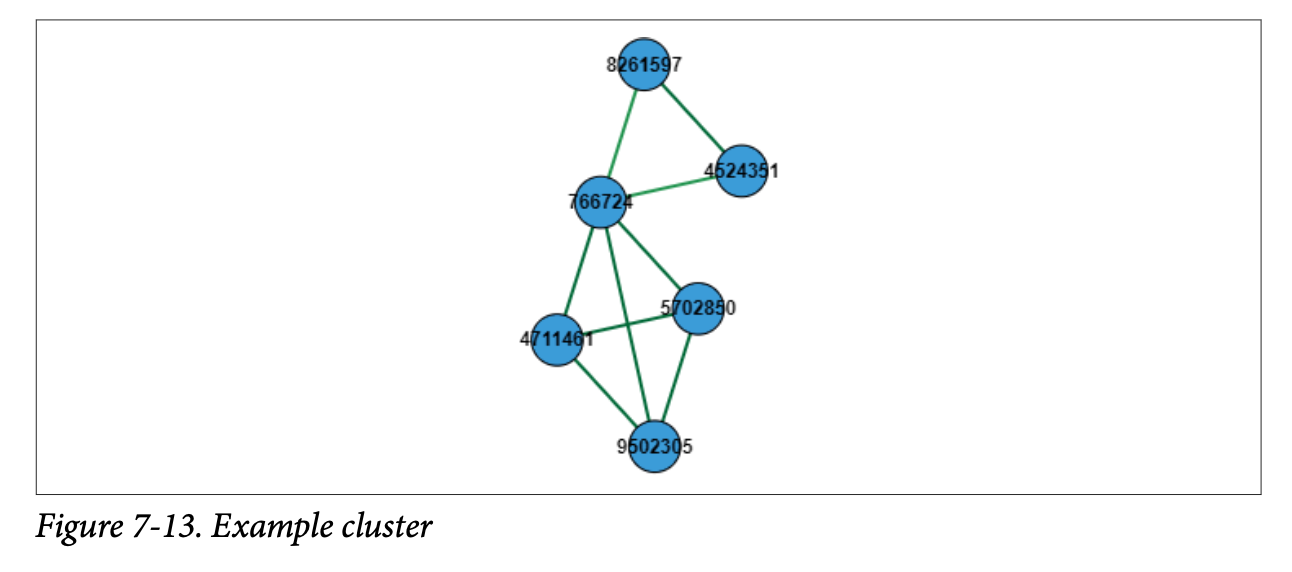
개별 클러스터의 시각화 결과를 보면, 하나의 클러스터로 묶인 경우에도 모든 노드가 다 연결된 것은 아니다. 또한 threshold를 조정했을 때, 만약 임계값을 높인 다면(조건을 더 까다롭게), 가장 약하게 연결되어 있던 node는 해당 클러스터에서 제외된다.
외부 데이터인 회사의 주소 데이터를 추가적으로 검토했을 때, 서로 다른 회사이지만, 동일한 주소로 표기된 경우가 많았다고 한다. 이런 경우의 회사가 하나의 클러스터로 묶였다면, 이는 사실 한 사람이 운영하는 동일한 위치의 회사이지만, 회사 등록은 서로 다르게 되어 고유 ID가 상이한 경우라고 해석할 수 있다.
.
.
.
현실 세계에서 entity resolution은 완벽하게 수행하기 어렵다. 클러스터링을 진행한다고 해도, threshold를 조정하면서 최적의 상태를 찾아야 하고, 이후 canonicalization을 통해 대표값을 정해야 하는 과정이 남는다. 결국, 이런 작업들은 유일한 정답은 없기 때문에 최적의 임계값을 휴리스틱하고 반복적으로 찾으면서 분석을 수행해야 한다는 결론을 끝으로 이번 챕터는 마무리된다.
