
- 스터디 책: Hands-On Entity Resolution
- 깃헙: https://github.com/mshearer0/HandsOnEntityResolution
이번 챕터에서는 큰 사이즈의 entity resolution을 합리적인 시간 내에 처리할 수 있는 방법을 다룬다. 이를 위해 구글 클라우드 플랫폼(GCP에서 여러 가상 머신(virtual machine)으로 구성된 클러스터를 병렬로 실행하여, 전체 작업량을 분산시키고 처리 시간을 단축시킨다고 한다.
Google Cloud Setup
우선, 구글 클라우드 세팅 방법을 차례로 설명한다. 이 부분은 간단하게만 설명하겠다.
- GCP 사이트 접속 후 가입
- 교안에서는 계속 요금 부과와 관련된 경고를 하고 있다. 필자는 이전에 사용한 적이 있어서 90일 무료 free trial에 해당되지 않는 것 같지만, 처음 사용자는 사용할 수도 있으니 잘 찾아봐야 한다.
- Project Storage 세팅
- 가입 후 콘솔에 들어가서 '프로젝트 만들기 또는 선택' 버튼을 누르면 된다. 이후 프로젝트 이름을 설정하면 끝이다.
- 가입 후 콘솔에 들어가서 '프로젝트 만들기 또는 선택' 버튼을 누르면 된다. 이후 프로젝트 이름을 설정하면 끝이다.
- Bucket 설정하기
- Cloud Storage에서는 데이터를 담는 특정 컨테이너를 버킷(bucket)이라고 한다. 버킷은 전역적으로 고유한 이름을 갖고, 저장될 지리적 위치를 정해야 한다고 한다.
- Cloud Storage>버킷 으로 들어가서 고유한 이름을 지정해서 새 버킷을 생성했다. 위치는 옆에 있는 링크로 들어가서 가격을 확인해보니 북미로 지정하는게 더 싼거 같아서 미국의 멀티 리전으로 설정했다. 버킷의 물리적인 위치를 의미하니 큰 상관은 없을 것 같다.
Creating a Dataproc Cluster
이전에 매칭 작업을 진행할 때 썼던 Splink를 계속 사용하는데, 이번에는 백엔드 엔진으로 DuckDB가 아닌 Spark를 사용한다. GCP에서 Spark를 사용하는 간단한 방법은 'Dataproc cluster'를 사용하는 것이며, 우선 API를 발급받아야 한다. 아래와 같이 Dataproc 탭으로 접속해서 ENABLES API를 클릭해서 API를 발급받는다.
API를 활성화한 후, Create Cluster를 클릭하여 Dataproc 인스턴스 설정을 시작한다. 클러스터는 일반적인 가상 머신을 기반으로 하는 방법과 Google Kubernetes Engines를 기반으로 하는 방식이 있는데, 실습을 할 때는 이 둘이 큰 차이가 없으므로 더 간단한 Compute Engine virtual machines을 사용한다. 이때 아래 부분에서 구성요소를 선택하는 부분에서 Jupyter Notebook을 반드시 선택해야 한다.
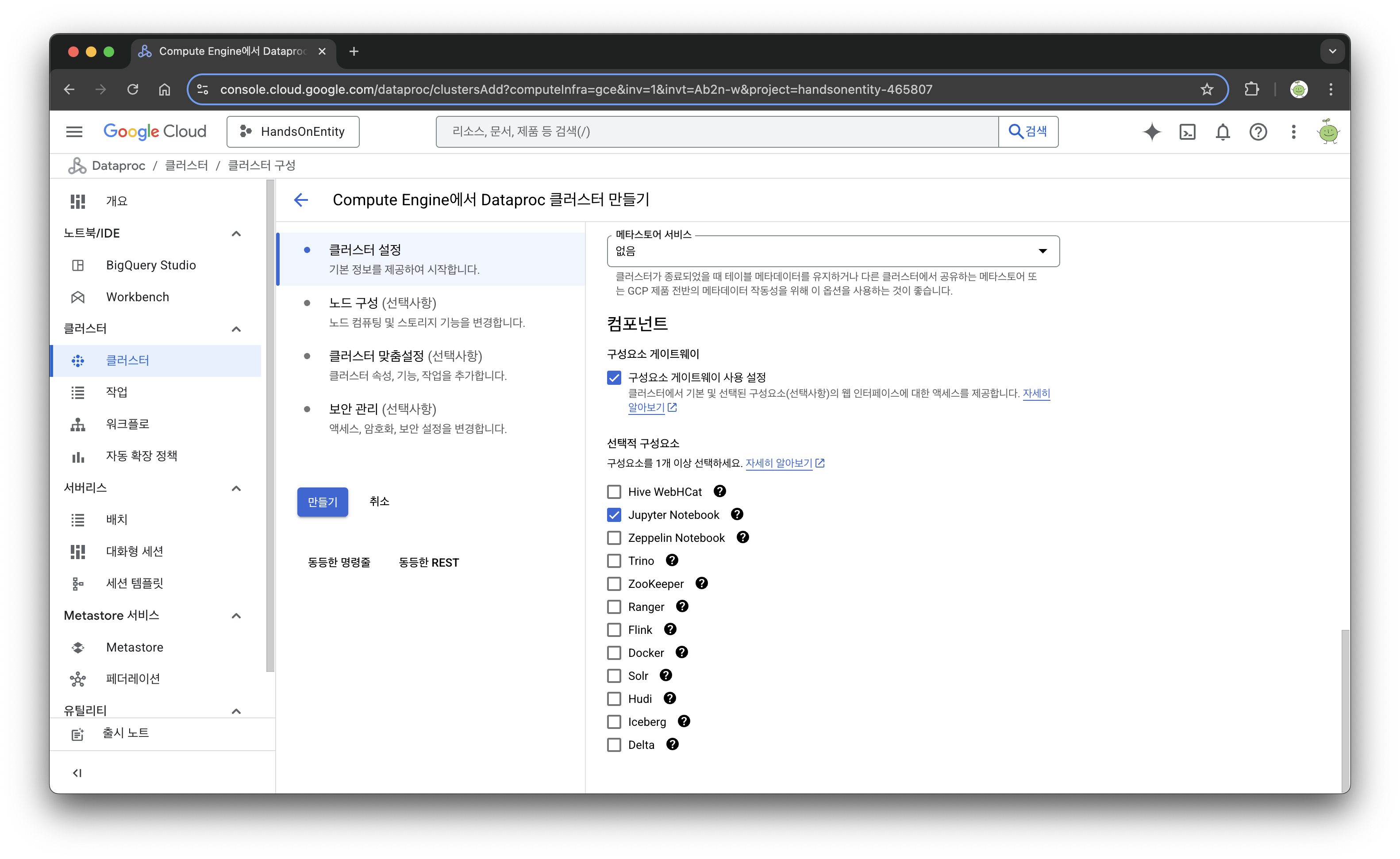
이후 '노드 구성' 탭에서 worker가 2로 설정되어 있는걸 확인하고,
'클러스터 맞춤설정' 탭에서는 '예약된 삭제' 부분에서 자동으로 클러스터를 삭제하도록 만들어서 실수로 지우지 않았을 때도 과금이 되지 않도록 한다.
Configuring a Dataproc Cluster
이 부분에서는 Dataproc 클러스터를 실행하고 분석을 위한 환경 설정을 하는데, 이를 Jupyter notebook을 기준으로 설명한다. 필자는 지금까지 모든 실습은 Google Colab 기반으로 했으므로, 이 부분도 Colab에서 진행하고자 한다. 이 가이드를 참고했다.
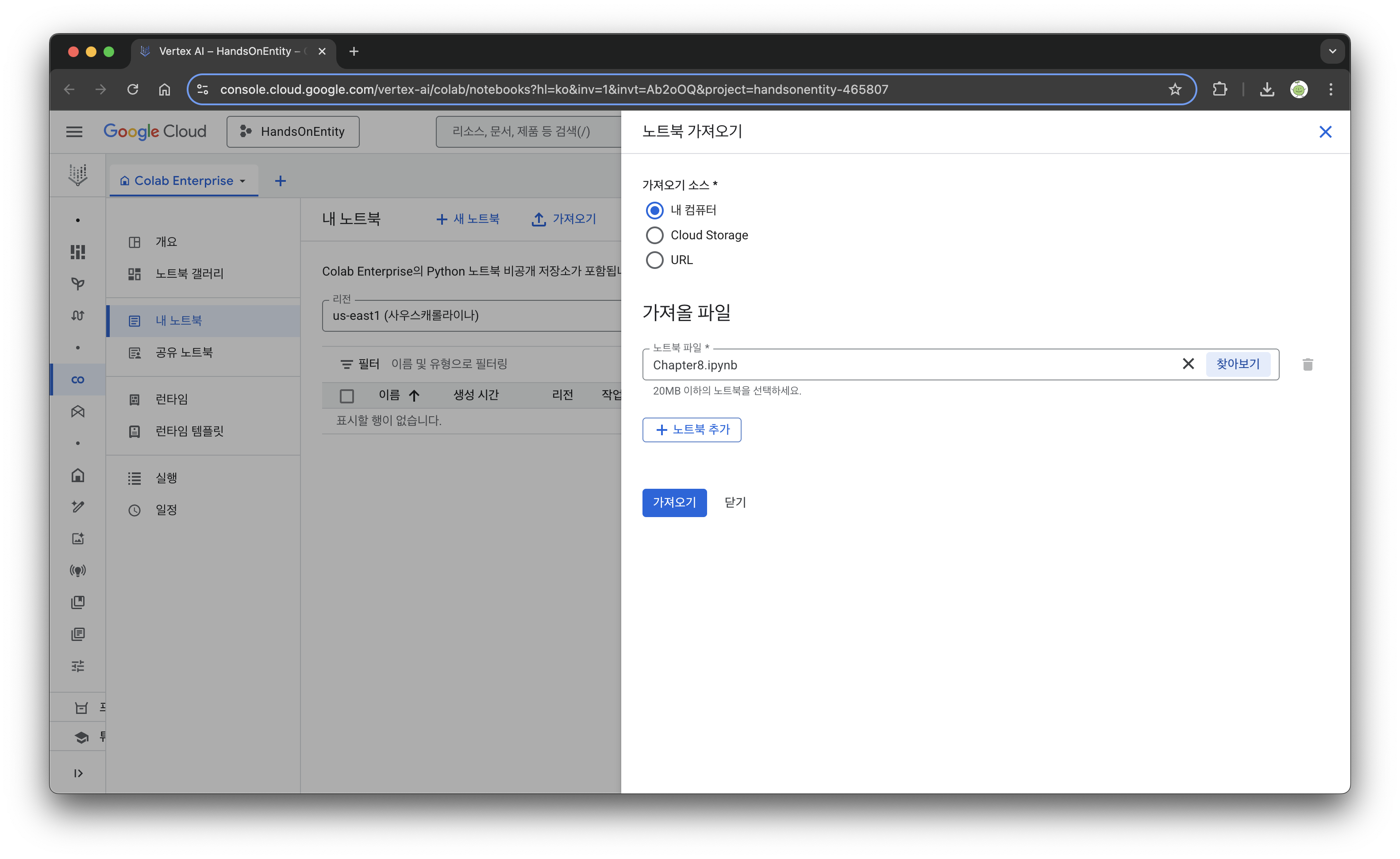
우선 GCP의 Notebook에서 ipynb를 불러온다. VertaxAI(구글의 통합 AI 개발 도구)로 연결되면서 아래와 같이 파일이 열린다.
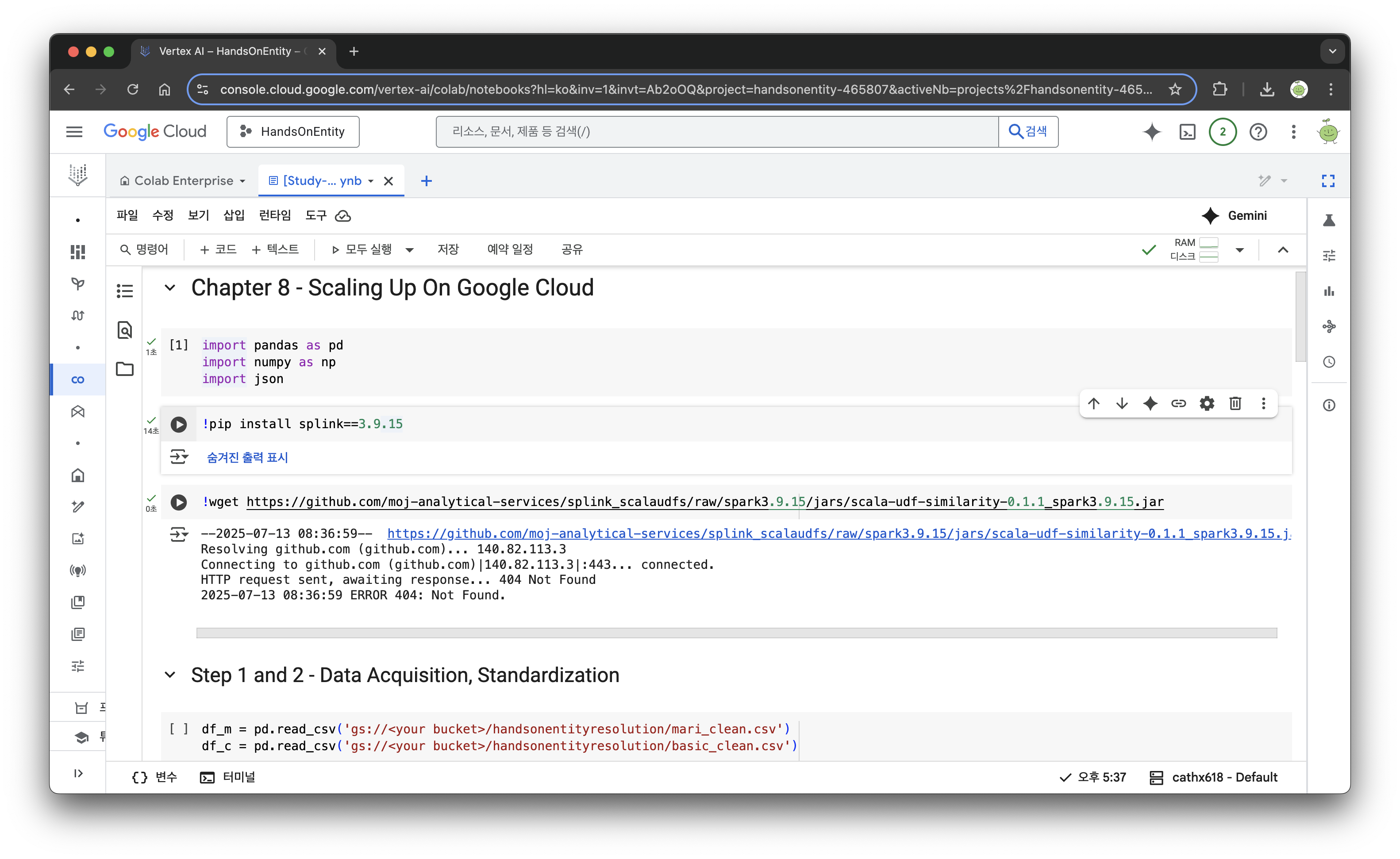
버전을 맞춰서 Splink도 설치하고, Dataproc의 Spark는 DuckDB와 달리 'Jaro-Winkler' 같은 문자열 유사도 비교 함수를 내장하고 있지 않으므로, 이 기능이 포함된 JAR(Java ARchive) 파일을 다운로드해준다. 또한 설치한 jar를 모든 워커 노드가 사용할 수 있도록 Cloud Storage 버킷에 복사해 준다.
!wget https://github.com/moj-analytical-services/splink_scalaudfs/blob/main/jars/scala-udf-similarity-0.1.1_spark3.x.jar교안에 있는 코드로는 에러가 나서 jar 파일이 저장된 레포를 다시 찾아서 위에 코드의 경로를 수정해줬다.
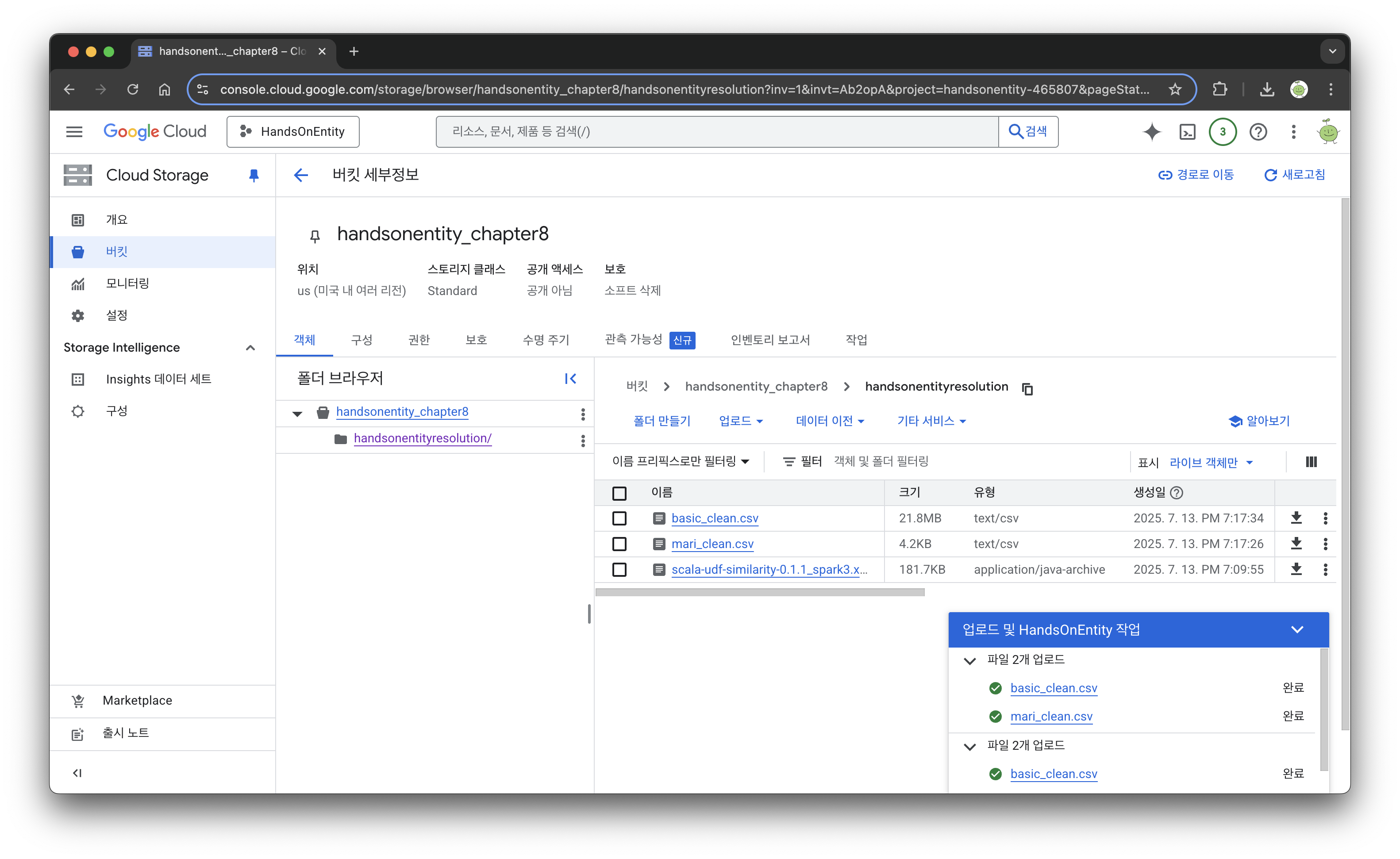
교안에서는 로컬 주피터를 사용하므로 gshutil 명령어로 버킷에 이전에 생성한 파일들을 옮겨주고 있는데, 필자는 이전에 구글 드라이브에 저장했기 때문에 직업 위와 같이 업로드 해줬다.
Entity Resolution on Spark
이제 본격적으로 매칭 작업을 시작하면 되는데, 문제는 이 이후로 코드에러가 계속 발생하고 아직 해결하지 못했다는 거다..
from pyspark import SparkContext, SparkConf
from pyspark.sql import SparkSession
from pyspark.sql import types
conf = SparkConf()
conf.set("spark.default.parallelism", "240")
conf.set("spark.sql.shuffle.partitions", "240")
sc = SparkContext.getOrCreate(conf=conf)
spark = SparkSession(sc)
spark.sparkContext.setCheckpointDir("gs://<your bucket>/
handsonentityresolution/")
spark.udfspark.udf.registerJavaFunction(
"jaro_winkler_similarity",
"uk.gov.moj.dash.linkage.JaroWinklerSimilarity",
types.DoubleType())위 코드는 Splink를 pyspark를 통해서 실행하는 내용인데, 마지막에 spark를 사용해서 jaro_winkler_similarity를 계산하는 부분에서 계속 에러가 발생했다. 위에서 jar 파일을 설치해준 부분에서 문제가 있는거 같은데, 설치 과정에서는 에러가 발생하지 않았기 때문에 영문을 알 수 없었다.
spark에서 jaro_wrinkler를 사용할 수 있도록 하는 라이브러리는 2년 전에 수정되고 업데이트가 안됐는데, 버전 문제도 존재하는 것 같다.
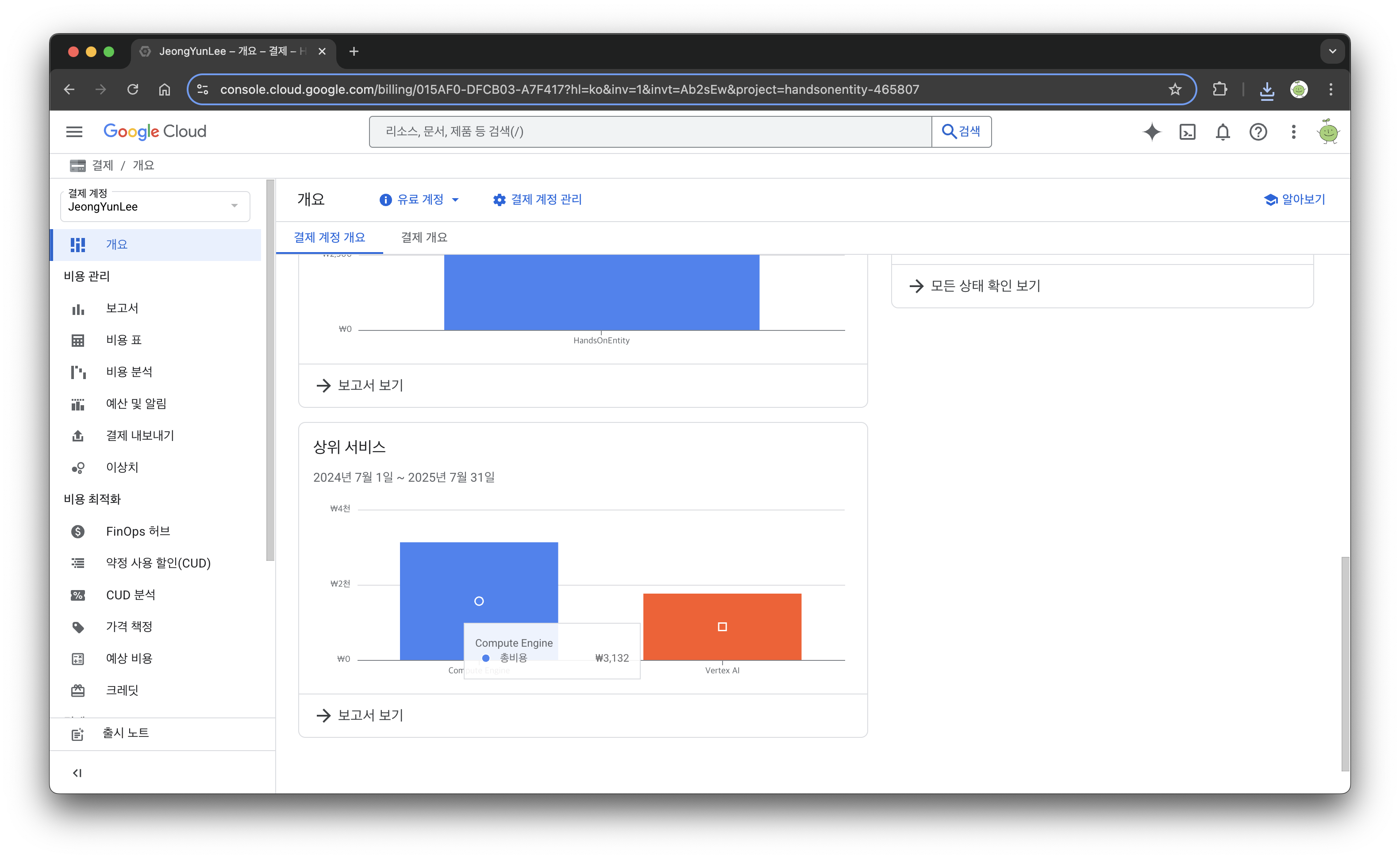
결국 여러가지 테스트만 하고 성공하지 못했는데, 약 하루?도 안되는 시간동안 사용량으로 청구된 비용이 약 4500원 정도... 이래서 교안에서도 계속 과금을 주의하라고 했나보다. 이 프로젝트를 실행만 하고 있어도 계속 요금이 부과 되기 때문에 일단 모든 클러스터, 버킷, 그리고 프로젝트 자체를 삭제해주었다.
.
.
.
교안의 내용을 보니 매칭 방식은 DuckDB로 로컬에서 실행해주는 것과 크게 다르지 않고, pyspark를 사용하여 약간의 코드 차이만 있는 것 같다. 일단 이번 챕터 실습은 이렇게 마무리하는 걸로...
