gpt-4o, claude 3.5 sonnet, Llama3.2 등 최근 대형 모델들은 Multimodal을 지원하는 경우가 많다. 즉, input값에 텍스트 뿐만 아니라 이미지나 문서, 심지어 짧은 영상을 넣고 설명을 해달라거나 관련된 질문을 요청할 수 있다는 것이다.
기존에도 이미지에서 텍스트를 인식하는 다양한 OCR 모델들이 존재했다. 그럼에도 LLM의 OCR을 활용하려는 이유는 단순히 텍스트만 인식하는 것이 아니라 텍스트를 기반으로 이미지에서 객체를 인식하고, 이미지에 대한 설명을 생성할 수 있기 때문이다. 실제로 ChatGPT나 Claude에서 테스트 해보면 꽤 괜찮은 결과를 얻을 수 있다.
이렇게 잘 되는 줄만 알았는데, 최근 진행하던 프로젝트에서 실제로 활용하려고 하니 한계점이 드러났다. ChatGPT 서비스(웹 or 앱)에서는 이미지를 넣고 이미지에 있는 글자를 추출하거나 설명해달라고 요청했을 때, 한글의 인식률이 꽤 높았는데, 이를 API에서 동일하게 실행하니 한글을 제대로 인식하지 못하는 문제가 발생하는 것이다.
예를 들어, '대흥역'이라는 글씨가 적힌 지하철 입구 사진을 넣었을 때 '대방역'이라는 OCR결과를 출력하는 경우가 있었다. 이건 잘못된 인식을 넘어 hallucination까지 발생하는 결과이다.
원인은 여러가지 있을 수 있을 텐데, 우선 OpenAI 자체에서 웹 서비스와 API의 품질을 다르게 제공한다거나(실제로 Reddit이나 OpenAI Developer Forum 등에서 이와 관련된 논의들이 종종 있는 것 같다) 이미지를 처리하는 방식의 차이(품질이 저하되는 등)가 있을 수 있다. 그러나 API에서 여러가지 파라미터를 조정해도 변화가 없고 이미지의 품질도 문제가 없는 것 같다는 것을 확인한 뒤, 단일 모델만 사용한 Object Detection은 어려울 것 같다는 판단을 내렸다.
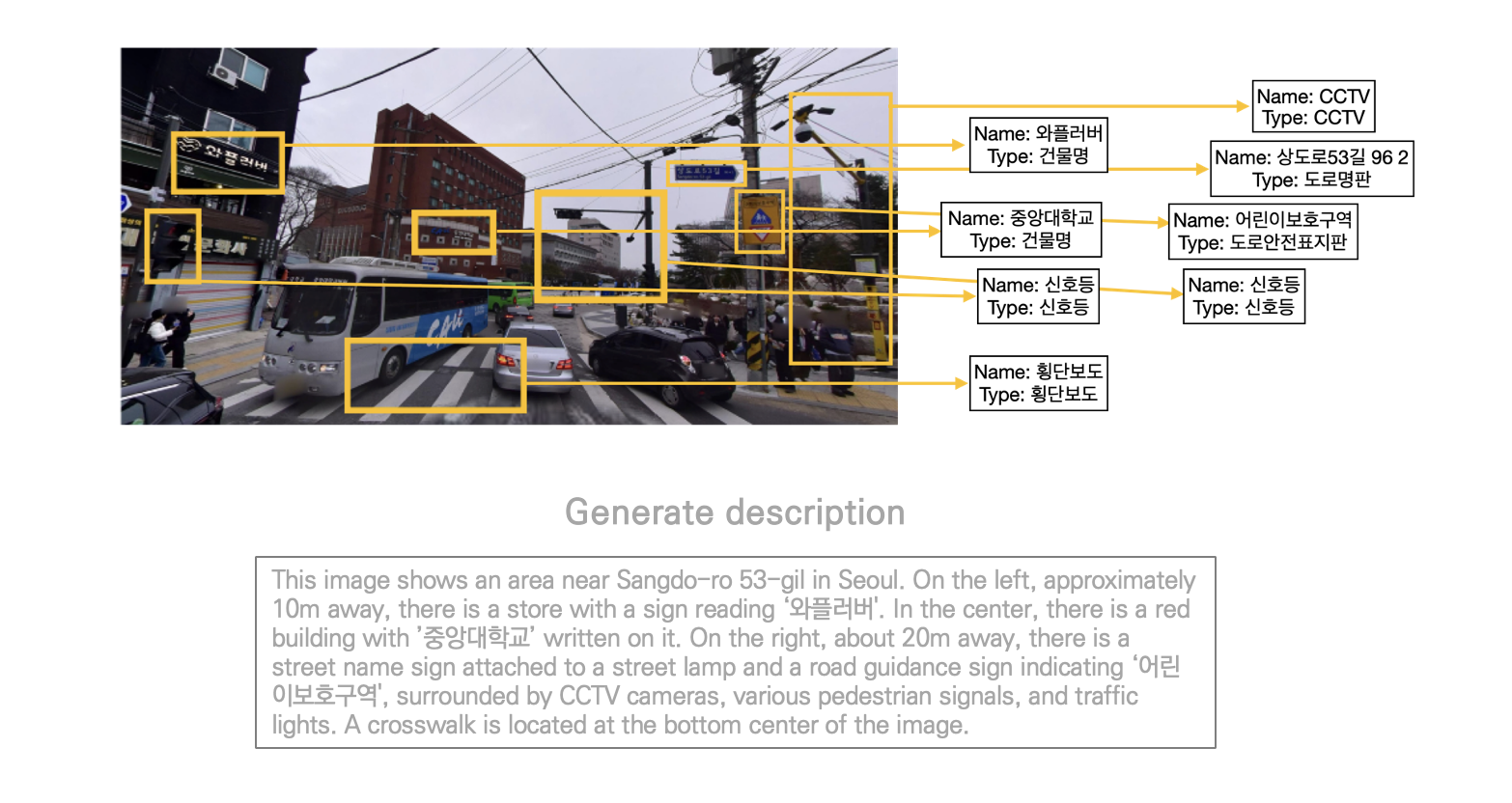
목표는 다음과 같다. 이미지에서 객체를 인식하는데, 이때 텍스트가 있다면 반드시 텍스트를 중심으로 인식한다(이 글에서는 Type을 분류하는 부분은 제외한다). 그리고 인식한 객체들을 기반으로 LLM에게 이미지에 대한 설명글을 작성하도록 한다.
작업은 다음 두 단계로 분류할 수 있다.
(1) 이미지에서 문자 인식하기
(2) LLM에 1의 결과를 넣고 이미지 설명글 작성하도록 하기
OCR
오픈소스 OCR library(EasyOCR, Tesseract 등)를 여러가지 테스트 해봤는데, 모두 한글 OCR의 성능이 내가 기대한 수준이 미치지 못했다. 아래 3개는 간단하게 웹에서도 테스트 해볼 수 있어서 공유한다.
LlamaOCR
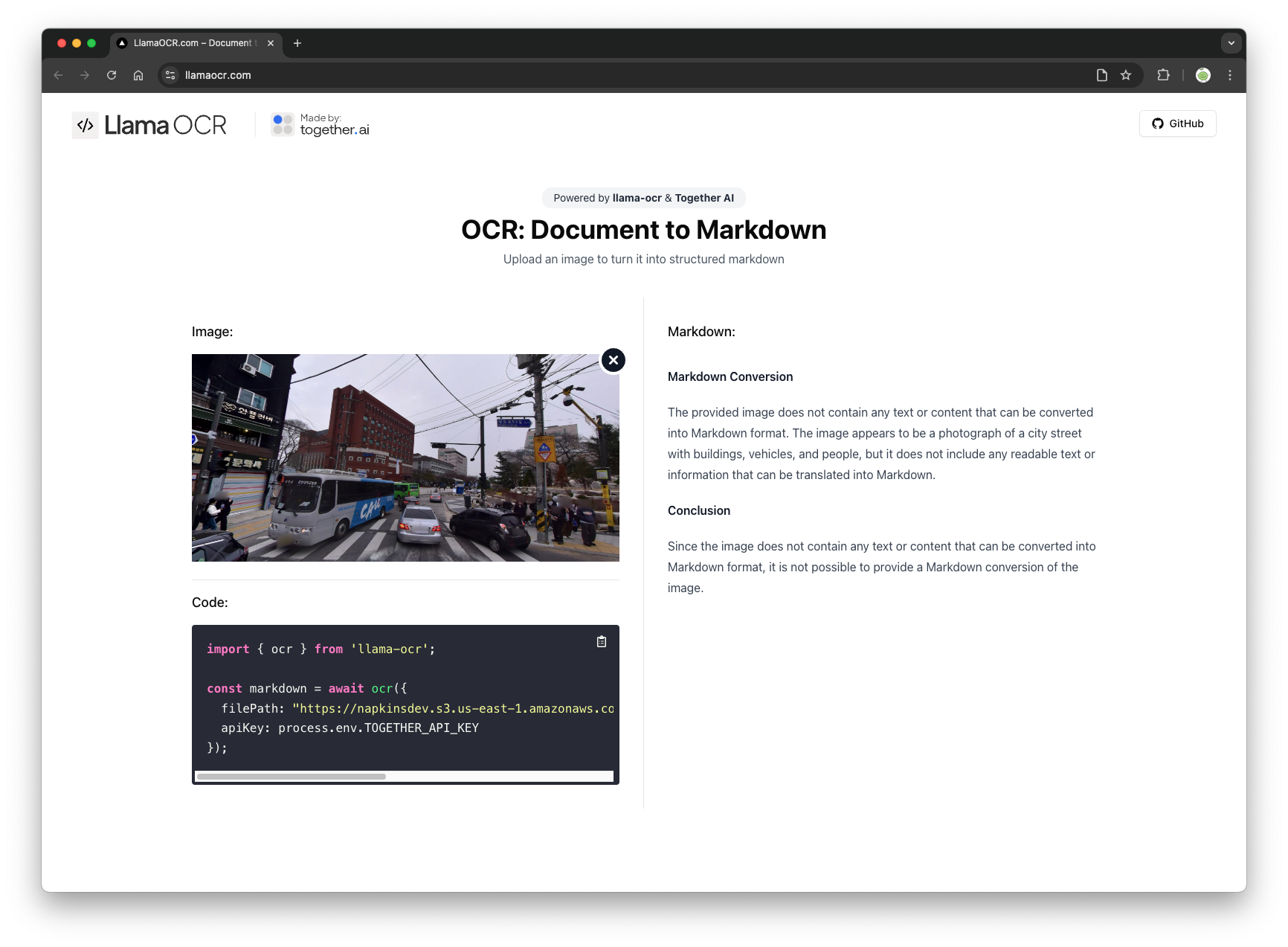
오픈 소스라는 점에서 큰 장점을 갖는 툴이라 사용해봤는데, 한글은 잘 지원이 안되는 것 같다. API는 찾아보지 않아도 될 것 같아서 패스!
Upstage Document OCR
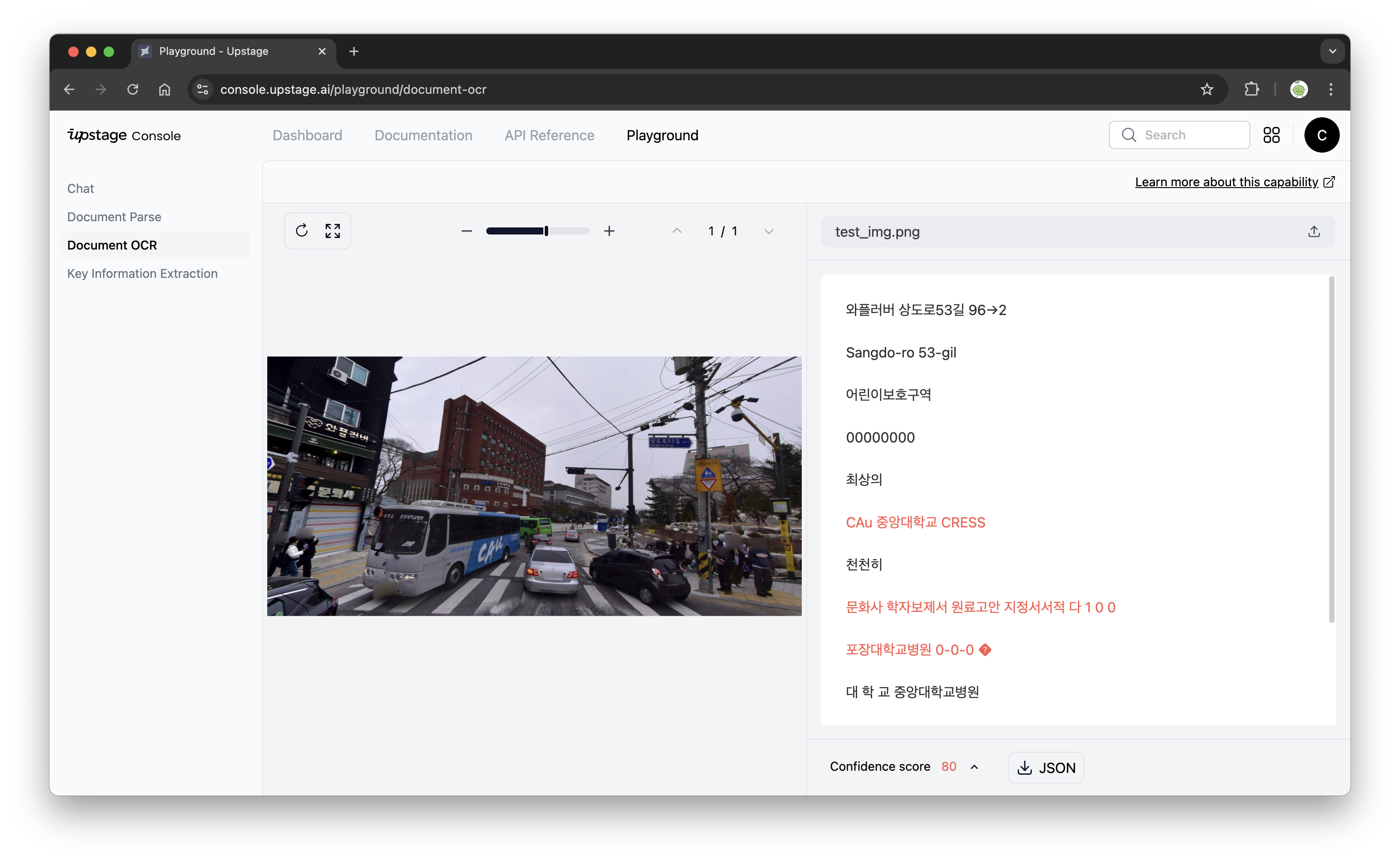
유료 툴이고, API도 제공한다. 어느 정도 잘 인식하긴 하지만, '와플러버 상도로53길 96 -> 2'와 같이 따로 분리되어 인식되어야 하는 문자들이 하나로 합쳐서 인식된 경우가 종종 있는 것을 볼 수 있다. 가격은 이미지 하나 당 $0.0015 정도이다.
Naver CLOVA OCR
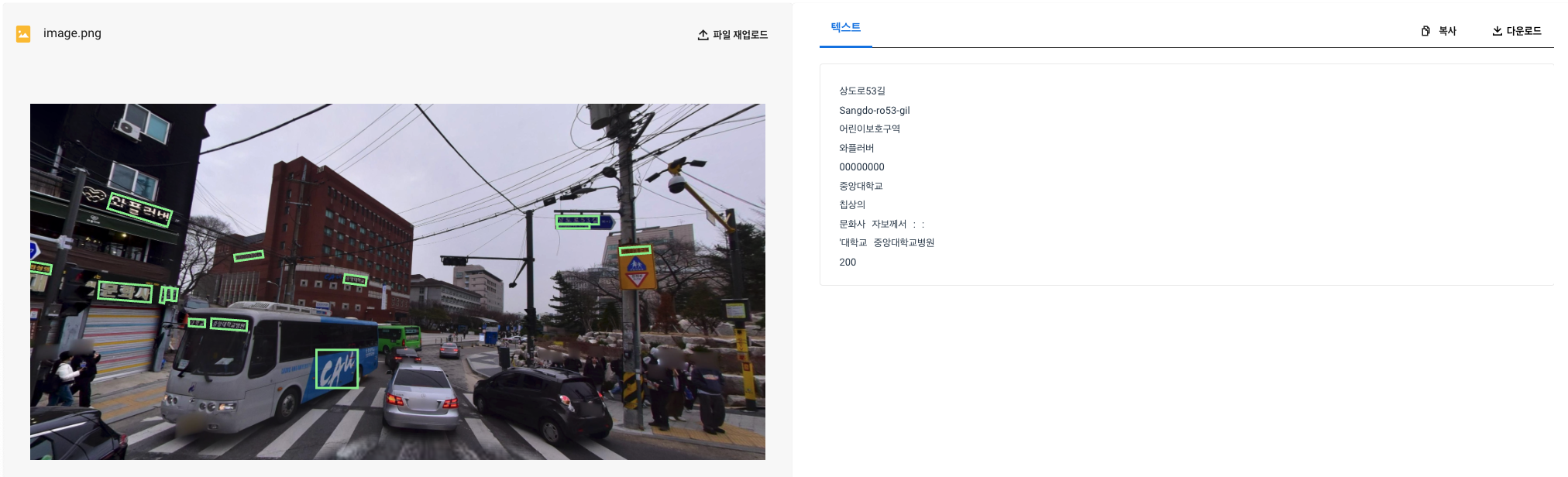
(CLOVA OCR도 위 사진 처럼 웹 브라우저에서 테스트 할 수 있는 곳이 있었던거 같은데, 현재는 못 찾겠다...)
최종적으로 선택한 건 Naver에서 개발한 CLOVA OCR이다. 이미지에서 글자만 잘 보더링하고, 위에서 있었던 문제 처럼 구분되어야 하는 문자들을 잘 구분해서 출력해줬다. 또한 이미지에서 글자 부분을 boxing한 이미지도 output으로 줘서 필요할 때 활용할 수도 있었다.
비용적인 부분도 괜찮았는데, Nacer Cloud Platform은 기본적으로 첫 가입을 하면 10만 크래딧을 무료로 제공한다. 기본적인 OCR은 이미지당 3원이기 때문에 (가격 참고) 마음껏 써도 무료 크래딧안에서 충당할 수 있는 정도이다. 이미지뿐만 아니라 pdf와 같은 Document OCR도 제공해서 테이블이나 특정 탬플릿을 만들어서 인식하도록 하는 것도 가능하다.
필자는 Python에서 API를 호출해서 사용했다. API Key를 발급하고 설정해주는 방법은 공식 문서에 기재되어 있으니 참고하면 된다. 사용한 코드는 다음과 같다.
# OCR
def clova_ocr(image_path):
secret_key = ''
api_url = ''
try:
# 이미지 파일 읽기
with open(image_path, 'rb') as f:
request_json = {
'images': [
{
'format': 'jpg',
'name': 'demo'
}
],
'requestId': str(uuid.uuid4()),
'version': 'V2',
'timestamp': int(round(time.time() * 1000))
}
payload = {'message': json.dumps(request_json).encode('UTF-8')}
files = [('file', f)]
headers = {'X-OCR-SECRET': secret_key}
response = requests.post(api_url, headers=headers, data=payload, files=files)
if response.status_code == 200:
ocr_results = response.json()
all_texts = []
for image_result in ocr_results['images']:
for field in image_result['fields']:
text = field['inferText']
all_texts.append(text)
full_text = '|'.join(all_texts)
return full_text
return None, None
except Exception as e:
print(f"Error in CLOVA OCR: {str(e)}")
return None, None
def encode_image(image_file):
with open(image_file, "rb") as image_file:
return base64.b64encode(image_file.read()).decode("utf-8")secret_key와 api_url는 각자 발급받은 것을 넣어주면 된다. encode_image 함수는 jpg또는 png 파일을 base64로 인코딩해주는 함수이다. 사용은 다음과 같이 하면 된다.
img_path = 'test_img.png'
base64_image = encode_image(img_path)
ocr_output = clova_ocr(base64_image)'|' 구분자로 연결해서 출력하도록 했으므로 결과는 다음과 같이 나온다.
상도로53길|Sangdo-ro53-gil|어린이보호구역|와플러버|00000000|중앙대학교|칩상의|문화사|자보께서|:|:|'대학교|중앙대학교병원|200Using LLM
위 결과를 이제 LLM에 input값으로 넣어서 다시 이미지의 설명을 작성하도록 한다. 외부의 정보를 새로운 정보를 생성하도록 넣어주는 작업이기 때문에 넓게 보면 RAG의 개념으로 이해할 수 있다. 사용한 모델은 OpenAI의 gpt-4o이다.
Sytemmessage는 각자 잘 작성해주면 된다. 영어로 작성하는게 성능이 더 좋고 input token 수도 적은 것 같아서 영어로 작성해줬다.
Input에 OCR을 했을 때와 동일한 이미지를 넣어주고(이때도 base64로 인코딩 한 값을 넣어준다) 이 방법은 OpenAI 공식 문서에서 공개하고 있다.
# 이미지 설명
def image_explain(base64_image, ocr_output):
messages=[
{"role": "system", "content": f"""
Analyze the image using OCR data as supplementary information and describe the location in Korean (3+ sentences).
# Physical location details:
- Must include ~~~
- Must mention ~~~
WARNING:
- Describe ONLY what is clearly visible in the image
- Do NOT make assumptions or add information not shown
- Ignore location names shown on buses or advertisements
- If certain elements are unclear or partially visible, indicate this in your description
Supporting OCR data: {ocr_output}
"""
},
{"role": "user", "content": [
{"type": "image_url",
"image_url": {
"url": f"data:image/jpeg;base64,{base64_image}",
"detail": "high"
}
}
]}
]
output = chat.invoke(messages)
return output출력값은 다음과 같다.
이 이미지는 서울 중앙대학교 인근의 모습을 담고 있습니다. 왼쪽에는 '와플러버'라는 가게가 위치해 있으며, 그 옆에는 '문화사'라는 상점이 보입니다. 오른편에는 '상도로53길'이라는 도로 표지판이 있고, '어린이 보호구역'이라는 교통 표지판도 확인할 수 있습니다.테스트 해보기 전에는 이렇게 OCR의 텍스트를 그대로 넣어줘도 LLM이 어느 객체와 관련된 것인지 인식해서 참조할 수 있을까 의문이었는데, 실제로 해보면 잘 이해해서 적용하고 있음을 확인할 수 있었다.
간단한 방법이지만, gpt-4o만 사용해서 이미지에서 텍스트를 인식할 때보다 훨씬 정확률이 높았다. 물론 Latency는 약간 발생하지만, Naver OCR 속도가 생각보다 빨라서 체감 상 그렇게 불편하진 않았다. 앞으로 API가 어떻게 개선이 될진 모르겠지만, 당분간 API로 이미지를 인식할 때는 이렇게 OCR과정을 한 번 거친 뒤 넣어줄 것 같다.
