
구글에서 작년 말 정도에 Agent 백서를 발행했고, 간단한 설명과 실용적인 내용을 담고 있어서 많은 도움이 됐다. 백서의 내용을 정리하고 요약한 글은 검색해보면 굉장히 많으므로 생략하고, 해당 글에서는 백서를 읽으면서 개인적으로 새로 알게된 내용, 궁금한 점들을 적어보았다.
'백서'가 영어로 'White paper'인걸 보고 화들짝 놀랐다. 나만 놀랐나? ㅋㅋㅜ
✅ Agents와 models의 차이는?

이 글에서는 Agents와 models의 개념에 대해서 명확하게 비교하고 있다. 여기서 말하는 model은 gemini와 같은 LM(Large Model)을 의미한다. 평소에 최근 개발되는 LM들은 이미지나 영상 등 Multi-modality화 되고 있어서 LLM, 즉 Language Model이라고 표현하면 개념적 오류가 있지 않나라고 생각했는데, 역시 이 글에서는 'Models'라고 표현한다는 점이 인상적이었다.
이 문서의 여파인지, 최근 LinkedIn을 비롯한 각종 커뮤니티에는 Agent와 models를 비교해서 설명하는 글이 자주 보인다.
✅ 그럼 LLM기반의 RAG framework는 Agents라고 볼 수 있을까?
사실 이 부분이 가장 혼란스러웠다. Agent라는 개념이 이렇게 뜨기 전에, 나를 포함해서 많은 사람들이 Langchain과 Langgraph 기반의 RAG 프레임워크를 테스트해보고 사용하고 있었다고 생각한다. 그럼 지금까지 내가 사용한건 Agent가 아니란 걸까?
LangGraph는 기본적으로 Agents를 구현하기 위한 Langchain의 프레임워크임
결론부터 얘기하면 아니다. 여기서부터는 개인적인 이해를 바탕으로 적었는데, '여러가지 Tools와 연결되는 방식에 따른 차이로 구분' 된다고 정리할 수 있다고 생각한다. 즉, input이 들어왔을 때, 정해진 flow(e.g. Input이 들어오면 반드시 VectorDB를 통한 유사한 chunk를 기반으로 data augmented된 답변을 생성하는 vanilla RAG)에 따라서 답변을 생성하는지 혹은 Model이 상황에 맞는 Tool을 직접 선택하고 필요에 따라서 flow를 움직이며 답변을 생성하는지의 차이라는 것이다.
RAG와 Agent를 설명하는 한 글에서는 'RAG가 기억장치(정보 테이브)를 언어모델에 장착하는 일이라면, Agent는 언어모델에 팔다리를 붙여주는 일' 이라고 설명하기도 한다.
예를 들어, 다음 두 가지 케이스의 RAG기반의 구조가 있다고 하자.

왼쪽의 경우, 일반적은 RAG구조로, input query가 들어오면 vectorDB에서 쿼리를 해서 Model에게 참고할 수 있는 정보를 넘겨주고, 최종 result는 이를 기반으로 생성한다. 이때 VectorDB 부분에는 Search API가 들어갈 수도 있고, 기타 data augmented 프로세스로 교체될 수 있다. 또한 query rewrite나 verifier와 같은 최적화, 검증 프로세스가 들어갈 수도 있다.
오른쪽 프로세스가 Agent의 개념과 헷갈리는 부분이었다. 이 구조에는 Router를 통해서 어떤 툴을 사용할 지 분기하는 과정이 추가되어 있는건데, 이때의 Router를 어떤 방식으로 쓰냐에 따라서 agentic하다고 볼 수도 있을 것 같다. 예를 들어, LM을 활용한 Router를 만들어서 케이스들을 모델이 분류해서 Tool로 연결되도록 한다면, 이건 Agent의 조건 중 '스스로 작업을 제어하고 작업의 경로 선택'이라는 것에 해당한다고 볼 수 있다. 반면, Router를 if-else 조건문과 같이 구성한다면, 예를 들어 'input query에 "검색"이라는 단어가 들어가면 Search API 도구로 연결해줘'와 같이, 이를 AgenticRAG라고 보기는 어려운 것이다.
여전히 알듯 말듯하다. Anthropic의 Building effective agents(2024.12.20) 글을 보면서 좀 더 알아보고자 했다. 이 글에서는 다음 세가지로 구분해서 agentic systems를 설명하고 있다.
(1) Building blocks
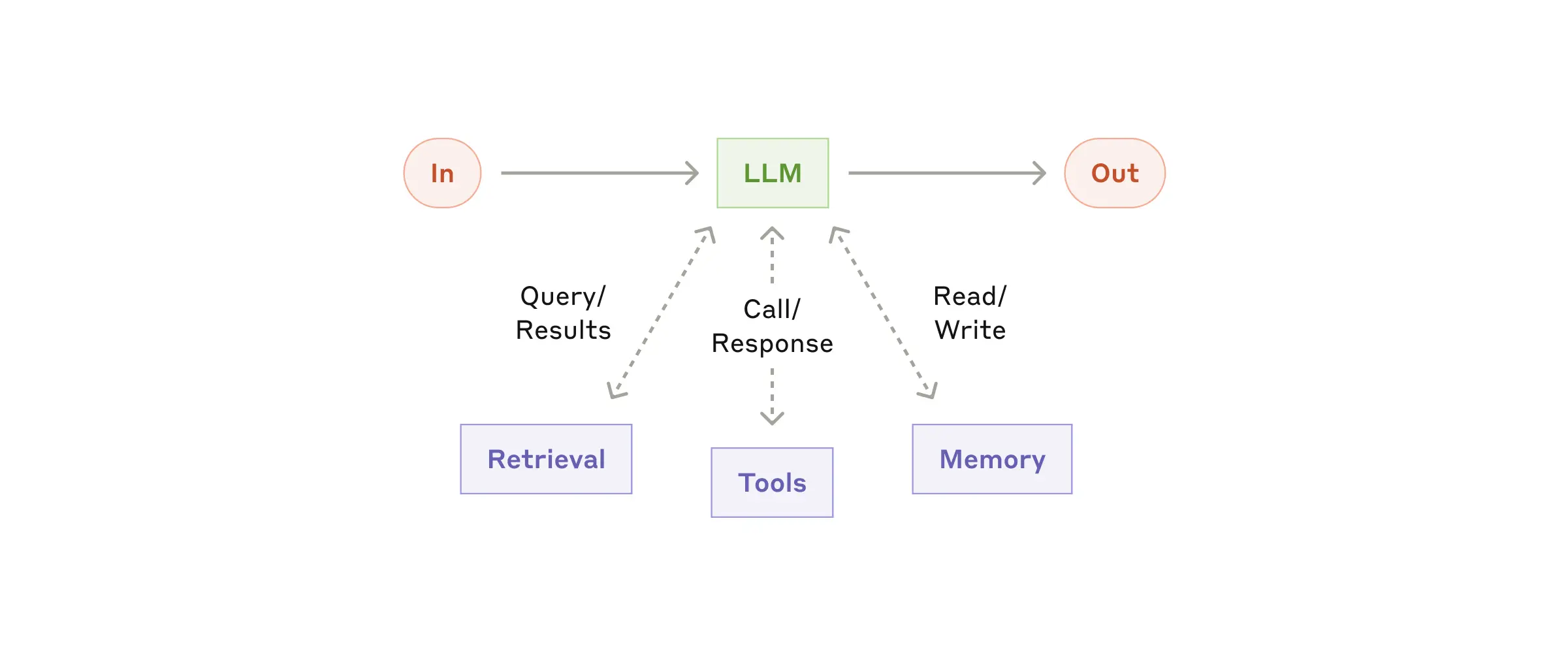
Building blocks는 LLM이 쿼리를 하고 적절한 Tool을 가져와서 사용하며 필요한 정보를 얻을 수 있는 프로세스를 의미한다. RAG에 베이스를 두는데, Tool을 직접 선택한다는 점에서 agentic system에 해당하는 것이다.
앞서 위에서 설명한 RAG구조 중 오른쪽의 구조에서 Router가 LM을 사용해서 판단하도록 한 경우가 이 케이스에 해당한다고 볼 수 있을 것 같다.
(2) Workflows
Workflows는 다시 Prompt chaining, Routing, Parallelization, Orchestrator-workers, Evaluator-optimizer으로 설명한다. 복잡해보이지만, RAG 플로우를 어떻게 만들어줄 것인지에 대한 케이스별 설명일 뿐이다. 이것들을 조합해서 무수히 많은 경우의 수가 나올 수 있을 것 같다.
Prompt Chaining의 Gate는 Evaluator와 크게 다르지 않다고 생각해서 verification 부분을 추가하는 것 정도로 이해했다. 아래 구조에서와 같이 Prompt chaining은 verifier에서 Fail일 때 Exit로 표현했고 Evaluator는 verifier에서 다시 Tool 부분으로 돌아가는 것으로 표현했다. Router는 단순히 분기만 해주는 역할이고 Orchestrator-workers는 분기해서 수행하도록 한 뒤, 결과를 종합한다는 차이가 있다고 하는데 이와 관련해서는 아래에서 더 자세히 설명하도록 하겠다(구글 백서에는 Orchestrators는 reasoning을 진행할 수 있다는 언급이 되는 것으로 보아 보다 고도의 내부 추론 과정을 수행한다고 볼 수 있다). Parallelization은 여러개의 Model 호출을 병렬적으로 진행한 뒤 종합해서 data augmented output을 생성하는 것이다. 아래와 같은 구조로 정리할 수 있다.

(3) Agents

여기서 Agents라는 표현 때문에 그럼 위에 것들은 모두 Agents기반이 아닌가..? 싶을 수 있지만, 이 글에서도 언급되듯 Building blocks, workflows는 모두 agentic system에 해당한다. 여기서 말하는 Agents는 보다 '자율형' 구조를 의미하는데, 위 그림에서 Enviroment에 앞서 위의 모든 Tools와 flow가 포함되고 이를 선택하는 과정이 유동적이라는 것이다.

이 의미는 구글의 Agents 백서에 있는 Figure14를 통해서 보다 쉽게 이해할 수 있다. 사용자의 input이 들어갔을 때, 초록색 부분의 ReACT 기반의 Reasoning을 하는데, 처음에 질문에서 검색을 해야 하는 부분을 캐치하고 vector search라는 action을 진행한다. workflow에서 router를 통해서 조건부로 Tool을 사용하는 것과 차이가 있는 것이다. 즉, '~할 때는 A를 사용하고, ~할 때는 B를 사용해줘'와 같은 명령이 아닌 'A는 ~할 때 사용해', 'B는 ~할 때 사용해'와 같은 Tool이 있다면 각 상황에 맞게 A, B, 혹은 A와B를 모두 사용하는 식으로 진행되는 것이며, 이 부분이 앞에 workflow의 Router와 Operator의 차이라고 볼 수 있다.
💥 여기서 궁금한 점
사용자의 질문을 어떻게 처리해야 하는지를 판단하는건 Tool에 기입한 설명과 prompt를 기반으로 작동하는 것으로 알고 있는데, Router를 통해서 진행하는 것보다 자율성은 높지만 정확도도 높을까?>> The autonomous nature of agents means higher costs, and the potential for compounding errors. We recommend extensive testing in sandboxed environments, along with the appropriate guardrails.
자율적 특징은 더 높은 비용과 복합적인 오류를 만들 수 있다는 설명으로 보아, case by case인 듯...
✅ Summary
구글 Agents 백서와 Anthropic의 글을 종합해서 정리하면 다음과 같다.
- Workflow는 사전에 정의된 규칙적인 경로를 따르는 반면, Agents는 스스로 작업을 제어하여 복잡하고 예측할 수 없는 작업을 수행할 수 있음
- Agents는 여러가지 도구(여러 모델 혹은 API 혹은 사용자가 생성한 함수 등)에 실시간으로 접근하고 활용할 수 있으며, 이를 자율적으로 계획하고 수행함
- Orchestration layer는 Agents의 자율적인 수행을 판단하는 핵심(heart) 파트이며, ReAct, CoT와 같은 Reasoning 태크닉을 활용함
- Tools: Extensions(외부 API), Functions(사용자의 함수), Data Stores(RDF, VectorDB, GraphDB 등 접근할 수 있는 저장소)
Anthropic은 Effective Agents를 구축하기 위한 세 가지 방법을 제시하기도 한다.
- 단순한 디자인으로 구성할 것
- Agent 구성 단계를 명확하게 보여줄 것(transparency 유지를 위해? for user?)
- 반복된 테스트를 통해 신중하게 만들 것
참고자료
- langchain(langgraph): https://langchain-ai.github.io/langgraph/concepts/agentic_concepts/
- huggingface: https://huggingface.co/blog/smolagents
- 테디노트-허정준님의 에이전트 관련 영상: https://www.youtube.com/watch?v=zb3v45ik9KI

오 agent 개념이 헷갈렸는데 잘 정리된거 같아용~