
- 전체보기(12)
- NLP(10)
- paper reading(10)
- Fine Tuning(2)
- Language Model(1)
- GPT1(1)
- XLNet(1)
- GPT(1)
- LM(1)
- Paper(1)
- transformer(1)
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding(by 정다희)
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding(by 정다희)
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding(by 정다희)
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding(by 정다희)
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding(by 정다희)
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding(by 정다희)
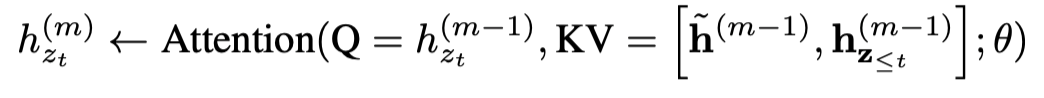
XLNet: Generalized Autoregressive Pretraining for Language Understanding(by 강유진)
XLNet: Generalized Autoregressive Pretraining for Language Understanding Abstract BERT와 같이 양방향 문맥을 모델링하는 능력으로 사전학습을 기반으로 한 denoising autoencoding은 a
Don’t Stop Pretraining: Adapt Language Models to Domains and Tasks (by 이원민)
최근 대부분의 NLP 관련 연구에서는 pretrained 모델을 사용본 논문에서는 특정 task와 domain의 data를 pretrain에서 사용하는 것의 유용성에 주목함RoBERTA 모델을 사용하여 실험을 진행RoBERTa는 기존 BERT의 pretrain에서 사용

XLNet: Generalized Autoregressive Pretraining for Language Understanding(by 안재혁)
factorize 또는 factorization order를 인수 분해라고 해석했는데, 오류일 경우 이 부분을 감안하여 봐주시길 바랍니다.XLNet은 Transformer-XL의 후속 모델이기 때문에, transformer-XL이 가진 고유한 특징을 이해해야 XLNet
XLNet
XLNetXLNet은 2019년 당시 대부분의 NLP Task에서 SOTA를 달성했던 BERT를 큰 차이로 밀어낸 모델핵심 ContributionGPT로 대표되는 Auto-Regression모델과, BERT로 대표되는 Auto-Encoder 모델의 장점을 합한 Gene
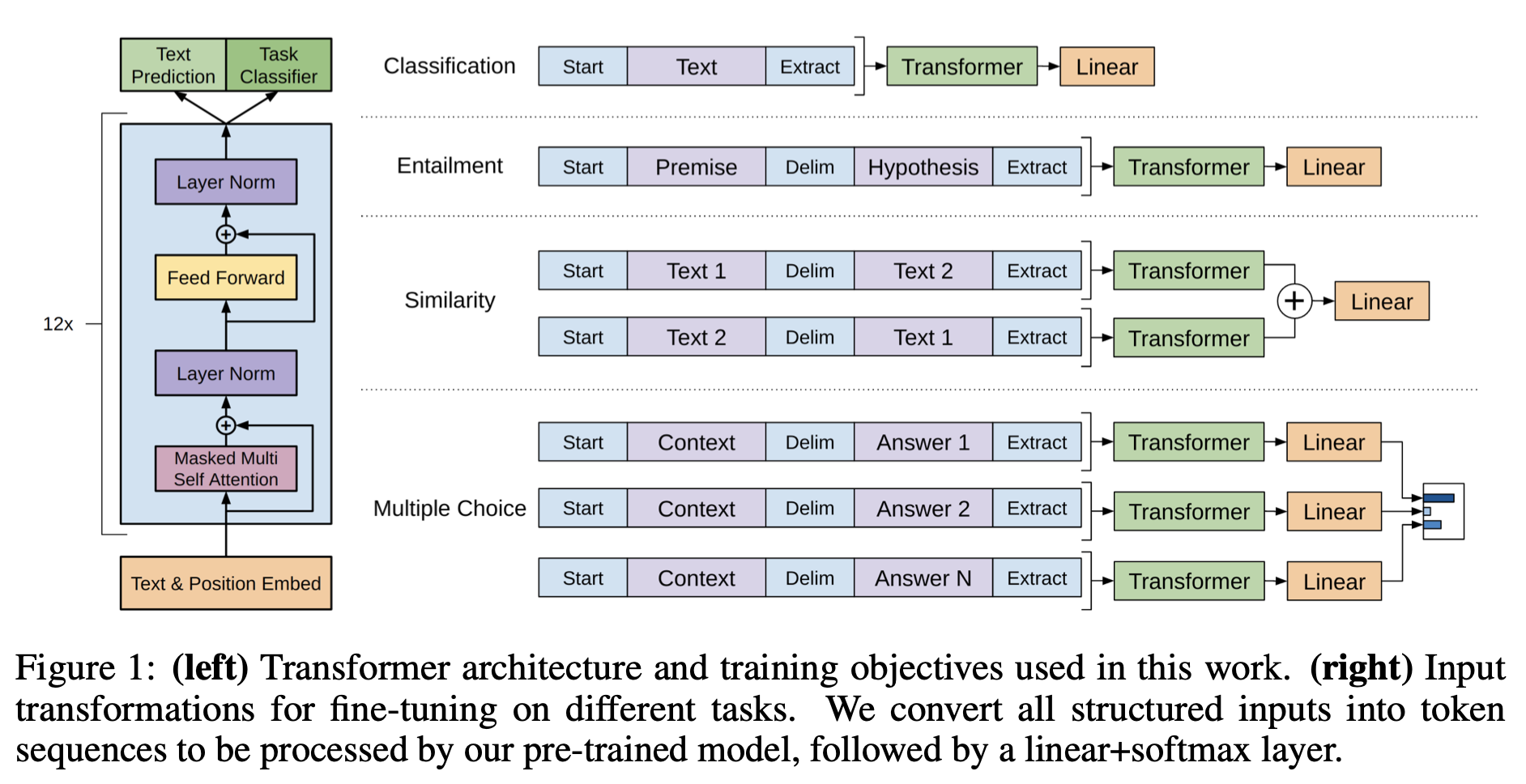
Improving Language Understanding by Generative Pre-Training(by 장준영)
GPT1 정리 내용입니다.

Improving Language Understanding by Generative Pre-training(by 안재혁)
The ability to learn effectively from raw text is crucial to alleviating the depedence on supervised learning in natural language precessing(NLP). Mos