1. 임베딩이란
사람의 언어는 불연속적인 형태의 단어로 이루어집니다. 각 단어가 서로 연관성이 있을 때도 있지만, 연관성이 없을 수도 있습니다. 사람은 이 정보를 자연스럽게 받아들일 수 있지만, 컴퓨터는 이 연관성을 이해하고 처리하지 못합니다. 이를 컴퓨터가 쉽게 단어를 이해하고, 처리하기 쉬운 형태로 변환하는 과정이 임베딩입니다.
2. 차원 축소
처음 사람들이 사람의 언어를 컴퓨터에게 이해시키기 위해 원-핫 인코딩(One-Hot Encoding)을 수행했습니다. 원-핫 인코딩이란 0과 1로 단어를 표현하는 방법입니다. 하지만 원-핫 인코딩은 높은 차원에서 데이터를 표현하여, 희소행렬(Sparse Matrix)문제가 발생합니다. 이렇게 높은 차원에서 데이터를 표현하는 건 좋은 상황이 아니기 때문에 이를 해결하기 위해 PCA등을 사용해 차원을 축소하여 데이터를 표현합니다. word2vec역시 차원을 축소하기 위해 만들어진 방법론입니다.
3. word2vec
word2vec은 2013년에 제시된 방법론으로 간단한 신경망을 통해 임베딩합니다. word2vec은 문장에서 함께 등장하는 단어가 비슷할 수록 비슷한 벡터 값을 가질 것이라는 가정으로 시작합니다. word2vec은 크게 두 가지 방법으로 Cbow와 Skip-gram을 제시합니다.
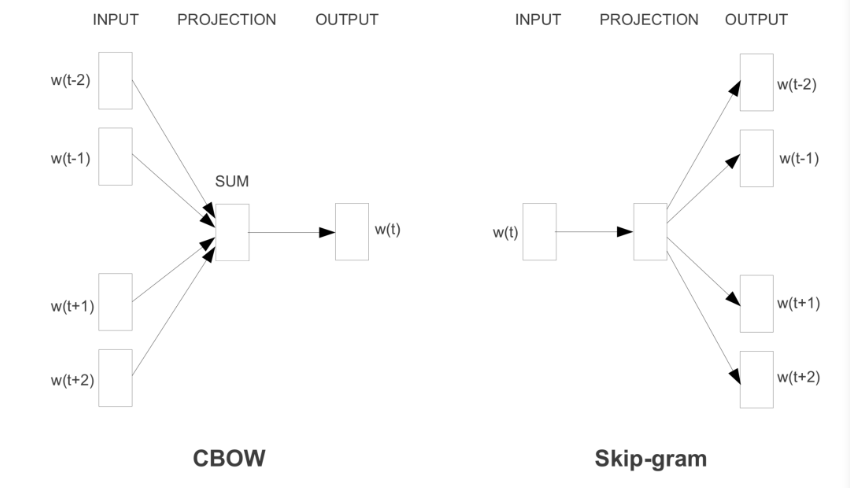
3-1 Cbow
Cbow(Continous bag of words)방식의 학습원리는 문장에서 예측하고자 하는 단어의 주변 단어들을 원-핫 인코딩된 벡터로 입력받아 예측하고자 하는 단어를 예측하는 방식입니다.
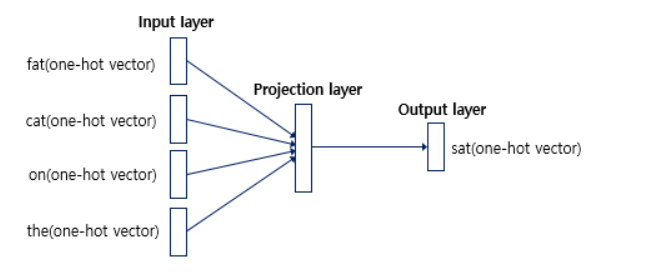
위의 그림과 같이 앞뒤로 두 개의 단어, 총 4개의 단어를 원-핫 벡터로 입력받아 목표로 하는 단어의 원-핫 벡터를 출력하는 방식입니다.
여기서 Projection layer의 차원이 임베딩 벡터의 차원이 됩니다.
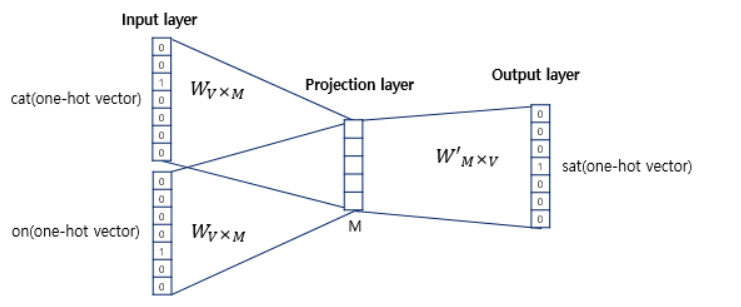
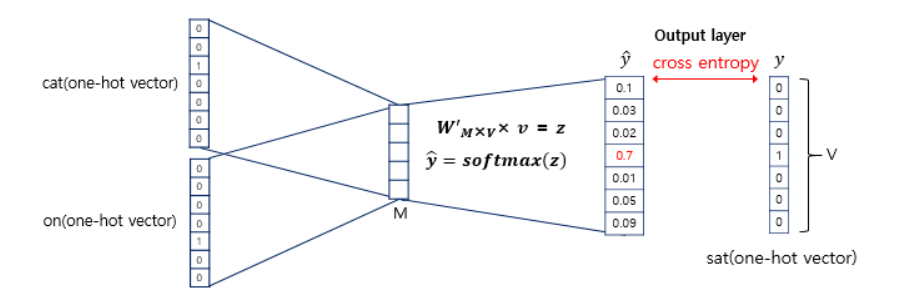
Cbow과정을 좀 더 자세히 들여다 보면, 위 그림과 같이 볼 수 있습니다. 그림에서 봐야할 건 와 으로 각각 입력층에서 Projection layer로 가는 가중치 행렬과 Projection layer에서 출력층으로 가는 가중치 행렬입니다. 는 원-핫 벡터의 차원, 은 Projection layer의 차원입니다. 는 랜덤으로 정해지며 이 가중치 행렬을 잘 학습하는게 Cbow의 목표입니다.
여기서 입력층의 값과 원-핫 벡터로 곱은 가중치 벡터의 입력층에 1이 위치한 행을 가져오는 형태를 보이게 되며 이를 lookup table이라고 합니다.
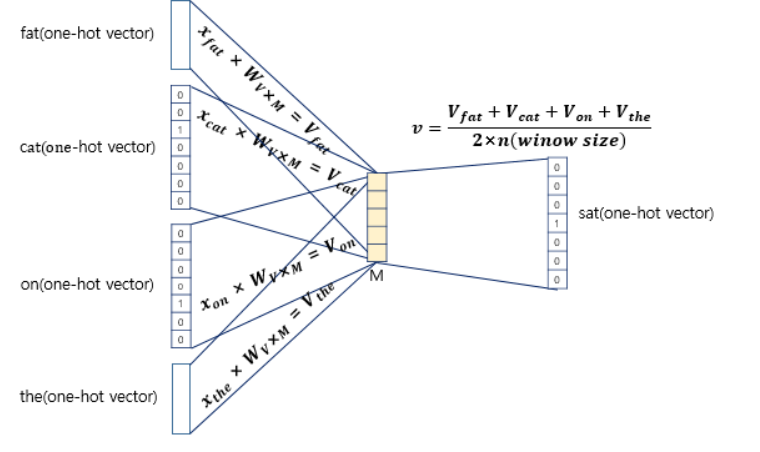
이제 입력층과 가중치 행렬을 곱한 값을 단어의 개수로 평균내여 Projection layer에 저장하고, 두번째 가중치 행렬인 와 곱해지고, 이후 softmax함수를 통과해 출력층 벡터의 합은 1이 되게 되고, 실제 예측 단어의 원-핫 벡터와의 차이를 줄이기 위해 손실함수를 사용하여 학습을 진행합니다.
3-2 Skip-gram
Cbow는 주변단어를 통해 타겟 단어를 예측했다면, Skip-gram은 그 반대입니다. 중심 단어를 가지고 앞 뒤로 n개의 단어를 예측하는 방법입니다.
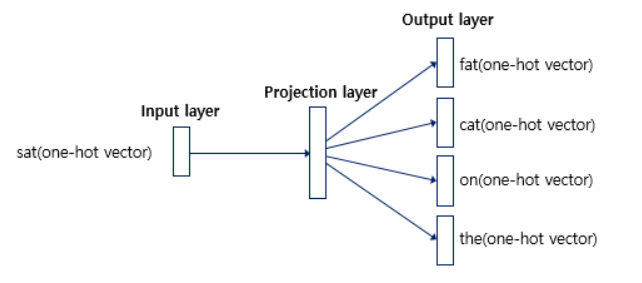
Cbow와의 차이점은 Projection layer에서 벡터를 평균내지 않는다는 것입니다. 이는 입력층의 단어가 하나 밖에 존재하지 않기 때문입니다.
4. 오해
사람들은 이렇게 훈련한 임베딩 벡터를 이후 다른 task에서 적용하고 싶어합니다. 우리는 이를 사전 훈련된 임베딩 벡터라고 부릅니다. 하지만 이렇게 주어진 임베딩 벡터는 단어의 특징은 잘 반영하지만, 텍스트 분류나 번역에서 쓰이긴 어렵습니다. 예를 들어 happy라는 단어는 번역에서는 그저 번역해야하는 일반적인 단어입니다. 하지만 소비자 리뷰데이터를 분석하여 소비자 만족을 조사하기 위한 task라면 happy는 매우 중요한 단어일 것입니다. 이렇듯 자신이 현재 진행하고 있는 task의 특징을 잘 파악하여 임베딩을 진행해야 합니다.
5. 정리
임베딩은 컴퓨터에게 인간의 언어를 학습시키는데 필수적인 요소입니다. 이후 전이학습에도 쓰이기 때문에 이를 이해하는데 많은 시간을 투자하기로 했습니다. 이번 글에서는 word2vec을 중심으로 학습하였지만, glove, bert,gpt등 많은 방법론이 있습니다. 이후 이와 관련한 글도 정리해보고자 합니다.
6. 참고
https://wikidocs.net/22660
https://velog.io/@jaeyun95/NLP%EC%8B%A4%EC%8A%B51.%EC%9E%90%EC%97%B0%EC%96%B4-%EC%B2%98%EB%A6%AC-%EA%B0%9C%EC%9A%94-%EB%8B%A8%EC%96%B4-%EC%9E%84%EB%B2%A0%EB%94%A9
https://lilianweng.github.io/posts/2017-10-15-word-embedding/
