해당 글은 Parameter-Efficient Transfer Learning for NLP 논문을 정리한 글입니다.
논문 링크:https://arxiv.org/pdf/1902.00751.pdf
ICML 2019
LLM 전체 파라미터 학습의 문제점
최근 LLM 모델이 많이 나오게 되면서 점점 천문학적인 숫자의 파라미터를 가진 모델이 나오게 되고, 각자 데이터셋을 가지고 모델의 일부만을 fine-tuning하는 경우가 많아졌습니다. 하지만 모델 전체를 Full fine-tuning하게 된다면 GPU 메모리 공간이 부족하게 되는 현상이 발생하게 되고 학습에 어마어마한 시간을 투자해야합니다. 그리고 각 task마다 새롭게 fine-tuning을 시켜줘야하는 불편함 역시 존재합니다. 이를 해결하기 위해 Parameter Efficient Fine-Tuning 즉, 더 적은 파라미터을 학습시켜도 성능을 유지하기 위한 연구가 진행 되었습니다.
대표적으로 adapter, Prefix-Tuning, LoRA가 존재하며 그중 adapter를 먼저 리뷰해보겠습니다.
1. Introduction
adapter의 목표는 각 task별로 모델을 학습시키는게 아니라, 조금의 파라미터의 추가로 다양한 task를 수행가능하고, 이전 작업을 잊지 않고 새로운 문제를 풀 수 있도록 하는 것이 목표입니다. 본 논문에선 이를 Adapter Module로 해결합니다.
2. Adapter tuning for NLP
위 그림은 Adapter의 구조를 보여줍니다. BERT의 transformer 모델의 Self-attention 모듈과, MLP모듈 사이에 adapter 모듈을 추가하여 약간의 파라미터를 추가하고, 이 모듈의 파라미터를 랜덤 초기화 해주고, 학습할때 기존 모델의 파라미터는 freeze합니다. 즉 adapter 모듈의 파라미터를 학습시키는 것으로 파라미터의 수를 줄인 것입니다.
그리고 adapter 모듈의 구조를 보면 히든으로 들어온 값에 feedforward down-project의 가중치가 곱해지고, 비선형성이 추가된 다음, 다시 feedforward up-project의 가중치가 곱해지는 형태입니다.
이때 feedforward up-project의 가중치는 거의 0으로 설정됩니다. 이렇게 되면 학습 초반엔 adapter가 거의 identity fuction처럼 작동하게 되며 학습이 진행되면서 adapter가 최적화 되는 것을 목표로 합니다.
또한 skip-connection이 되어 있으므로 원래의 파라미터를 잊지 않으며 학습이 진행됩니다.
3. Experiments
GLUE를 포함하여 매우 다양한 실험을 진행했다.
1. GLUE benchmark
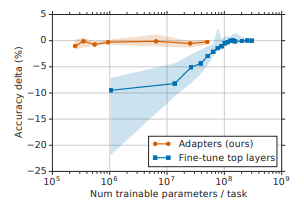
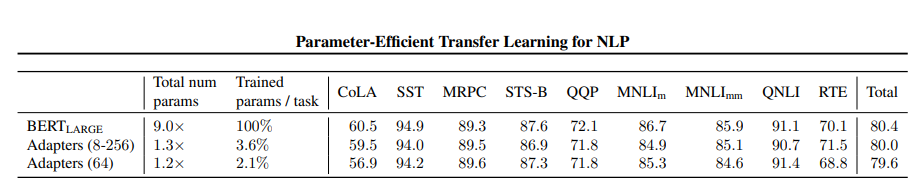
성능으로 보면 파라미터 수는 9.0X, 1.3X,1.2X로 크게 차이 나지만 성능은 80.4, 80.0, 79.6으로 크게 차이가 나지 않습니다.
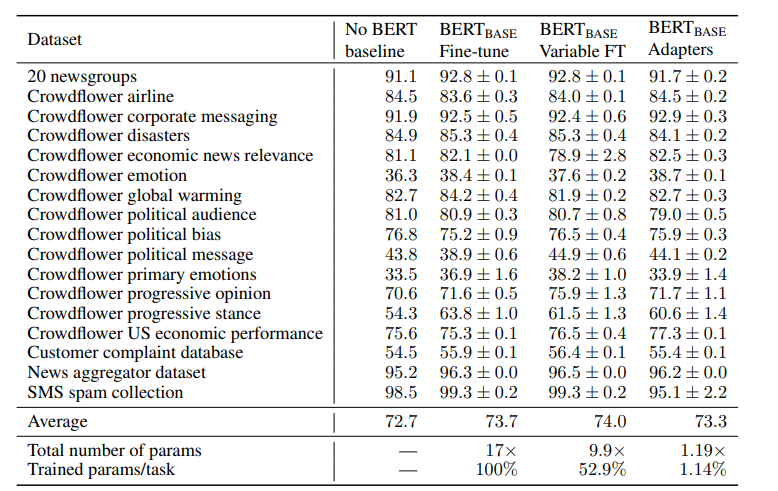
또한 다양한 DATASET에서 실험했을때 역시 거의 차이가 나지 않는 모습을 볼 수 있습니다.
