1. Abstract
https://www.cs.ubc.ca/~amuham01/LING530/papers/radford2018improving.pdf
기존의 딥러닝 방법론에선 task에 맞는 모델을 설계하고, supervised-learning의 형식에 맞게 labeled된 데이터를 활용했다면, open AI가 제시한 GPT는 unlabeled된 데이터를 더 잘 활용할 수 있는 방법론을 제시합니다. 그 방법은 우선 Generative pre-training하고, 이후에 특정한 task에 맞는 labeled된 데이터를 활용하여 discriminative fine-tuning하는 것입니다. 이 방법을 활용해 12개의 task 중 9개의 task에서 state of the art를 내었습니다.
2.Introduce
대부분의 딥러닝 방법론에서 labeled된 데이터가 필요하지만 이는 많은 비용이 들고, 다양한 task에서 이를 적용하기 힘듭니다. 그렇기 때문에 자연어 데이터 중 대부분을 차지하고 있는 unlabeled된 데이터를 잘 활용하는 것이 NLP에서는 중요하며, 잘 활용한다면 더욱 좋은 성능을 낼 수 있습니다.
그러나 이렇게 unlabeled된 데이터를 활용하는 것에는 2가지 큰 문제점이 있습니다
- 어떤 최적화 방법이 transfer에 유용한 text representation을 학습하는데 효과적인지 불분명
- 학습된 representation이 target tesk에 효과적으로 전달하는지 합의가 되어있지 않음
이러한 어려움은 효과적인 semi-supervised 학습에 대한 접근에 어려움을 주었습니다.
결국 pre-training한 모델이 특정 task에 효과적인지가 불분명하고, 이에 대해 서로 합의가 힘들었습니다. 그렇기 때문에 본 논문에서는 보편적인 표현 방법(universal representation)를 학습하는하여, 특정한 task에 맞게 학습하는 것이 목표입니다. 이 목표를 위한 모델 훈련은 2가지 절차를 사용합니다.
- 먼저 초기 네트워크에 unlabeled된 데이터를 활용해 학습을 진행하여 파라미터를 학습합니다.
- 목표로 하는 task에 맞게 학습한 파라미터를 supervised objective에 대응시킵니다.
네트워크는 long-term-dependency를 처리하기 위해 Transformer를 사용하였습니다.
3.Framework
앞서 말했듯 훈련 과정은 2가지로 large corpus of text를 학습하고, fine-tuning하는 것입니다.
3-1.Unsupervised pre-training
Tokens 이 주어지고 standard language modeling objective를 사용하여 다음 식을 최대화 합니다.
여기서 는 context window의 사이즈이고, 는 뉴럴네트워크의 파라미터입니다. 결국 토큰 가 주어졌을 때 의 확률 값을 계산합니다.
본 논문에서는 Transformer의 decoder를 사용했습니다.
이 모델은 기존의 decoder 부분에서 encoder-decoder attention을 제외하고, 임베딩() 후 position embedding matrix()를 더하고, layer의 수만큼 decoder block을 통과한 다음 position-wise layer()를 거쳐 softmax로 확률값을 구합니다.
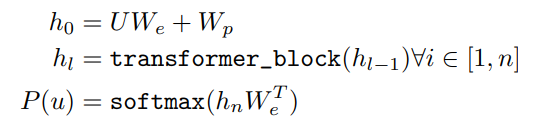
3-2. Supervised fine-tuning
이제 모델을 훈련한 후, supervised-learning을 수행합니다. 데이터는 각 텍스트 마다 label값이 존재해야하며, 는 각 데이터 세트, 텍스트 마다 토큰들 로 가정합니다.
이제 입력이 들어오고, 모델을 통과해 각 토큰에 해당하는 activation 과 linear layer인 를 추가하여 label y를 예측합니다.
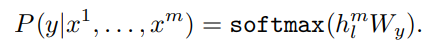
이 식을 모든 데이터세트의 log likelihood를 최대화 하는 식으로 바꾸면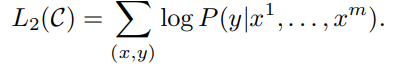
3-3.Task-specific input transformations
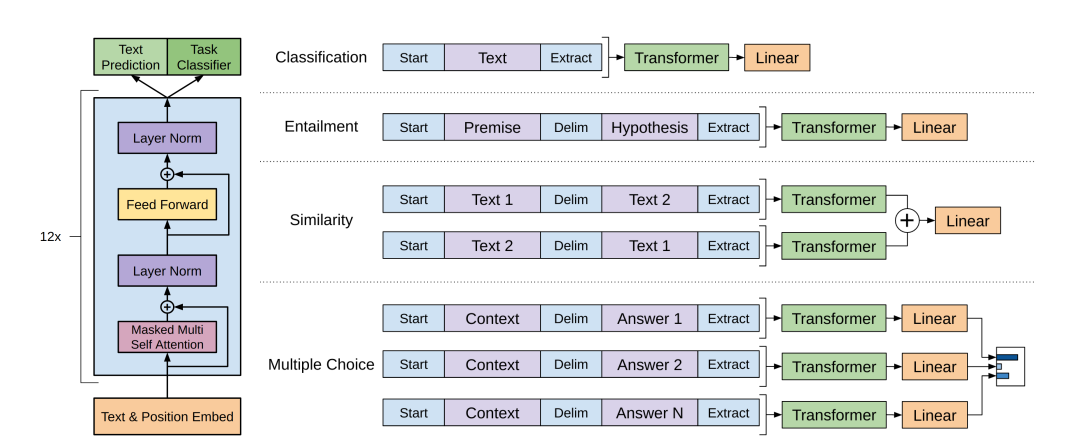
기존의 연구들은 transfer된 representation에서 새로운 아키텍쳐를 더 달아 복잡한 구조였지만, GPT-1의 경우, 구조화된 input을 순서가 지정된 시퀀스로 변환하는 traversal-style 접근을 활용하여, 아키텍쳐를 더 달거나 하는 변화를 줄일 수 있었다.
4.Experiments
Unsupervised pre-training에는 BooksCorpus라는 7000개가 넘는 책에 대한 정보로, 긴 지문을 학습하기 좋은 데이터셋을 활용했고, transformer decoder layer는 총 12개의 레이어로 구성되어 있고, self-attention head는 각 64개의 Q, K, V과 총 12개의 heads로 구성되어 있습니다. position-wise feed-forward는 총 3072차원이며 Adma optimizer를 사용하였습니다. 그 결과 12개의 task 중 9개에서 sota를 달성했습니다.
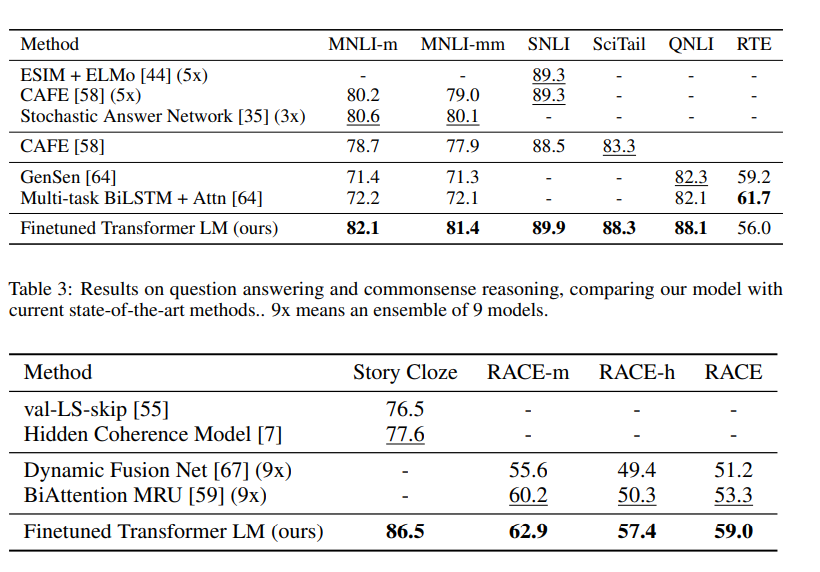
5.Analysis
transfer된 레이어에 따라 성능이 달라졌으며, transferring 임베딩을 주었을때 성능이 좋아졌습니다.
또한 LSTM에 비해 transformer를 활용했을때, 더 structured attentional memory하고, LSTM을 활용했을때 점수가 더 낮아지는 것을 관찰했다.
6.Conclusion
generative pre-training과 discriminative fine-tuning을 통해 자연어를 이해하는데 a single task-agnostic model framework를 도입했으며, 그 결과 12개의 task 중 9개의 task에서 sota를 달성했으며, 비지도학습에 대한 이해가 더욱 향상되었다.
