HR과 데이터 분석
비타민에 들어오면서 꼭 경험하고 싶었던 것이 HR과 관련한 분석을 한번은 해봐야지라고 생각했다.
HR과 데이터 분석은 그 당시 내 시야에선 너무 이질적으로 느껴질 정도로 서로 잘 어울리지 않는 분야였기 때문에 그 당시는 막연히 해보고 싶다라고 생각정도만 하고 과연 할 수 있을까란 생각이었다. 그래도 비타민에 들어와 머신러닝, 딥러닝, 그 중 특히 자연어 처리를 공부하면서 어느정도 가능성을 본 것 같았다.
https://www.youtube.com/watch?v=MJW9knnRV5o&t=564s
(이 유튜브 영상도 굉장히 도움 많이 됐습니다)
HR에서 Texanomy와 Ontology
경영학의 특징은 정말 필요한 모든 수단을 다른 학문에서 가져오거나, 관리하는 것을 좋아한다고 느낀다. Texanomy와 Ontology역시 마찬가지이다. 분류학 혹은 생물학, 철학에서 분류체계를 의미하는 두 단어를 가져와 이를 종업원의 역량으로 매핑하였다. 이는 잘 정의되어있는 체계를 활용한다면 종업원의 역량을 정량적으로 확인, 관리, 표현할 수 있다. 실제로 미국에선 파이썬의 라이브러리 하나하나 까지 관리를 한다.
O*NET Online은 미국 노동부 산하의 고용 및 훈련 관리국(ETA: Employment and Training Administration)이 제공하는 직업 정보 데이터베이스이다.
https://www.onetonline.org/

이를 어느정도 학문적인 성격이 강한 비타민에서도 적용가능하지 않을까란 생각에서 프로젝트를 시작하게되었다.
프로젝트 진행과정
우린 자연어 프로젝트였기 때문에 기본적으로 병수형(aka 비타민 회장님)이 비타민 자소서 데이터를 가지고 있어, 이를 활용하기로 했다.
프로젝트를 진행하면서 레퍼런스로 삼은 것이 코멘토의 AI 자소서 분석기이다.
https://comento.kr/analytics
코멘토에서 표현하길 100만개 이상의 언어표현과 역량간의 관계를 인공지능이 학습하였다고한다. 즉 언어표현과 역량의 데이터를 아래와 같이 표현한 것이다.
{
"동아리에서 데이터 분석적인 역량을 키웠습니다":"데이터 분석",
"프로젝트를 진행하며,,,":"계획 관리",...
}즉 우리는 자연어 상태의 지원서 데이터를 잘 정제하여 위와같은 데이터를 만드는 것이 1차 목표였다.
문장단위로 데이터를 만드는 것을 목표로 하였으나, 이는 너무나 많은 자원이 들어, 자소서 질문별로 역량을 매핑하는 것으로 목표를 세웠다.
데이터 전처리
먼저 자소서 데이터를 가져와 수기로 지원자들의 합불여부를 매핑하였으며, 기수별로 다른 자소서 문항을 통일하고, 중복 제출자의 데이터와 결측치를 제거하였다.
또한 2기부터 7기의 경우 합격률이 8기에서 13기보다 훨씬 높았기 때문에 8기에서 13기의 데이터를 활용하였다.
그리고 자소서를 살펴보다 보니 무성의한 답변이 생각보다 많았다. 어느정도가 무성의한 답변인지 기준을 잘 세워야 했는데, 글자수의 통계를 보고 100자에서, 150자로 글을 쓴 지원자들의 합격은 0명이었고, 전체 데이터에서 약 10~15%를 차지하였다.
그렇게 100자를 기준으로 무성의한 답변을 걸러내었으며 마스킹을 끝으로 기본적인 전처리를 끝내었다.
최종데이터

비타민에 필요한 역량 정의
가장 중요하고, 가장 많은 시간을 쏟은 파트이다. 비타민에 필요한 역량이 무엇인가?를 정의하는 일이였는데 가장 먼저 생각난 것이 NCS였다.
https://www.ncs.go.kr/th01/TH-102-001-01.scdo
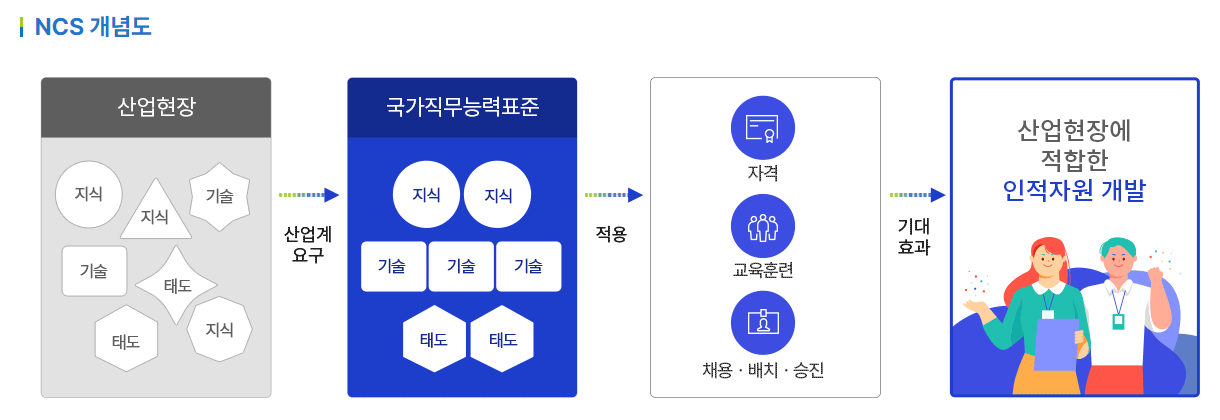
NCS는 한국에선 거의 유일한 직업의 Texanomy와 Ontology를 정리한 개념이라고 볼 수 있는데, 사실 우리가 원하는 완전한 개념은 아니었다.
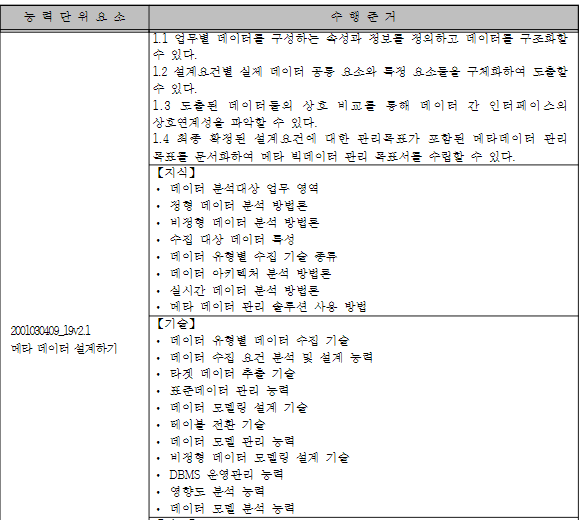
위와 같이 기술의 정의가 구체적이진 못하다.(어떤 기술을 쓰는지 직관적이지 않음)
그래도 우리가 활용할 수 있는 수단중 가장 합리적인 수단이었기 때문에 NCS를 뒤져가며 필요한 역량을 찾아내고, 그에 대한 정의를 최대한 구성하였다.
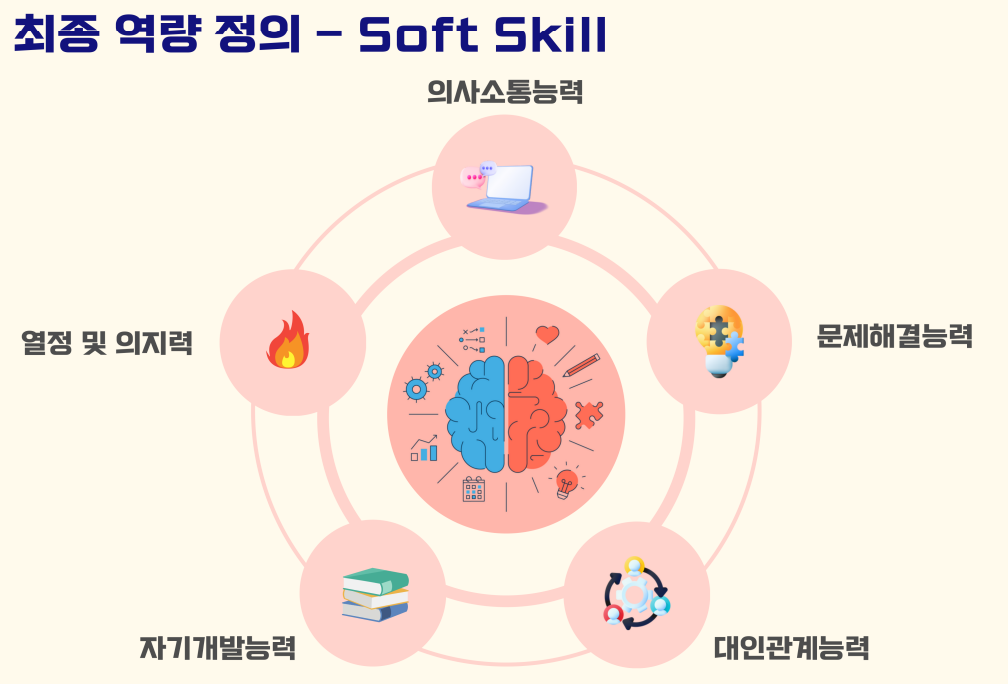
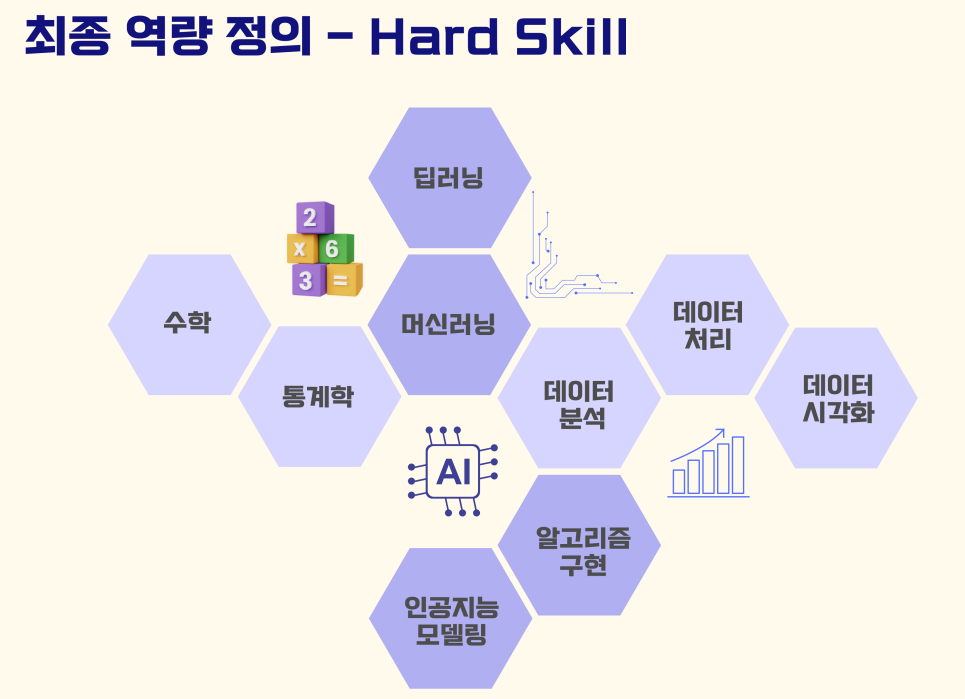
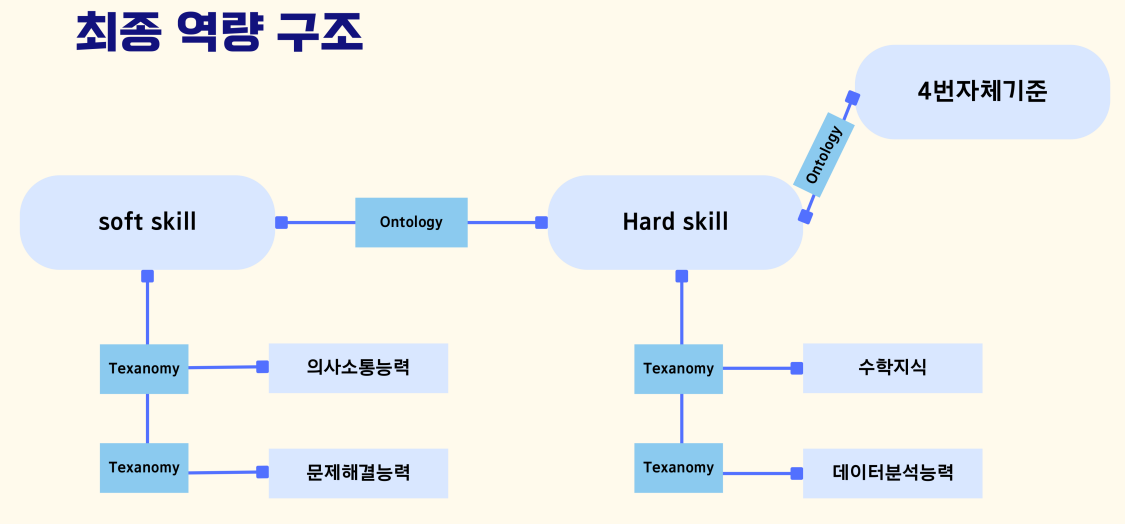
그렇게 해서 만들어 낸 최종 역량 구조이다. 크게 soft skill과 hard skill이라는 비타민에 필요한 역량들을 ontology로 매핑하였고, 그 하위로 들어가는 texanomy로 그 하위론 역량의 자세한 설명이 들어가도록 구성하였다.
4번 자체 기준
우리가 정한 최종 역량 구조를 보면 4번 자체 기준이 존재하는데, 이는 자소서 4번 문항의 역량 표현이 가능한가에 대한 질문이었다.
4번 문항의 질문은 동아리에 들어와서 하고싶은 과제, 혹은 기대하는 활동이다.
기본적으로 이 프로젝트는 자소서에 지원자의 역량이 표현되어 있다고 전제하고 진행하는 프로젝트이다. 하지만 4번 문항은 미래에 대한 질문이 포함되었기 때문에 지금 당장 지원자의 역량이 존재하지 않아도, 다른 대목을 보여준다면 좋은 평가를 받을 수 있는 항목이기 때문이다.
이 부분이 정말 어려운 부분이었는데 결국 이는 NCS에서 역량을 가져오기 보단 우리들이 이 자소서에서 원하는건 무엇인지, 어떤 부분이 잘 쓰였고, 그 부분이 실제로 합격에 영향을 줬는지를 엄밀히 살펴보았다. 그 결과 기준을 
목표 명확성, 데이터셋 구상, 고도화 여부, 실현 가능성으로 두었고 프로젝트를 진행하였다.
GPT API와 Prompt Engineering
이제 데이터와, 이를 매핑할 기준이 세워졌으니 데이터를 만들 차례이다.
먼저 어떤 LLM 모델을 활용할지가 가장 큰 문제인데, 한국어 LLM은 전체적으로 성능이 잘 안나오고, 파인튜닝을 할 데이터 자체도 양이 많지 않았다.
그렇기 때문에 조금 돈을 써서 현재 가장 좋은 모델이라고 할 수 있는 GPT4o를 활용하기로 결정하였다. 결정한 이유는 우선 한국어 성능이 가장 강하였고, 파인튜닝을 진행할 수 없는 상황에서 가장 좋은 답변을 제시하였기 때문이다.
가장 먼저 생각한것은 RAG였는데 우리가 정의한 기준을 문서로 주어 데이터를 뽑아내려고 하였지만, 성능이 잘 나오지 않았다.
그렇기 때문에 Prompt Engineering으로 눈을 돌려 우리가 정한 기준을 가장 잘 표현해주는 프롬프트를 만드는 것을 목표로 하였다.
사실 이는 try & error로 잘 쓴 자소서와 못 쓴 자소서를 프롬프트를 바꿔가면서 계속 시도했다.
데이터 완성
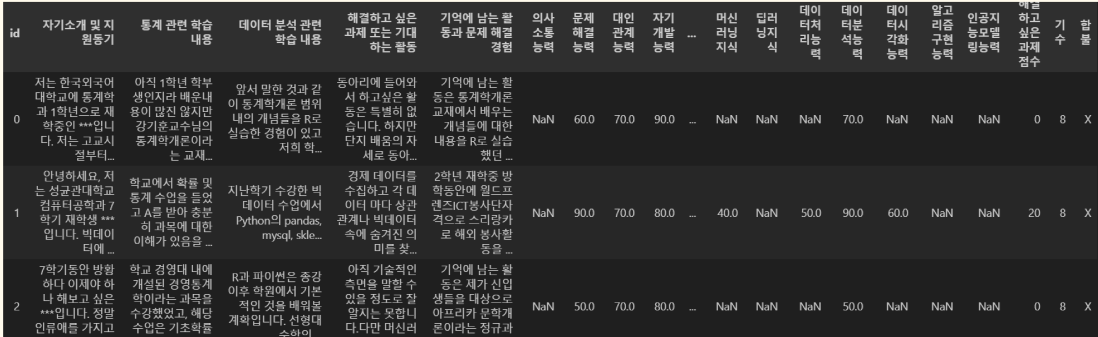
정말 많은 자원을 쏟아 결국 우리가 만족할 만한 데이터를 만들어 내었다. 위에 보이는 데이터가 그것인데, 데이터를 보면 NaN값이 많이 존재한다. 이는 try & error로 여러가지 프롬프트를 계속 시도하였는데 문제가 된것이 무분별한 역량 탐지였다.
특히 우리가 Soft skill로 정의한 내용들이 무분별하게 남발 되었는데, 예를 들면 단순한 인삿말에도 열정및의지력이 20%로 나오는 등 문제가 되는 부분이 있었다. 이를 방지하기 위해 프롬프트에 역량이 30% 아래로 나오면 이는 0으로 대체하는 조건을 추가해 이를 방지할 수 있었다.
이 데이터를 무엇을 할 것인가?
데이터를 만들었으니, 이제 이 데이터로 어떤 가치를 만들어 낼 것인가가 중요한데 우선 할 수 있는 정량적 분석은 다 해보았다.
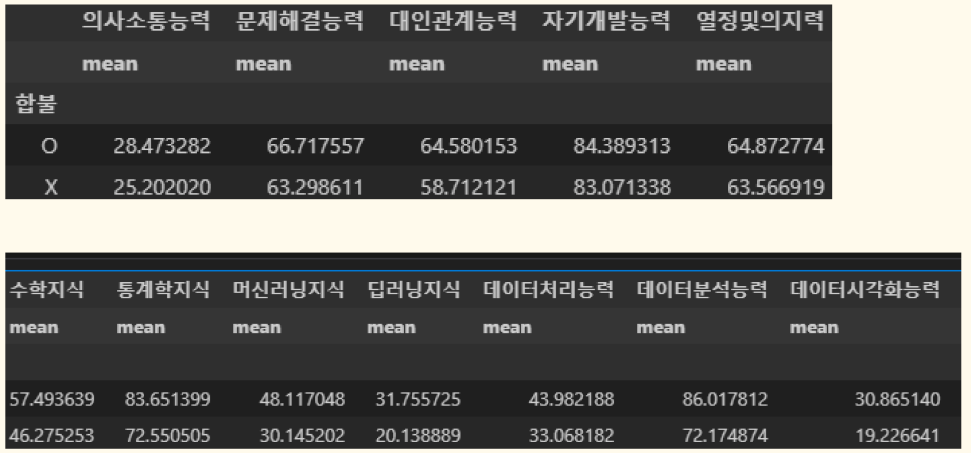
위와 같이 기본적인 역량별 평균 점수, 머신러닝을 통한 합불 예측, 추가하면 좋은 역량, 지원자와의 자소서 비교 등 다양하게 활용하였다.
머신러닝을 통한 합불 예측의 경우 아무래도 기존의 지원자를 선발하는 과정에서 위와같은 조건으로 선발이 진행된 것도 아니고, 데이터가 많은 것이 아니라 좋은 성능을 내진 못하였지만 이후 점점 데이터가 쌓이면 쌓일수록 좋은 결과가 나타날 것이라 예상한다.
그렇게 간단하게 Streamlit을 통해 만든 웹사이트를 배포하면서 프로젝트를 마칠 수 있었다.
https://bitaminresume.streamlit.app/
후기
정말 재밌었고, 힘들었던 프로젝트였다.
조장으로 할 수 있는 수단과, 여러가지 판단이 계속 주어졌는데, 최대한 합리적인 선택을 하려고 노력한 것 같다.
내가 가장 하고싶은 주제였고, 조장이었기 좀 더 잘하고 싶은 욕심이 컸었고, 나보다 훨씬 훌륭한 조원들과 함께해서 너무 값진 경험이었다.
함께 고생해준 병수형, 태호형, 은서, 진솔, 진섭 다들 너무 고생했고 감사했습니다. (꾸벅)
