지난 글에서 api를 통해 데이터를 불러오는 작업까지하고 개강이 와버렸다.. 봉사활동에, 운동, 토익, 과제, 이사준비등 정신없이 살다보니 목표로 했던 여러 임베딩 방법론의 비교까지는 못했고 전처리, 임베딩, 시각화까지 정리하려한다.
데이터 전처리
사실 전처리 할게 없다...

데이터를 보면 어디서 받아온 데이터인지 URL이 나오는데 그 출처가 위키피디아이다.

그렇기에 오타나, 수정해야할 부분이 거의 존재하지 않았고, 문장 단위의 임베딩을 우선 목표로 하여 불용어 역시 우선 나두는 방향으로 전처리 하였다.
해줘야 하는건 nan값과 중복값을 삭제하는 정도만 진행했다.

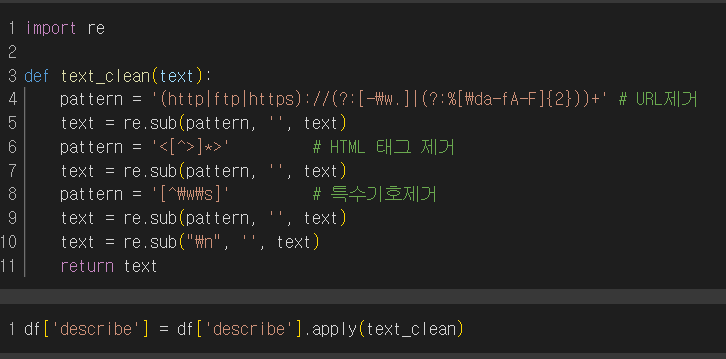
SBERT 임베딩
이전 동아리 프로젝트 하면서 진행했던 SBERT를 그대로 진행했다.

허깅페이스에서 우선 모델을 다운받아 무식하게 임베딩을 진행했고,

시각화를 위해 임베딩으로 나온 값을 tsv파일로 변환하였다.
코사인 유사도로 유사한 skill 찾기
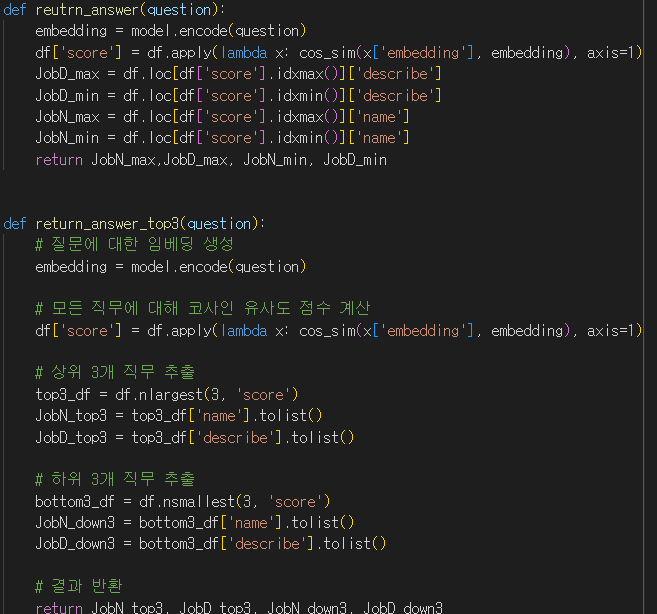
https://www.pa201.com/14 를 참고하여 코사인 유사도를 기반으로 아래 테스트 문장과 유사도가 가장 높은 skill와 직무기술서를 추출해보았다.
test_sentence = 'Data collects, processes, and performs statistical analyses of data. They transform raw data into actionable insights and information, using tools and techniques to identify trends, patterns, and correlations within datasets. Their work supports decision-making in various domains like business, finance, healthcare, and more. '
나름 잘 나온거 같은데 유사하지 않은 skill로 맹장염이 나왔다..? 이게 뭔가 싶어서 출처를 찾아보니 맹잠염을 진단하는 과정이 기술 되어있었다.
시각화
위에서 추출한 임베딩을 시각화 하기 위해서 tsv파일로 저장을 했는데 이걸 시각화 하면은 아래 그림과 같다.
https://projector.tensorflow.org/
사이트에서 시각화 할 수 있다.
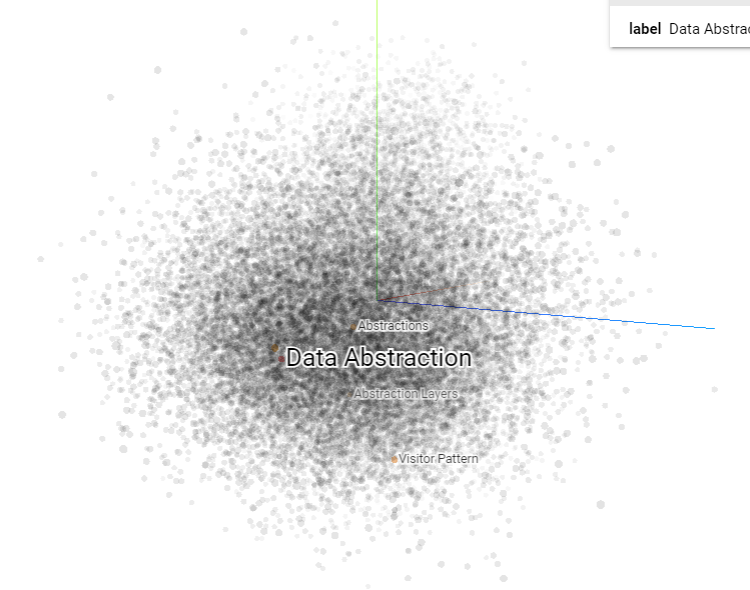
개강과 여러 이슈로 인해 큰 진전이 없는 점이 너무 아쉽다. 봉사활동, 이사가 4월에 끝나는데 최대한 정신을 차리자..
