이 글은 김기현의 자연어처리 딥러닝 캠프의 내용을 요약하였습니다.
전이학습이란?
전이학습(transfer learning)이란 신경망의 일부 또는 전체 신경망 가중치 파라미터를 최대우도법을 통해 학습데이터에 본격적으로 훈련시키기에 앞서, 다른 데이터셋이나 목적 함수를 사용해 미리 훈련을 한 후, 이를 바탕으로 본격적인 학습에서 신경망 가중치 파라미터를 더 쉽게 최적화하는 것을 의미합니다.
사전에 훈련된 신경망의 각 계층들은 문제를 해결하기 위한 데이터들을 잘 설명할 수 있는 특징들을 추출하도록 훈련되어 있을 것입니다. 따라서 만약 우리가 비슷한 특징을 지닌 데이터셋으로 유사한 문제를 해결하고자 한다면, 랜덤하게 초기화된 상태의 가중치 파라미터에서 최적화를 시작하기보다는 기존에 이미 훈련된 가중치 파라미터에서 조금만 바궈서 새로운 문제를 풀게하는 편이 훨씬 쉬울 수 있습니다.
기존의 전이학습 방식
word2vec이 등장한 이후, 사람들은 꾸준히 사전 훈련된 단어 임베딩 벡터를 사용해 딥러닝 모델을 개선하려 했습니다.물론 사전 훈련된 단어 임베딩 벡터들은 기존의 머신러닝 알고리즘에 적용하면 성과가 있을 수는 있지만, 딥러닝 모델에서 임베딩을 하는 task가 다르기 때문에 큰 효과를 거둘 수 없습니다.
기존의 전이학습에서는 이 사전 정의된 임베딩 벡터를 잘 활용하는 방안으로 연구가 진행됐습니다. RNN을 사용해 텍스트 분류 신경망을 예시로 들면
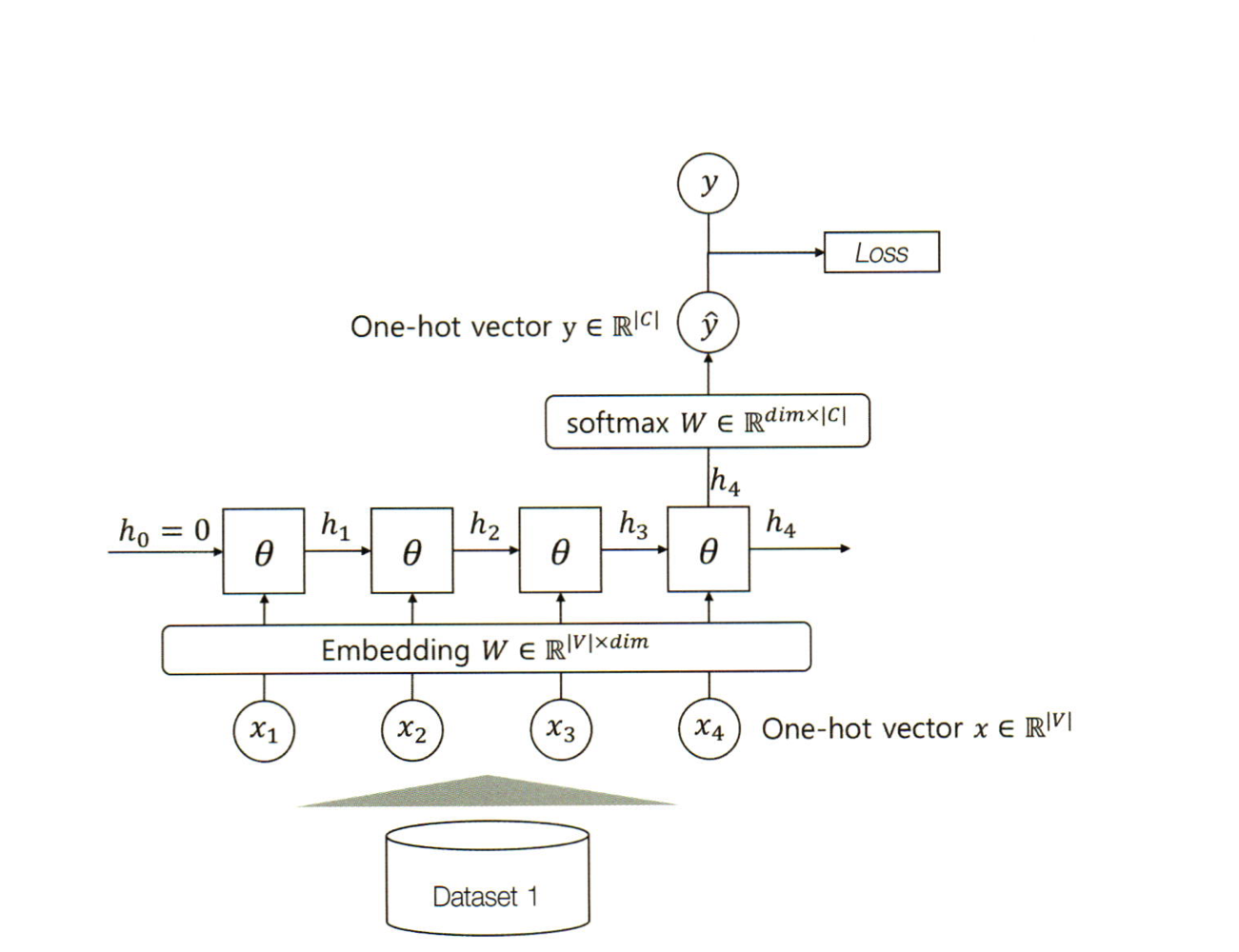
위 그림과 같이 임베딩 계층에서 이루어진 임베딩 벡터들을 문장의 단어 대신 입력 x로 넣고 신경망을 통과해 클래스를 예측할 것입니다.
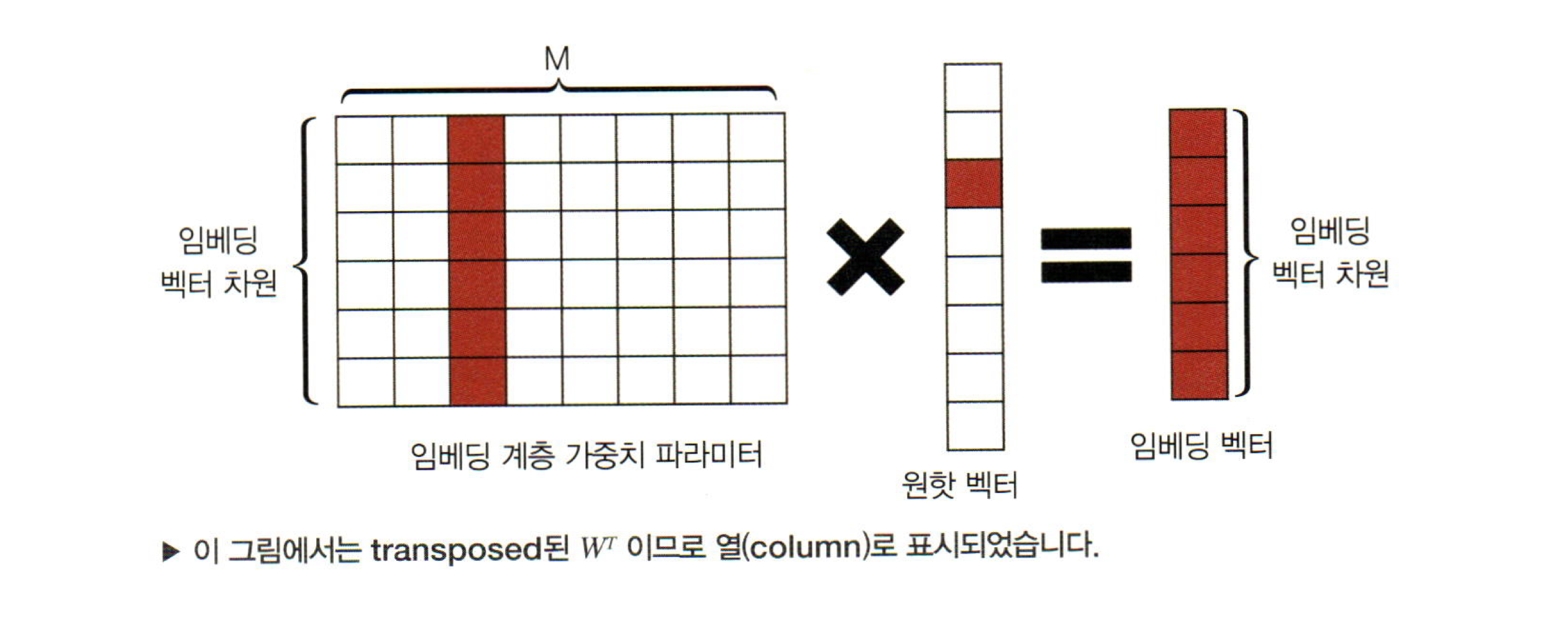
임베딩 벡터 차원은 결국 단어를 표현하는 원핫벡터와 내적하여, 결국 해당 단어의 임베딩 벡터와 같게됩니다.
사전 훈련한 단어 임베딩 벡터를 입력값을 치환하여 사용하게 되면, 임베딩 레이어의 가중치 파라미터는 최적화 되지 않게됩니다. 즉 임베딩 레이어는 갱신이 되지 않고 코드로는
optimizer = optim.Adam(model.softmax_layer.parameters() + model.rnn.parameters())로 임베딩 레이어의 파라미터를 제외하고 갱신해야하는 파라미터를 등록해줄 수 있습니다.
이후 느린 학습으로 천천히 임베딩 벡터를 갱신해주는 경우도 있습니다.
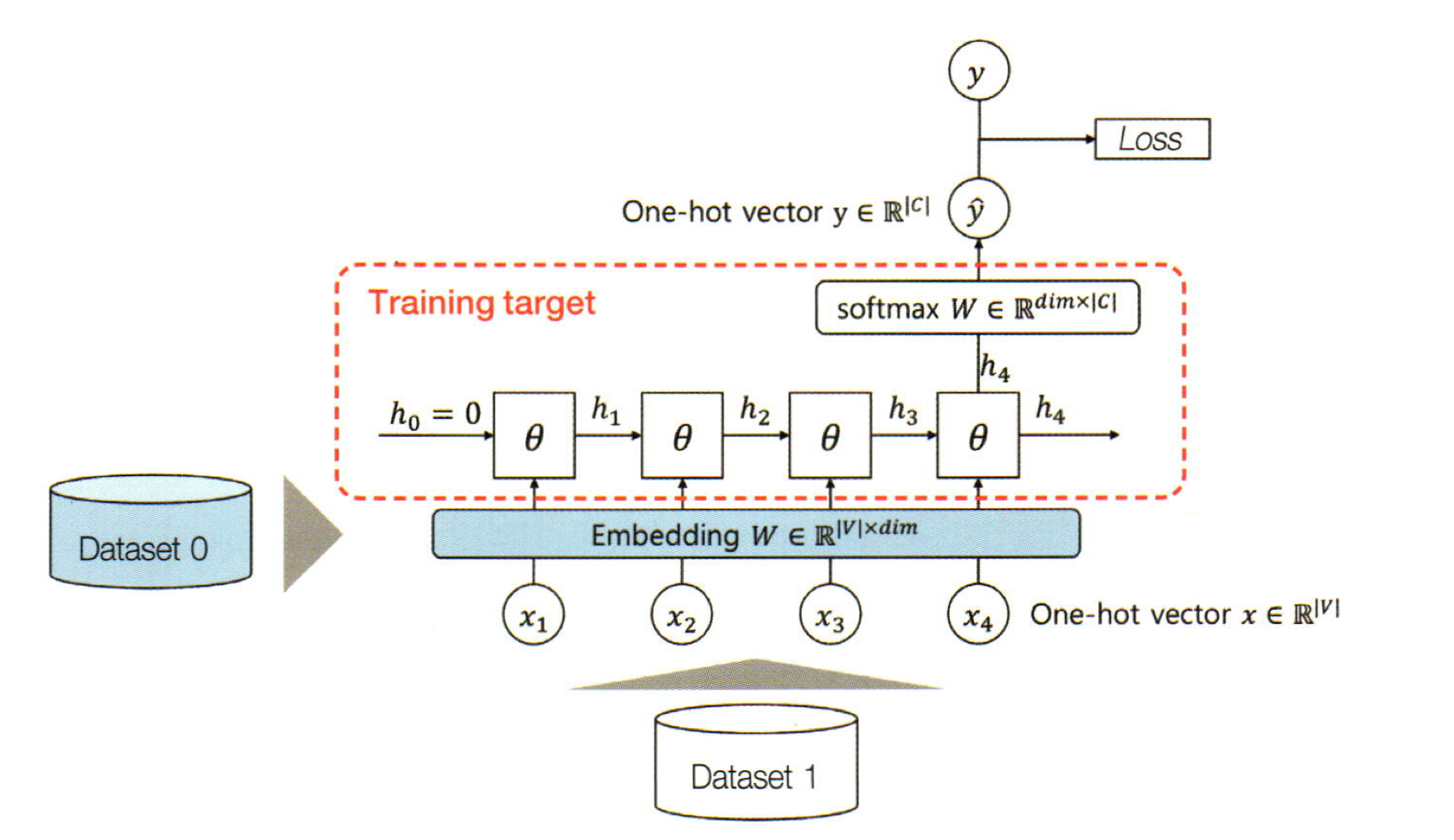
하지만 이러한 방식의 전이학습은 그다지 큰 효과를 거둘 수 없었습니다.
왜냐하면 기존의 Skip-gram이나 glOVe 알고리즘은 단어를 잠재 공간에 임베딩할 수 있었지만, 그 알고리즘은 문장에 함께 출현하는 단어들을 예측하는데 기반합니다. 즉, 임베딩된 정보는 매우 한정적입니다. 특히 해당 알고리즘들의 목적 함수는 우리가 실제 수행하려는 문제를 해결하기 위한 목적 함수와 매우 다를 것이기 때문에 우리에게 필요한 특징을 반영하기 어렵습니다.
예를 들어 Play라는 단어는 문맥에 따라, 연주하다, 재생하다, 놀다등으로 해석될 수 있습니다.
이번에 알아볼 bert는 위 문제점을 어느정도 해결한 방법론으로 볼 수 있습니다.
Bert
사실 bert에 대해 더욱 깊이 이해하기 위해서는 이전에 나온 모델인 ELMO모델에 대해 이해해야합니다. 하지만 이번 글에서는 bert에 집중하고자 합니다.
bert의 특징으로는 파인 튜닝이 있습니다. 즉, 훈련된 언어 모델에 약간의 계층을 추가하여, 특정 문제에 맞는 신경망을 만들수 있습니다.
bert는 MLM을 통해 양방향 시퀀셜 모델링을 성공적으로 수행합니다. 또한 한개의 문장만을 모델링하는 대신 두개의 문장을 동시에 학습하도록합니다.
MLM(Masked Language Model)
MLM은 전체 문장에서 일부 단어를 마스킹하고, 해당 마스킹된 단어를 모델의 입력으로 주어졌을때, 마스킹된 단어를 예측하는 task입니다.
이 과정을 거치면 문장의 의미를 모델링하는데 큰 도움이 됩니다. 마치 우리가 영어를 배울때 빈칸에 들어갈 단어를 공부하는 것과 같습니다.
만약 질의응답 챗봇의 경우 입력은 여러 개의 문장으로 주어지게되고, 입력으로 주어진 문장의 의미를 파악해야하기 때문에 문장과 문장사이의 관계를 딥러닝에 알려줘야합니다. 하지만 기존의 언어 모델링으로는 어려운 task였습니다. 하지만, MLM을 통해 문장의 의미를 어느정도 학습할 수 있게되었습니다.
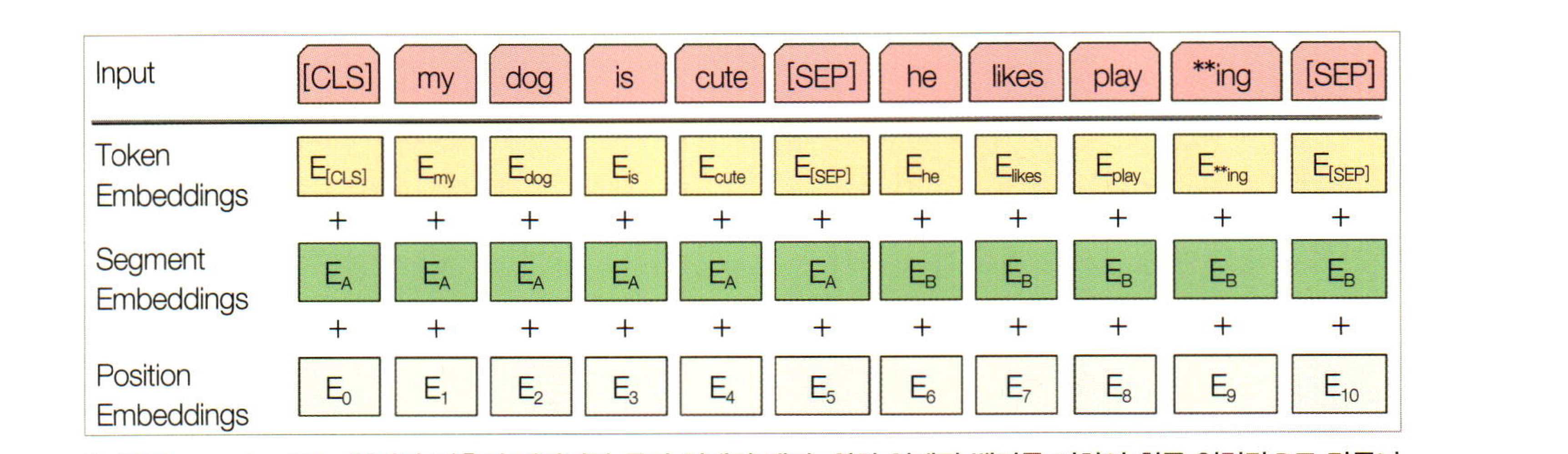
그림과 같이 두 문장을 입력으로 주었을때 각 time-step에는 Token Embedding, Segment Embedding , Positional Embedding를 더하여 최종 입력값으로 만듭니다. 또한 문장의 끝에는 SEP라는 토큰을 두어 문장 사이의 경계를 알려주고, CLS토큰을 통해 분류 레이블을 예측하는 공간을 마련합니다.
Token Embedding은 사람이 사용하는 단어를 딘러닝 모델들이 이해할 수 있는 고차원 벡터로 변환하는 역할을 합니다.
Segment Embedding은 쉽게 말하면 문장 전체의 대한 임베딩입니다. 예를 들어 다음 문장을 예측하는 문제를 생각해볼게요. 2개의 Text를 한번에 입력 받아야 하는데요. 무엇이 첫번째 Text 이고, 무엇이 두번째 Text 인지를 모델에게 알려주는 정보입니다.
Positional Embedding 입니다. 이는 입력된 데이터에서의 순서를 의미합니다. Transformer는 입력 데이터의 순서를 고려하지 않으므로, 순서를 구분해주기 위한 Positional Encoding이 필요합니다. 이는 Transformer에서와 동일한 방법으로 적용해줍니다.
이 과정을 통해 입력된 두번째 문장이 다음에 와야하는 문장인지 아닌지를 분류해낼 수 있게됩니다.
즉 두 문장사이의 관계를 학습할 수 있게 됩니다.

위 그림과 같이 the man went to the store이라는 문장 다음에는 he bought a gallon of milk라는 문장이 와야한다는 것을 학습하게 됩니다.
bert는 어찌보면 굉장히 단순한 방법론이지만, 아직까지 꽤 좋은 성능을 보여줍니다.
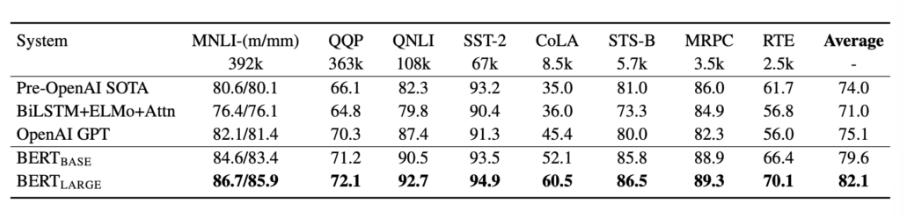
해당 글에서는 정말 간단하게 정리하는 식으로 글을 적었지만, transfomer만 이해한다면 위의 내용만으로 어느정도 간단하게 bert에 대해 접근할 수 있습니다.
직접적인 논문을 확인하려면 아래 링크에 들어가면 됩니다.
