1. Introduction
SBERT는 BERT를 개선하여, 문장의 의미를 반영하는 임베딩, 즉 문장의 임베딩을 구하게끔 설계되었습니다.
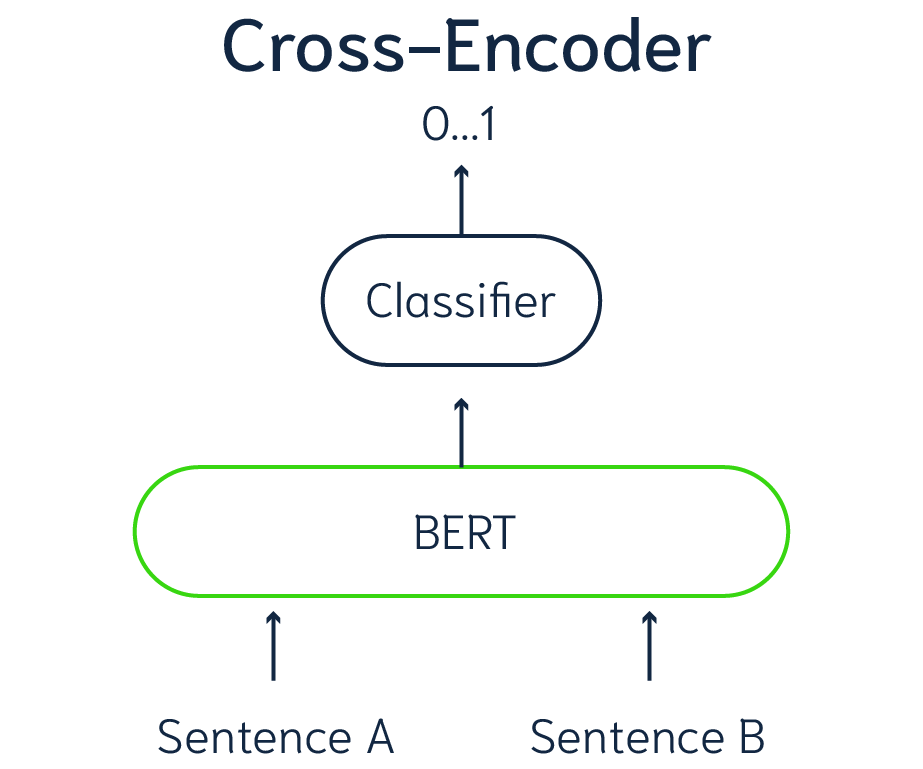
기존의 BERT는 cross-encoder를 사용합니다. 두 문장이 하나의 쌍으로 network에 들어가 타겟값을 예측하는 형태를 가집니다.
cross-encoder의 장점은 두 문장에 존재하는 모든 토큰들 간의 어텐션 연산이 수행되기 때문에 두 문장의 관계를 파악할 수 있다는 것입니다.
그러나 이런 설정은 많은 문장이 들어가게 되면 연산량이 매우 커지게 됩니다. 약 10,000개의 문장을 입력으로 넣어주게 되면, (10,000 * (10,000 - 1)) / 2 = 49,995,000번의 연산을 하게 됩니다. 이는 V100 GPU를 활용했을때 65시간이 걸리게 됩니다.
또한 BERT 구조의 다른 단점으로는 입력으로 들어간 두 문장의 임베딩이 서로 독립적이지 않다는 것입니다. 즉 각각의 문장의 정보가 담겨있는 임베딩이라고 부를 수 없다는 것입니다.
이를 해결하기 위해 유사한 문장끼리 매핑하기 위한 노력을 했지만 이런 방식은 좋은 성능을 내지 못했습니다.
SBERT는 이런 BERT의 문제점을 해결하기 위해 개발되었습니다.
1-2. Sentence Embbeding
BERT의 문장 임베딩을 문장 임베딩을 얻는 방법은 3가지가 존재합니다.
- CLS토큰의 출력 벡터를 문장 벡터로 간주
- output의 평균 풀링을 수행한 벡터를 문장벡터로 간주(default)
- output의 Max 풀링을 수행한 벡터를 문장벡터로 간주
이때 평균 풀링을 하느냐와 맥스 풀링을 하느냐에 따라서 해당 문장 벡터가 가지는 의미는 다소 다른데, 평균 풀링을 얻은 문장 벡터의 경우에는 모든 단어의 의미를 반영하는 쪽에 가깝다면, 맥스 풀링을 얻은 문장 벡터의 경우에는 중요한 단어의 의미를 반영하는 쪽에 가깝습니다.
2. SBERT Model
SBERT의 모델은 크게 3가지가 존재합니다. 분류 데이터셋에 활용되는 방법과, 회귀에 활용되는 방법, 그리고 triplet에 활용되는 방법입니다.
2-1. Classfication Objective Funtion
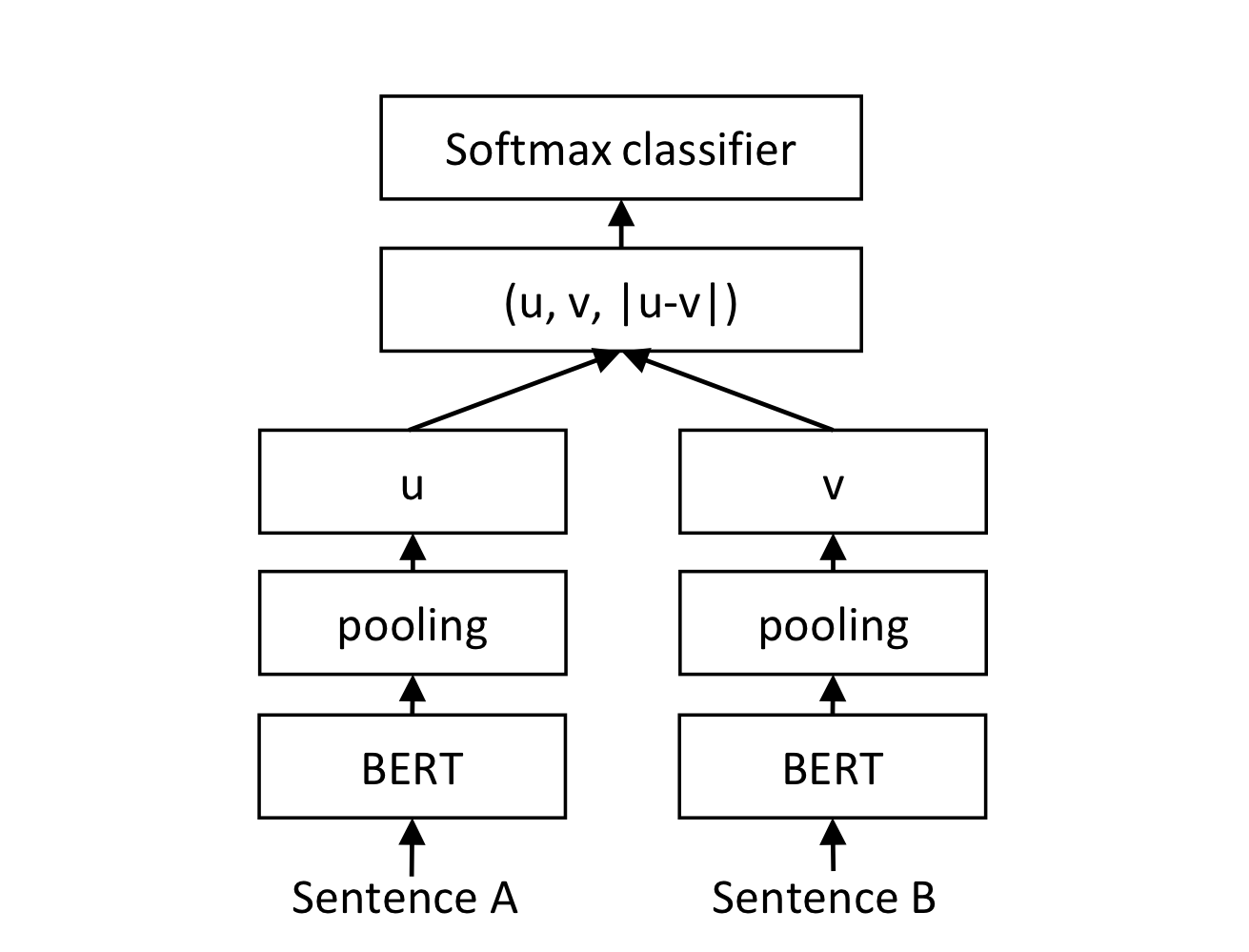
classfication Objective Fuction에선 bert에서 나온 결과를 위의 3가지 방법 중 하나로 문장벡터를 도출해내고, 그렇게 해서 나온 , 그리고 이 둘의 차이인 를 concatenate 해줍니다. 이때 는 두 개의 임베딩 차원 사이의 거리를 측정해서 유사한 것끼리는 가깝게, 그렇지 않은 것은 멀게 만들어줍니다.
- : the dimesnsion of the sentence embeddings
- : the number of labels
- cross-entropy loss
2-2. Regression Objective Funtion
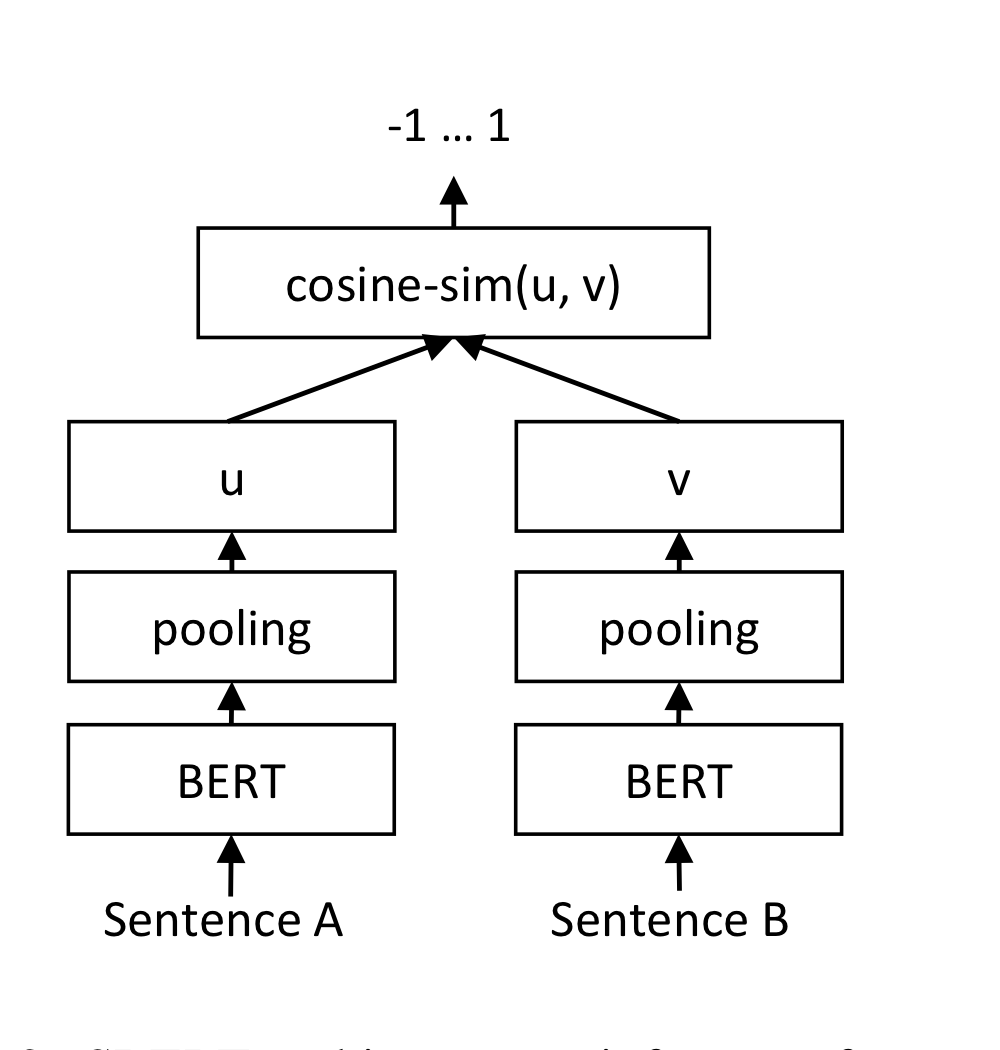
두 문장 임베딩 사이의 코사인 유사도를 구하고, MSE LOSS를 활용합니다.
2-3. Triple Objective Funtion
- : the sentence embeddings for
anchor sentece , positive sentence , negative sentence 을 두고 와 는 작기를 기대하고, 와 은 크기를 기대합니다. 이때 마진 두어 적어도 만큼 의 거리가 와 보다 가깝도록 할 수 있습니다. 기본 값은 입니다.
3. Evaluation - Semantic Textual Similarity
3-1. Training Data
- SNLI
- 570,000 sentence pairs
- label : contradiction, eintailment, neutral
- MNLI
- 430,000 sentence pairs
- spoken and written text
- batch_size = 16
- optimizer = Adam
- learning_rate = 2e-5
3-2. Unsupervised STS(Semantix Textual Similarity)
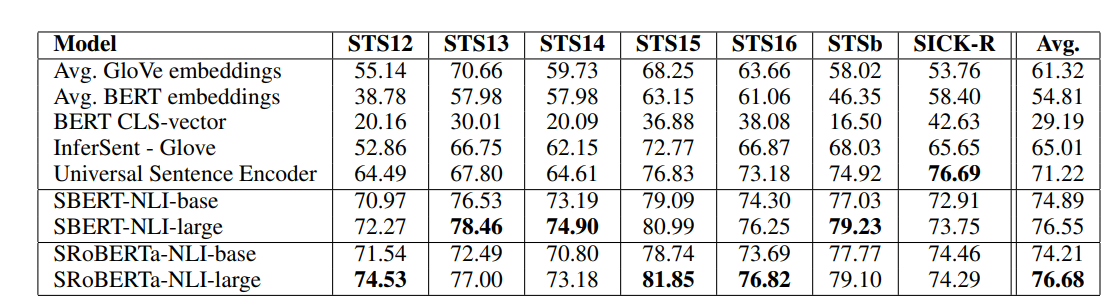 두 문장의 의미적 연관성이 0~5로 라벨링 된 데이터를 활용하였고, 평가지표로 문작 임베딩과, 라벨링 간의 Spearman's rank correlation을 활용했고, 유사도로는 cosine-similarity를 활용했습니다.
두 문장의 의미적 연관성이 0~5로 라벨링 된 데이터를 활용하였고, 평가지표로 문작 임베딩과, 라벨링 간의 Spearman's rank correlation을 활용했고, 유사도로는 cosine-similarity를 활용했습니다.
결과를 보면 BERT의 output의 평균을 문장 벡터로 사용한 경우 54.51, CLS 토큰을 사용한 경우 29.19로 GloVe 임베딩을 활용한 경우보다 낮은 성능을 내었습니다.
반면 오직 위키피디아와 NLI data를 활용한 경우 평균 73.89, SRoBerta-NLI-base의 경우 74.21로 높은 성능을 내었습니다.
3-3. Supervised STS
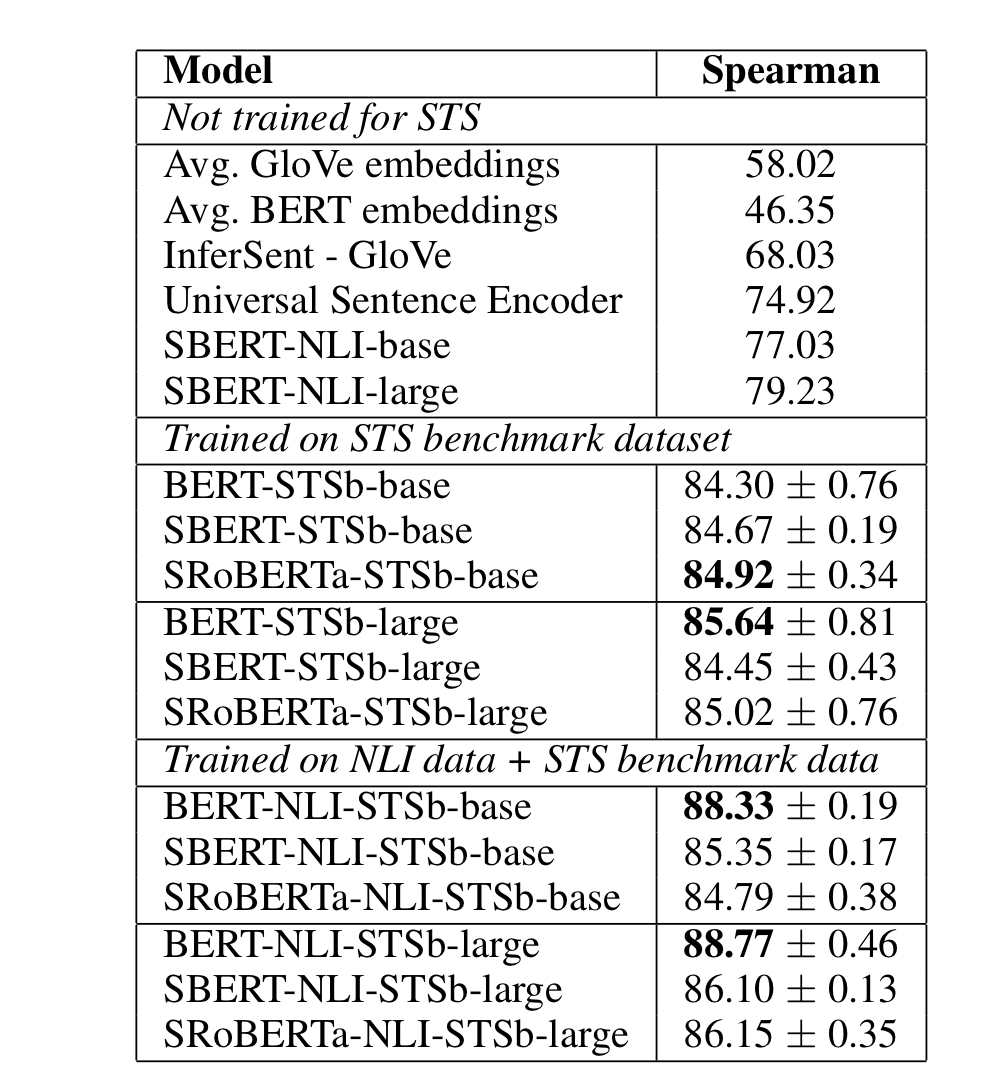
supervised STS의 경우 BERT와 SBERT모두 NLI에 fine-tuning한 경우 성능이 좋습니다.
4. Ablation Study
논문에서 성능에 영향을 주는 요소를 알아보기 위해 각각의 pooling strategies를 모델에 적용하였고, SNLI와 MNLI 데이터셋을 기반으로 한 분류와, STS 벤치마크 데이터셋을 기반으로 한 회귀에 적용하였습니다.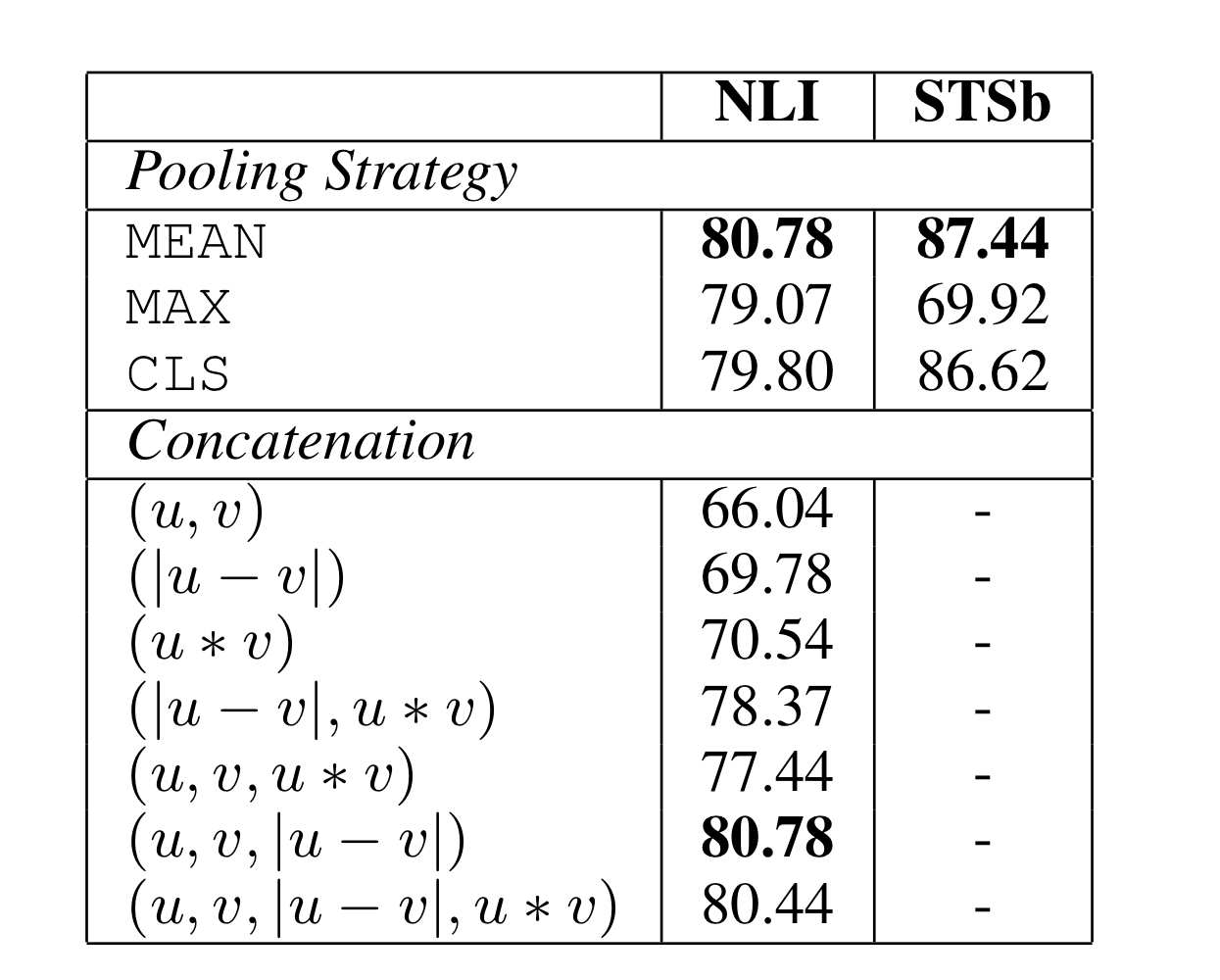
그 결과로 분류의 문제에서는 pooling strategy에선 낮은 영향력을 보였고, concatenation이 오히려 큰 영향을 주었습니다. 오히려 를 concat한 경우 결과가 더 안좋게 나왔고, 가 중요한 요소로 나왔습니다.
회귀의 경우 오히려 pooling strategy가 큰 영향을 주는 것으로 나타났다.
5. Conclusion
기존의 BERT는 일반적인 유사도와 함께 사용하기에는 부적절하며, STS의 각각 데이터셋에 해당하는 task는 오히려 GloVe보다 성능이 낮았습니다.
SBERT의 경우 다양한 벤치마크에서 문장 임베딩의 상당한 개선을 가지고 왔고, 효율적으로도 BERT로 65시간을 걸리는 시간역시, SBERT로는 약 5초로 단축할 수 있었습니다.
6. 참조
https://velog.io/@chaujin00/SBERT-%EB%85%BC%EB%AC%B8%EB%A6%AC%EB%B7%B0
