
exploration을 진행하다보니
인공지능 모델을 훈련시키고 사용할 때,
일반적으로 입력은 0 ~ 1 사이의 값으로 정규화 시켜주는 것이 좋습니다.
라는 말을 봤는데, 그 말에대한 설명이 없어 개인적으로 공부한 내용을 정리한다.
핵심만 먼저 말하자면, 정규화&표준화가 필요한 이유는 기준을 설정하고 그 기준내에서 각 데이터들을 평가하기 때문에 비교가 편하다는 것이라고 생각한다.
머신러닝을 하다보면 기본적으로 많은 양의 데이터를 처리하게 된다. 그리고 그 데이터안에 target과 관련있는 특성(feature)을 뽑아낸다.
예를 들어, 오늘 입을 옷을 결정할 때 그날의 온도, 습도, 날씨, 약속의 유무 등을 따지는 것과 같다.
그럼 온도, 습도, 날씨는 ℃, F 등 특성의 단위도 다르고 그 범위도 달라 직접적으로 비교할 수 없다.
내가 토익(990만점) 400점이고, 넌 영어(100점만점) 90점이니까 내가 더 공부를 잘하네? 라고 할 수 없는 듯이 말이다.
그래서 각 특성들의 단위를 무시하고 값으로 단순 비교할 수 있게 만들어 줄 필요가 있다. 그것이 우리가 정규화/표준화를 진행하는 이유다. 정규화/표준화가 해주는 것을 특성 스케일링(feature scaling) 또는 데이터 스케일링(data scaling)이라고 한다.
또한 가장 중요한 이유는 scale의 범위가 너무 크면 노이즈 데이터가 생성되거나 overfitting이 될 가능성이 높아지기 때문이다.
Q. 그렇다면 정규화와 표준화의 차이는 무엇일까?
- 정규화(Normalization)
+ 값의 범위(scale)을 0 ~ 1사이의 값으로 바꿔주는 것.
+ 학습 전에 scaling하는 것
- 머신러닝에서 scale이 큰 feature의 영향이 비대해지는 것을 방지
- 딥러닝에서 Local Minima에 빠질 위험 감소(학습 속도 향상)
+ scikit-learn에서 MinMaxScaler사용
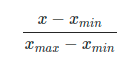
- 표준화(Standardization)
+ 값의 범위(scale)를 평균 0, 분산 1이 되도록 바꿔주는 것.
+ 학습 전에 scaling하는 것
- 머신러닝에서 scale이 큰 feature의 영향이 비대해지는 것을 방지
- 딥러닝에서 Local Minima에 빠질 위험 감소(학습 속도 향상)
+ 정규분포를 표준정규분포로 변환하는 것과 같음
+ scikit-learn에서 StandardScaler

정규화 표준화 사진으로 한눈에 보기
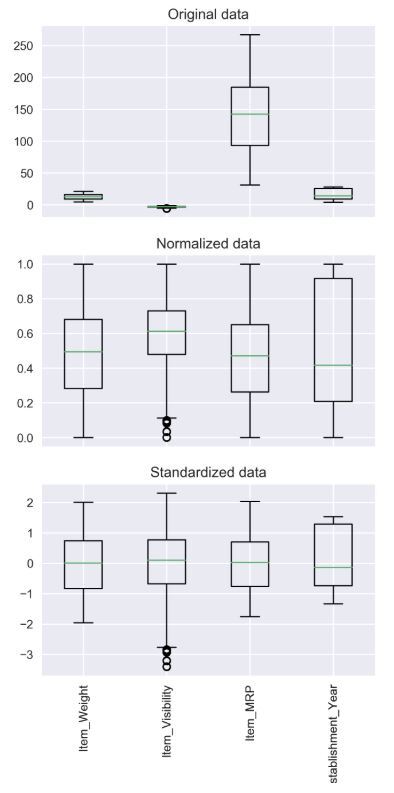
출처 : https://bskyvision.com/849
추가) Regularization
+ 정규화로 불리기도 함.
+ weight를 조정하는데 규제(제약)를 거는 기법
+ Overfitting을 막기위해 사용함
- L1 regularization, L2 regularizaion 등의 종류가 있음
- L1: LASSO(라쏘), 마름모
- L2: Lidge(릿지), 원
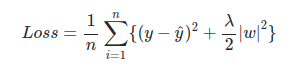
각 데이터마다 정규화/표준화 어떤 것을 진행해야 좋을까 라는 생각이 들텐데, 이는 2개를 비교해본 후 결정해야한다.
모델마다 선택하는 것이 달라지기 때문에 꼭 돌려보고 선택하자.
참고 자료
