이번 실습시, 중요한 개념으로 seq2seq, RNN, LSTM을 알려주는데, 각 개념들이 이해되지 않아서 다시금 정리해본다.
1. seq2seq
- 번역기에서 대표적으로 사용되는 모델
- 동작구조
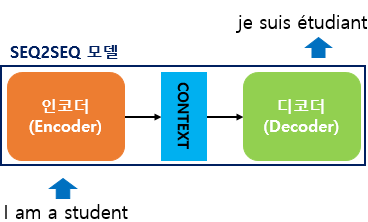
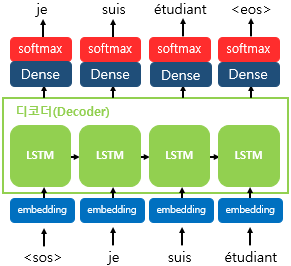
- 크게 인코더와 디코더라는 모듈로 구성됨
+ 인코더 : 입력문장의 모든 단어들을 순차적으로 입력받은 후 마지막에 단어 정보들을 압축해서 하나의 벡터(이를 컨텍스트 벡터_context vextor라고 함)로 만들어 디코더로 전송함
+ 디코더 : 컨텍스트 벡터를 전송받아 순차적으로 출력함
-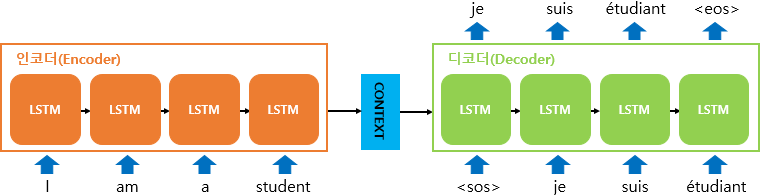
+ 디코더는 기본적으로 RNNLM(RNN Language Model)로 시작 심볼인<sos>가 입력되면 다음 단어를 출력하고 이를 다시 입력으로 받아 다음을 출력하는 방식으로 반복됨
+ 훈련 과정에서는 디코더에게 인코더가 보낸 컨텍스트 벡터와 실제 정답인 상황인<sos>je suis étudiant를 입력 받았을 때, je suis étudiant<eos>가 나와야 된다고 정답을 알려주면서 훈련
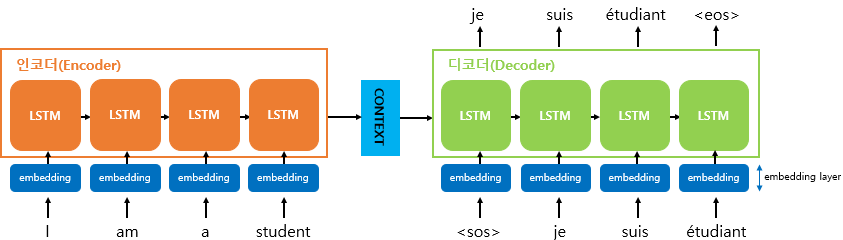
+ 인코더와 디코더는 각각 RNN 아키텍처 구조를 갖고 있어 결국 2개의 RNN 아키텍쳐를 갖고있는 것
- 하나의 RNN 셀은 각각의 시점(time step)마다 두 개의 입력을 받음
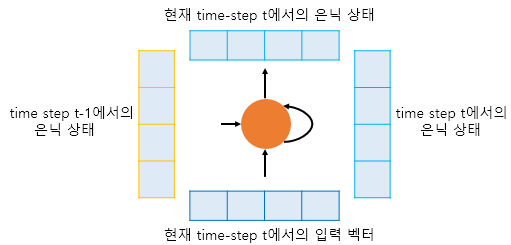
- 현재 시점(time step)을 t라고 할 때, RNN 셀은 t-1에서의 은닉 상태와 t에서의 입력 벡터를 입력으로 받고, t에서의 은닉 상태를 만듦
- 이 은닉 상태의 값은 가중치나 h로 표현을 많이 함(밑에도 나옴). 상기 그림에서는 실제 단어단어가 들어갈때마다 가중치의 값이 넘어가는 것을 모델 하나로 고정해두고 그게 갱신되는걸 회전하는 모양으로 표현함
- 그래서 현재 시점 t에서의 은닉 상태는 과거 시점의 동일한 RNN 셀에서의 모든 은닉 상태의 값들의 영향을 누적해서 받아온 값이 되며, 이를 인코딩 마지막에선 디코딩으로 넘겨주고, 디코딩에선 이 넘어온 값을 이전 은닉상태의 값으로 받아 사용함
- 마지막엔 소프트 맥스 함수를 사용하여 가장 높은 가능성을 가진 단어를 뽑아냄
2. 바닐라 RNN (RNN)
- 가장 기본적인 RNN 형태(케라스에서는 SimpleRNN)
- 출력 결과가 이전의 계산 결과에 의존한다는 것 = 이번 출력 결과는 다음번 결과에 영향을 줌
- 비교적 짧은 시퀀스(sequence)에 대해서만 효과를 보이는 단점이 있음
+ 시점(time step)이 길어질 수록 앞의 정보가 뒤로 충분히 전달되지 못하는 현상이 발생하기때문
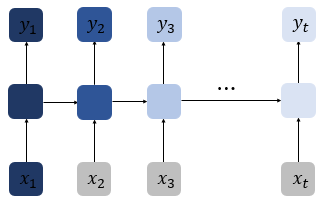
+ 상기 그림에서 색이 짙어질 수록 처음의 정보가 손실되어가는 과정을 표현 - 다음 단어 예측시 중요한 힌트인 단어가 앞에 있을 수 있는데, 충분한 기억력을 갖지 못하면 다음 단어를 이상한 단어로 예측하게 됨
= 이를 장기 의존성 문제(the problem of Long-Term Dependencies) 라고 함 - 동작 구조
+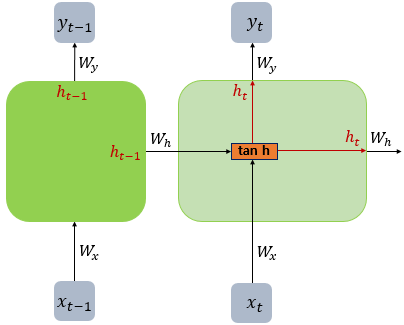
- 이 책에서는 RNN 계열의 인공 신경망의 그림에서는 편향 b 를 생략함
- 위의 그림에 편향 를 그린다면 xt옆에 tanh로 향하는 또 하나의 입력선을 그리면 됨
- 바닐라 RNN은 xt와 h(t-1)이라는 두 개의 입력이 각각의 가중치와 곱해져서 메모리 셀의 입력이 됩니다.
- 그리고 이를 하이퍼볼릭탄젠트 함수의 입력으로 사용하고 이 값은 은닉층의 출력인 은닉 상태가 됨
3. LSTM(Long Short-Term Memory)
- 동작 구조
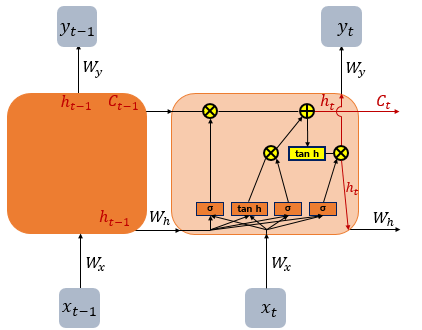
- 바닐라 RNN의 단점을 보완한 RNN의 일종을 장단기 메모리(Long Short-Term Memory)라고 하며, 줄여서 LSTM이라고 힘
- LSTM은 은닉층의 메모리 셀에 입력 게이트, 망각 게이트, 출력 게이트를 추가하여 불필요한 기억을 지우고, 기억해야할 것들을 정함
- 요약하면 LSTM은 은닉 상태(hidden state)를 계산하는 식이 전통적인 RNN보다 조금 더 복잡해졌으며 셀 상태(cell state)라는 값을 추가한 것
- 셀 상태를 Ct를 사용하여 표현하며, 이전 셀이 다음 셀에 영향을 주는 것엔 변함이 없음. 이전 시점의 셀 상태가 다음 셀 상태를 구하기 위한 입력으로 사용됨
- 은닉 상태의 값과 각 셀의 상태를 구하기 위해 3개의 게이트(삭제 게이트, 입력 게이트, 출력 게이트)를 사용하며, 이는 모두 시그모이드 함수를 포함하고 있음
- 따라서 0 - 1 사이의 값을 출력하여 그 값으로 게이트를 조절함
- 3개의 게이트 설명
1) 입력 게이트
+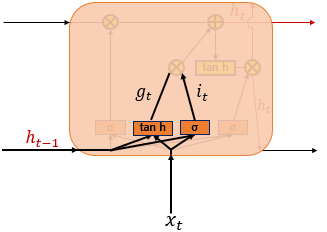
+ it, gt에 각각 시그모이드와 tanh를 사용한 가중치, 입력치, 편향 값이 입력됨
+ 따라서 it는 시그모이드 함수에 의해 0 ~ 1 사이의 값을 갖고, gt는 tanh에 의해 -1 ~ 1사이의 값을 갖게 됨. 이 값에따라 기억할 정보의 양을 정함
2) 삭제 게이트
+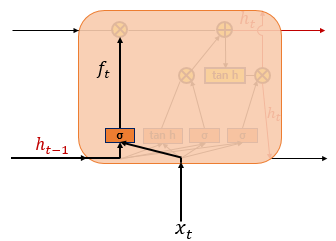
+ 현재 시점 t의 x값과 이전 시점 t-1의 은닉 상태가 시그모이드 함수를 지남
+ 시그모이드 함수를 지나면 0과 1 사이의 값이 나오게 되는데, 0에 가까울 수록 정보의 삭제가 많은 것이고 1에 가까울 수록 온전한 정보를 가지고 있는 것
3) 셀 상태
+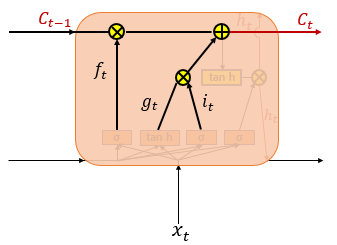
+ gt, it의 값을 원소별 곱(entrywise product)을 진행하여 기억할 내용을 값으로 처리함
+ 이후 삭제 게이트에서 나온 결과 값과 더함. 이것이 현재 t시점의 셀 상태이며, 이 값은 다음 셀인 t+1의 LSTM으로 전달됨
+ 삭제게이트 값인 ft가 0이라면, 입력게이트에 들어온 값이 현재 셀상태 값인 Ct값을 결정함(이를 삭제게이트를 닫고, 입력게이트를 연 상태로 표현함)
+ 반대로 it가 0이라면, Ct는 Ct-1의 값에의해서만 결정됨 (이를 입력게이트를 닫고, 삭제게이트만 연 상태로 표현함)
4) 출력게이트와 은닉상태란?
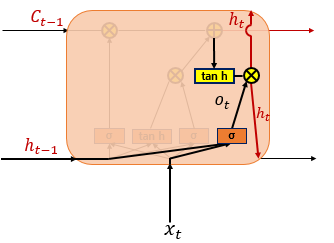
+ 출력게이트는 현재 시점 t의 x값과 이전 시점 t-1의 은닉 상태가 시그모이드 함수를 지난 값
+ 이 값은 t시점에서 은닉상태를 결정하는 일에 쓰이며, 이후 셀상태의 값이 tanh함수를 지나며 -1 ~ 1사이의 값으로 변하게 되는데 이 값과 출력게이트의 값을 연산하며 값이 걸러지는 효과가 발생함
+ 이렇게 걸러지는 상태를 은닉상태라하며, 이 값은 출력층으로 향하게 됨

차보의 Data Engineer 도전기♥ (근데 기록을 곁들인)