Paper : Barbershop: GAN-based Image Compusiting using Segmentation Masks
Abstract
배경
- 여러 이미지의 feature를 잘 혼합하는 것은 여러 요인들로 인해 어려운 문제
- 최근 GAN 연구로 사실적인 머리카락이나 얼굴은 잘 생성하지만, 하나의 이미지로 그럴듯하게 결합하는 것은 여전히 어려움
제안
- GAN inversion 기반으로 헤어스타일 변환을 위한 이미지 블렌딩에 새로운 솔루션 제시
- 세부 정보를 보존하고 공간 정보를 인코딩하는 1) 새로운 latent space를 제안하고, 2) segmentation mask에 맞게 이미지를 수정할 수 있는 새로운 GAN-embedding 알고리즘 제안
결과
- 본 연구에서 제안한 새로운 표현은 여러 참조 이미지에서 점과 주름과 같은 detail과 같은 시각적 특성을 전송할 수 있고, latent space에서 이미지 혼합을 수행하기에 일관성 있는 이미지를 합성
- 다른 접근 방식에 존재하는 blending artifact를 피하고 전역적으로 일관된 이미지를 찾음
3. METHOD
Overview
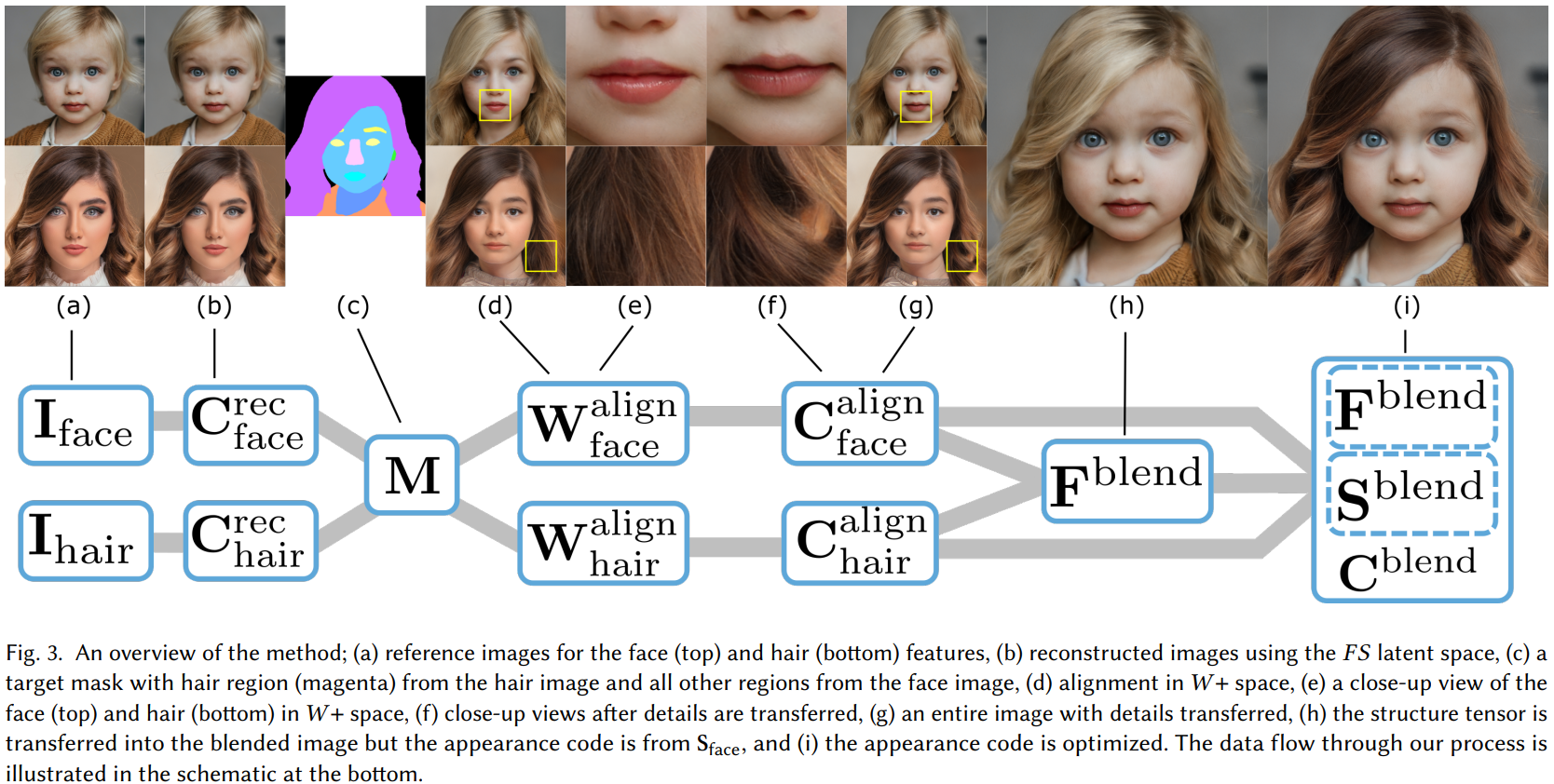
Reference image에서 머리카락이나 얼굴과 같은 의미 있는 영역들을 고르고 각 영역을 혼합하여 합성 이미지를 만든다.
→ reference image는 자동 분할하고, target semantic segmentation mask image 을 사용한다.
헤어스타일 전송을 위해 한 이미지에서 헤어스타일을 복사하고 semantic-category에서 다른 이미지를 사용한다.
→ reference image set 는 각각 target mask에 정렬된 다음 혼합되어 새로운 영상을 형성
Contribution
- Output : Reference image 의 스타일을 갖는 합성 이미지
- 혼합 이미지에 대한 latent code를 찾음으로써 전통적인 아티팩트인 '혼합 영역의 경계에서 이미지 블렌딩' 아티팩트를 피함
- StyleGAN2 architecture 사용 및 II2S 임베딩 알고리즘을 확장
- II2S : StyleGAN2 의 18개 affine 스타일 블록의 입력을 𝑊+ latent code로 사용
- latent code 를 사용하여 이미지 임베딩
- 임베딩의 용량을 늘리고 이미지 세부 정보 캡처
- structure tensor : StyleGAN2의 7번째 레이어에 있는 스타일 블록의 출력
- appearance code : 나머지 스타일 블록에 대한 입력으로 사용
- 공간은 얼굴 세부 사항을 구성할 수 있는 더 많은 자유도를 제공
주요 단계
① Embedding
1. Reference image 를 임베딩하여 Latent code 를 찾음② Alignment
2. Reference image 를 분할 알고리즘을 통해 자동적으로 분할하여 target mask 생성하거나 수동 생성
3. Reference image 와 유사하면서도 target mask 과 일치하는 이미지의 임베딩인 latent code 를 찾음③ Blending
4. 결합 structure tensor 는 의 분할 영역 를 복사하여 형성
5. Appearance code 에 대한 혼합 가중치로 appearance code 는 정렬된 이미지의 모양을 혼합하며, 혼합 가중치는 새로운 masked-appearance loss function을 사용하여 발견
Data preprocessing
Reference image는 두 눈과 입 사이의 거리를 기반으로 이미지를 잘라내고, 이미지의 크기를 조정하는 얼굴을 기반으로 정렬하는 facial landmark detection을 통해 기본 1024 x 1024 이미지로 전처리된다.

① Embedding
이미지를 혼합하기 전 각 이미지를 target mask 에 정렬해야 한다.
- Reconstruction : 입력 이미지 를 재구성하기 위해 latent code 를 찾음
- Alignment : 생성된 이미지와 target mask 사이의 cross-entropy를 최소화하는 latent code 를 찾음
Reconstruction
- 목표 : 입력 이미지 를 잘 재구성하는 를 찾는 것
- : reconstruction the image
- : StyleGAN2 generator
- 초기화 : StyleGAN2의 II2S를 통해 얻은 + 잠재 공간으로부터 잠재 코드 를 초기화
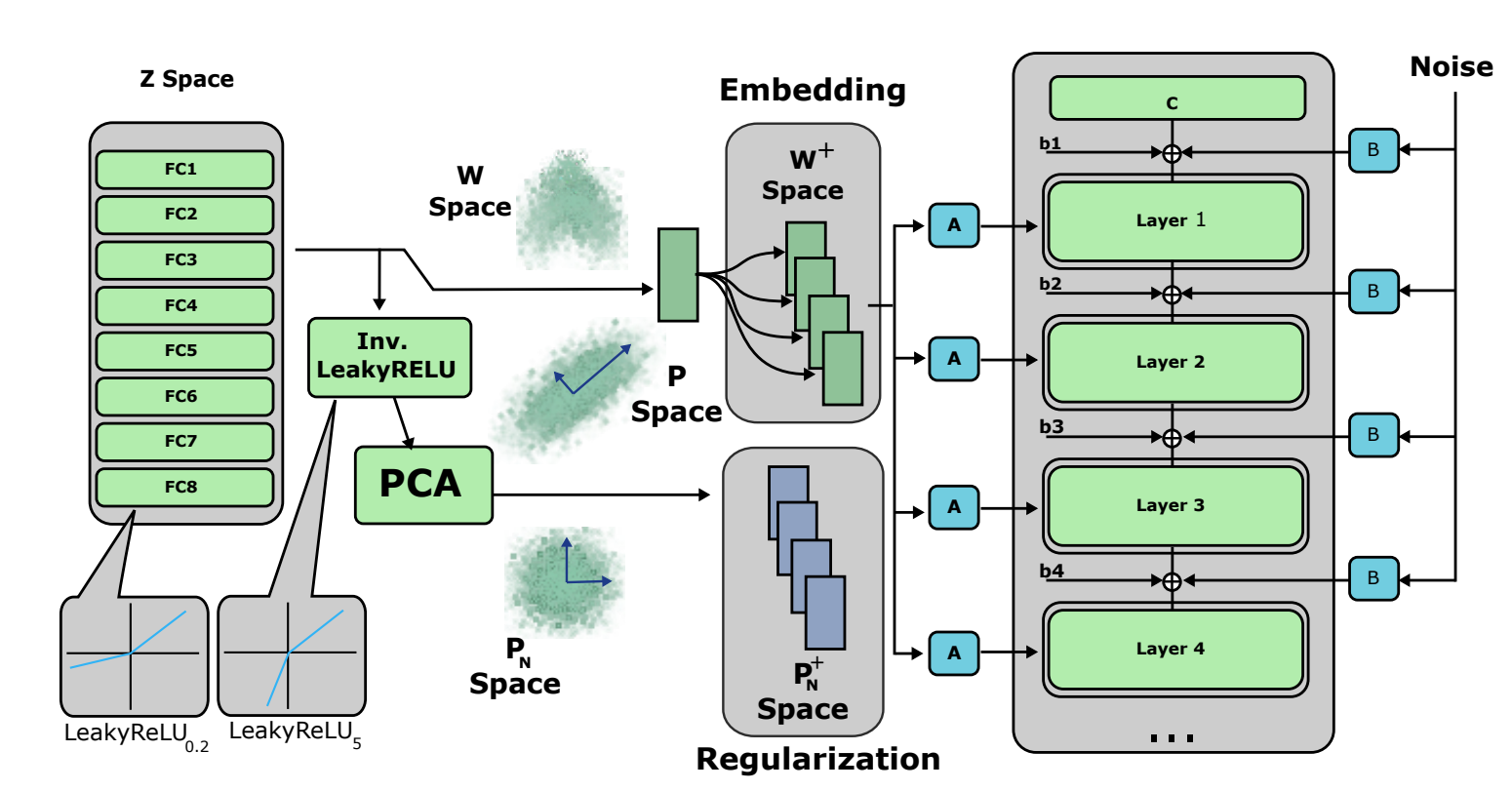
II2S
기존 StyleGAN2의 잠재 공간 에는 512개의 구성 요소 로는 일반적인 detail은 표현 가능하지만, 얼굴의 특정 detail(점, 주름, 속눈썹의 정확한 위치)을 인코딩하는 것은 불가능했다. 이를 개선하기 위한 + 공간과 II2S의 사용은 latent space의 표현성을 향상시키지만, 재구성에는 불충분하다. 따라서 본 연구에서는 향상된 재구성을 위해 공간이라는 새로운 latent space에 이미지를 임베딩한다.

Latent code를 부분적으로 사용하여 얼굴의 특정 detail을 포착한다. Latent code 는 latent code + 보다 더 많은 capacity를 가지며, 각 reference image를 재구성하기 위해 초기값으로 + latent code를 사용하여 gradient descent를 적용한다.
- structure tensor : generator의 블록 중 하나의 출력(본 연구에서는 m=7)
- appearance code : 나머지 개의 블록
Latent code 는 를 최소화하면서 기존 +()와 최대한 비슷한 latent code 를 찾는 방향으로 최적화된다.
Embedding loss
이때, 구현된 코드 상으로는 총 4개의 loss가 존재하는 것을 확인할 수 있다.
if self.opts.verbose:
pbar.set_description(
'Embedding: Loss: {:.3f}, L2 loss: {:.3f}, Perceptual loss: {:.3f}, P-norm loss: {:.3f}, L_F loss: {:.3f}'
.format(loss, loss_dic['l2'], loss_dic['percep'], loss_dic['p-norm'], loss_dic['- L2 loss
torch.nn.MSELoss()를 통해 를 재구성한 이미지와 Ground truth 간의 차이를 비교한다. - P-norm loss
p_norm_loss = self.net.cal_p_norm_loss(latent_in)
이 loss를 사용하면 벡터의 크기가 작아지는 효과가 있으며 이는 입력 벡터의정규화 및 크기 제어 관점에서 모델의 학습을 돕는 역할을 할 수 있다.
def cal_p_norm_loss(self, latent_in):
latent_p_norm = (torch.nn.LeakyReLU(negative_slope=5)(latent_in) - self.X_mean).bmm(
self.X_comp.T.unsqueeze(0)) / self.X_stdev
p_norm_loss = self.opts.p_norm_lambda * (latent_p_norm.pow(2).mean())
return p_norm_loss- Perceptual loss
기본적으로 이미지 간의 perceptual 손실을 측정하는 지표로, 이미지 간의 비교에 사용된다. 본 연구에서는 기존 인풋 이미지를 resizing한 ref_im_L과 generator를 통해 생성한 후 downsampling한 gen_im_L을 비교한다.
ref_im_L = ref_im_L.resize((256, 256), PIL.Image.LANCZOS)
gen_im, _ = self.net.generator([latent_in], input_is_latent=True, return_latents=False,
start_layer=4, end_layer=8, layer_in=latent_F)
gen_im_L = self.downsample(gen_im)
self.percept = lpips.PerceptualLoss(model="net-lin", net="vgg", use_gpu=use_gpu)
self.percept.eval()
self.percept(gen_im_L, ref_im_L).sum()- L_F loss
self.opts.l_F_lambda * (latent_F - F_init).pow(2).mean()를 통해 기존 +()와 최대한 비슷한 latent code 를 찾는다.
따라서 원본 이미지와의 차이를 최소화하면서 기존 +()와 최대한 비슷한 latent code 를 찾는 것이 주 목적이다. 최종 loss는 아래와 같다.
② Alignment
Initial Segmentation
Reference image는 자동으로 분할되고 target image로 복사할 영역이 선택된다. 목표는 reference image 로부터 인 이미지의 위치에서 시각적 특성이 전달되도록 target mask 과 일치하는 합성 영상 를 형성하는 것이다.
- SEGMENT : segmentation network(BiSeNET)
- 은 자동으로 생성되고 수동 편집 가능
Target mask를 자동으로 구성하기 위해 각 픽셀 은 조건을 만족하는 값 로 설정한다. 이때, Segmentation mask 간의 충돌을 해결하기 위해(둘 이상의 에 대해 조건 충족), 값이 우선순위에 따라 정렬되어 합성된다.

Inpainting
이 어떤 에 대해서도 충족되지 않을 때, 일부 픽셀은 segmentation mask에 포함되지 않을 수 있다. 이 경우, 대상 마스크의 일부는 휴리스틱 방법을 사용하여 인페인팅한다.

Alignment
- 목표 : aligned image의 을 찾은 뒤 를 이용해 를 찾는 것
는 target 에 정확히 정렬되지 않는다. 따라서 과 일치하고 latent space에서 와 비슷한 latent space 를 찾아야 한다.
그러나 의 detail은 공간적으로 상관 관계가 있기 때문에 를 직접 최적화하기 어렵다. 대신 먼저 + latent code를 찾고 +로 정렬된 이미지를 찾아낸 다음 를 이용해 를 찾을 수 있다.

Latent code를 찾기 위해 semantic segmentation network 와 generator 를 합성하여 미분 가능한 sementic segmentation generator 구성한다. loss를 최소화하기 위해 이 generator에 GAN inversion(예: II2S)을 사용하면, latent code 을 찾을 수 있고, 이를 통해 은 분할이 대상 분할과 일치하는 이미지가 된다.
GAN Inversion
입력 이미지와 유사한 결과 이미지를 얻을 수 있도록 하는 latent vector를 찾는 과정
그러나 서로 다른 이미지일지라도 동일한 semantic segmentation을 생성할 수 있으므로 GAN inversion은 segmentation mask에 적합하지 않다. 또한 참조 이미지의 원래 latent code와 최대한 유사한 이미지를 찾는 것을 목표로 하기 때문에 참조 이미지의 내용을 보존하기 위해 style losse만 사용하여 결과를 도출한다.
aligned image 와 원본 이미지 사이의 스타일을 보존하기 위해 style loss를 사용한다. LOHO에서 설명된 masked loss는 특정 영역 내에서만 feature activation의 gram matrix를 계산하기 위해 정적 마스크를 사용한다. 반면, 본 연구에서는 각 gradient descent 단계가 새로운 latent code를 생성하고 이는 새로운 생성 이미지 및 분할로 이어지기에 각 단계에서 사용된 마스크는 동적이다. LOHO에서 착안하여 loss를 gram matrix에 기반한다:
- : matrix formed by the activations of layer ℓ of the VGG network
gram matrix
벡터들 간의 내적을 통해 생성되는 행렬로 주로 벡터들 사이의 관계를 이해하는 데 사용
https://towardsdatascience.com/implementing-neural-style-transfer-using-pytorch-fd8d43fb7bfa
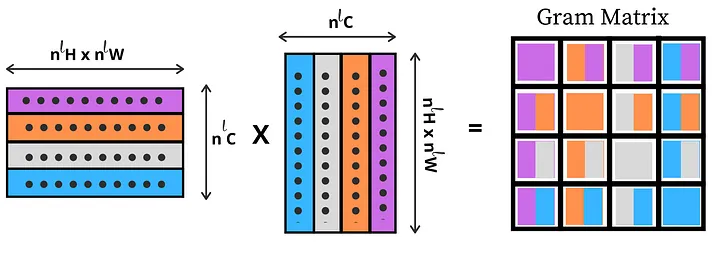
style loss는 latent code 에 의해 생성된 이미지와 목표 이미지 의 gram matrix 간의 차이의 크기이며, 각 이미지의 semantic 영역 𝑘 내에서만 평가된다. 이때 이미지 의 영역 에 대한 영역 마스크는 다음과 같다:
- : indicator function
- : semantic category 에 속하는 이미지의 영역을 나타내는 지표
style loss
- VGG-16의 𝑟𝑒𝑙𝑢1_2, 𝑟𝑒𝑙𝑢2_2, 𝑟𝑒𝑙𝑢3_3, 𝑟𝑒𝑙𝑢4_3 레이어에서 summation
- : 의미 영역 외부의 모든 픽셀을 0으로 설정하여 이미지 마스킹
alignment loss
- : multi-class cross-entropy function
- 만 구하는 것이 목적이기에 정렬 중에 에 해당하는 + 공간 부분만 최적화
- 초기 reconstruction code 근처에 latent code를 유지하기 위해 early-stopping
- : LOHO에서 설정한 값
- mask 와 image 모두 iteration step 마다 update
Structure Transfer
을 사용한 정렬은 그럴듯한 이미지를 생성하지만 세부 정보의 표현이 필요하다.

잘라낸 얼굴 이미지에서 겹치는 영역은 공간적으로 정렬되므로 해당 영역 내에서 재구성된 이미지의 구조를 전송한다. 이때, target mask가 참조 이미지의 영역과 항상 완벽하게 정렬되어 있지는 않다는 점을 유의해야 한다. 에서 로 structure와 appearance을 전송하기 위해 binary mask를 사용하여 detail을 복사할 영역 정의한다:
target mask M
reference image’s mask
- : indicator function
- 레이어 ℓ의 activation 차원과 일치하도록 을 bicubic-resampling을 사용하여 다운샘플링하면
Structure tensor
각 reference 이미지 𝑘에 대해 정렬된 latent representation 를 구할 수 있다.
- : Generator 안 m번째 style-block의 output
- : [0, 1], target 이미지와 reference 이미지의 semantic class가 동일하기 때문에 에서 구조를 복사
- : detailed feature을 재구성하는 능력이 덜한 를 복사
③ Blending
Structure Blending
structure tensor 와 appearance code 를 혼합하여 최종 이미지를 합성할 수 있다. 혼합 이미지를 만들기 위해 가중치 를 사용하여 의 structure tensor 요소를 결합하여 structure tensor 혼합한다. 각 reference image의 coarse structure는 각 structure tensor의 영역 결합으로 간단하게 합성할 수 있지만, appearance code를 혼합하는 것은 더 복잡하다.
- ☉ : element wise multiplication
Appearance Blending
서로 다른 개의 reference code 의 혼합인 단일 style code 를 찾아야 한다. 를 찾기 위해 마스킹된 부분을 LPIPS 거리 함수를 loss로 최적화한다. 는 채널 차원에 걸쳐 정규화된 convnet(VGG)의 layer의 activation을 나타낸다. 해당 텐서의 모양은 이며, 채널이다.
이미지 와 다른 이미지 의 비교
- : 레이어 와 관련된 채널 당 가중치의 학습된 벡터
- VGG의 모든 레이어를 사용하지 않고 세개 레이어(conv1-conv3)로만 설정
mask 를 추가해 이미지 의 영역 에 정렬된 이미지와 비교
- : 영역 에 정렬된 이미지
- : 각 레이어의 차원에 맞게 다운샘플링(bicubic)된 mask
Blending
를 찾기 위해 latent code를 정렬된 reference codes()와 가까운 영역 내에 머무르도록 한다. GAN inversion의 불안정한 특성으로 인해, 제약이 없으면 loss를 과도하게 적합시키거나, 입력들로부터 멀리 떨어진 코드를 찾을 수도 있다.
본 연구에서 제한된 해결책은 가능한 latent code들의 집합을 임베딩 공간의 작은 부분으로 제한한다. 개의 다른 혼합 가중치 집합을 찾는 것으로, 각 는 의 벡터이다.
- 의 각 요소는 reference code 의 해당 요소의 convex combination
- 로 를 최소화 → projected gradient descent을 사용하여 를 찾음
- blended image가 reference image 중 하나의 복사본이 되도록 를 초기화
Mixing Shape, Structure, And Appearance

Reference
