Idea
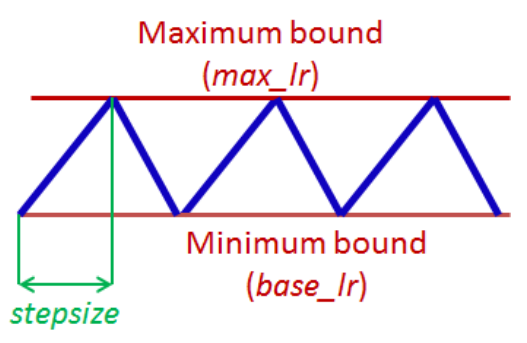
손실함수의 유의미한 감소를 위해서 Learning Rate(LR)를 주기적(Cyclical)으로 바꾸는 것이 지역 최소점(Local Minima) 또는 안장점(Saddle Point)에 빠져 나오는데 도움이 된다는 것이 해당 논문의 핵심 아이디어
해당 아이디어가 유용하다는 것을 실험으로 증명
Contents
1. Parameter estimation in CLR(Cyclical Learning Rates) policy
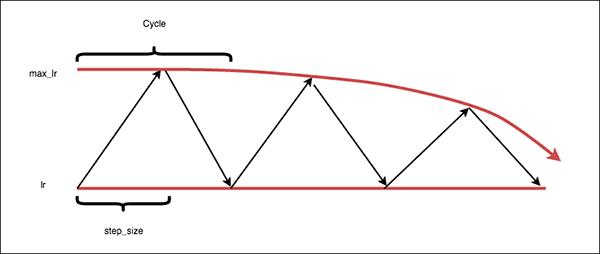
originally) step size= number of iterations = datasets size/batch size = 1 epoch
paper) step size= 2epoch ~ 8epoch
base lr과 max lr 같은 경우 실험적으로 정확도 변화 추이를 보고 결정,
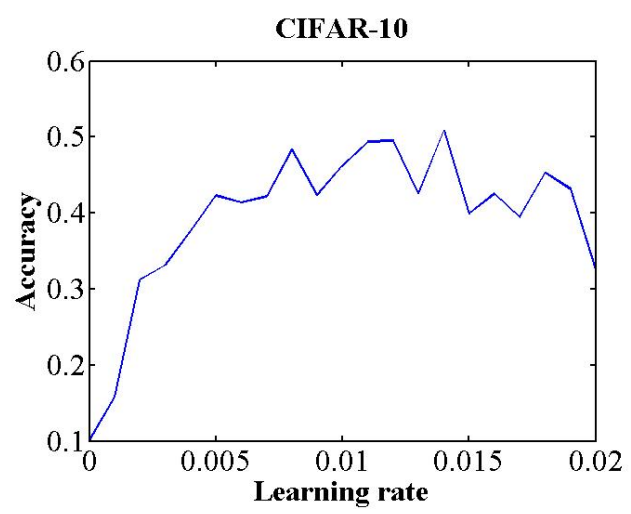
위 이미지 같은 경우 0.001 에서 올라가고 0.006 에서 내려가는 것을 보고
base lr: 0.001
max lr: 0.006
으로 결정할 수 있음
2. CLR Method Type
-
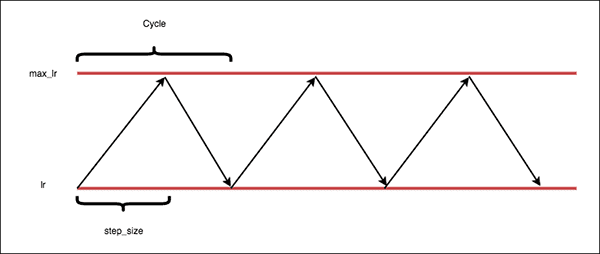
triangular(origin)
-
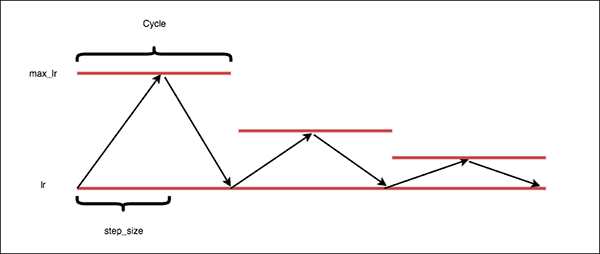
triangular2 = 정해둔 max learning rate를 반절로 줄여가면서 clr 진행
-
exp range = 정해둔 max learning rate를 exp 함수로 decay 해가면서 clr 진행
Comparison(Experiments)
1. 데이터 셋 별(CIFAR-10, ImageNet)로 실험
-
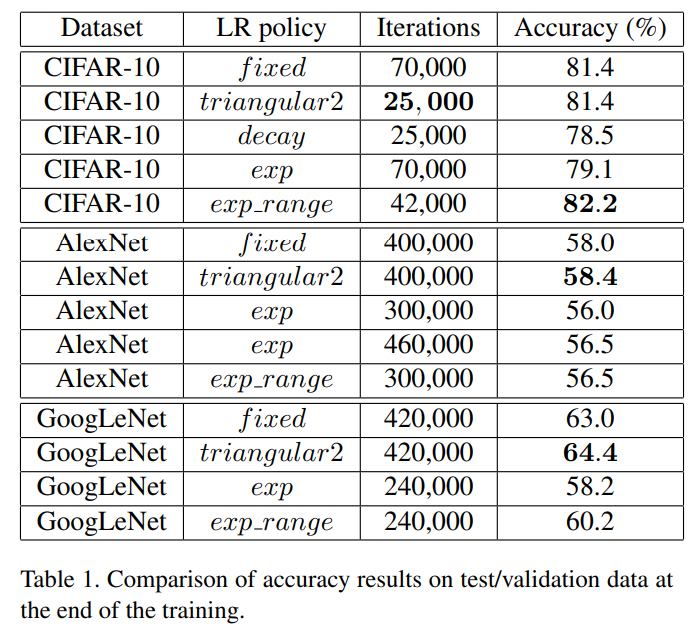
Dataset은 CIFAR-10, Caffe에서 제공하는 네트워크 고정 학습 결과
-
exp_range(CLR)에서 42000 iterations 으로 accruacy 82.2%로 가장 높음(Fixed(baseline)대비 0.8% 높음)
-
Triangular2(CLR)에서 25000 iterations 으로 accuracy 81.4% → 다른 LR 정책보다 빨리 수렴하면서 정확도가 높다는걸 언급
-
-
Dataset은 Imagenet, AlexNet으로 고정 학습 결과
- Triangular2(CLR)에서 400000 iterations 으로 accuracy 58.4%)(Fixed(baseline)대비 0.4% 높음)
-
Dataset은 Imagenet, GoogLeNet으로 고정 학습 결과
- Triangular2(CLR)에서 420000 iterations 으로 accuracy 64.4%(Fixed(baseline)대비 1.4% 높음)
2. Optimizer(adaptive learning rate methods) 종류별로 CLR 정책 학습 실험
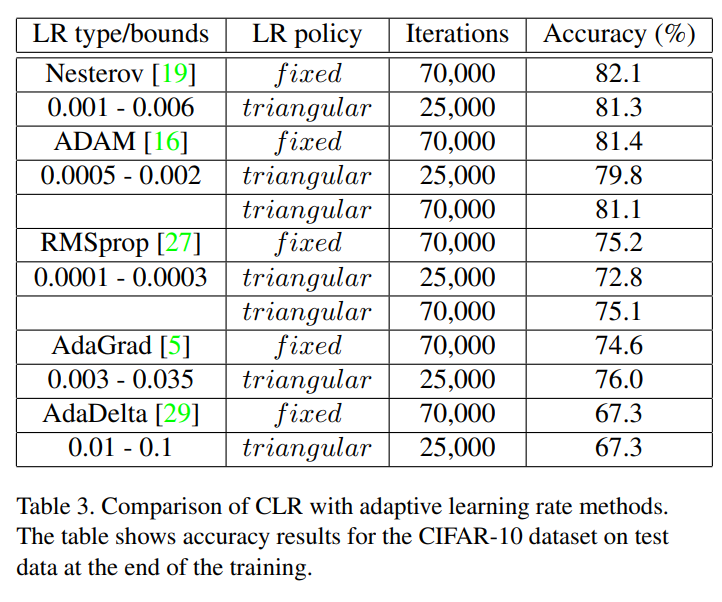
- Dataset은 CIFAR-10 고정, Caffe에서 제공하는 네트워크 고정,
Optimizer(adaptive learning rate methods) 종류별로 CLR을 적용한 학습 결과- AdaGrad 에서 accruacy 76%(Fixed(baseline) 대비 1.4% 높음)
- 이외의 optimizer 결과는 비슷하거나 조금 낮음 → 실험의 공정성 때문에, base lr 설정을 fixed의 lr 설정과 동일하게하기 위해서 원래 CLR의 파라미터 설정 방법을 사용하지 않았다고 언급함
3. ResNet 계열별로 학습 실험
-
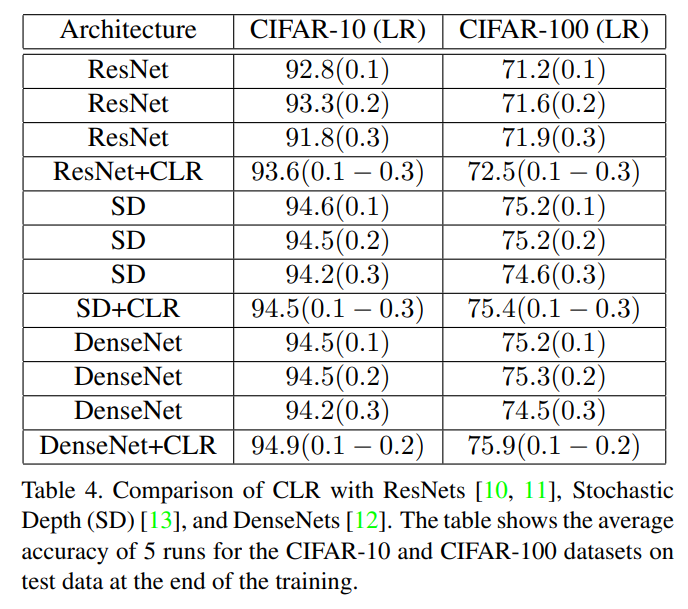
Dataset은 CIFAR-10와 CIFAR-100 고정, ResNet 계열을 CLR 정책으로 학습 결과
-
ResNet 에서 CLR 정책 학습시 Cifar-10 → accuracy 93.6% (Fixed(baseline) 대비 1.8%높음), Cifar-100 → accuracy 72.5% (Fixed(baseline) 대비 1.3%높음)
-
SD 에서 CLR 정책 학습시 Cifar-10 → accuracy 94.5% (Fixed(baseline) 대비 0.01% 낮음), Cifar-100 → accuracy 75.4% (Fixed(baseline) 대비 0.2%높음)
-
DenseNet 에서 CLR 정책 학습시 Cifar-10 → accuracy 94.9% (Fixed(baseline) 대비 0.7% 높음), Cifar-100 → accuracy 75.9% (Fixed(baseline) 대비 0.7%높음)
-
Conclusion
효율적으로 빠르게 높은 정확도로 수렴하는 LR 정책인 것 같음
특히나 다양한 모델에서 널리 활용되고 있는 구조인 ResNet 계열에서 그 우수성을 보임
Kaggle 같은 Competition 에서 해당 정책을 많이 활용하는 것 같음 → 대회에서는 빠르게 결과를 보는 것이 중요하기 때문에, 분류 모델에 대한 Task인 경우 해당 LR 정책을 많이 활용하는 듯하다.
Reference
Smith, Leslie N. "Cyclical learning rates for training neural networks." 2017 IEEE winter conference on applications of computer vision (WACV). IEEE, 2017.
