Idea
이 논문의 목적은 ViT 이전과 이후의 모델들과 비교하면서 기존 CNN에서도 해당 성능을 뛰어넘을 수 있는것을 보여주기 위함.
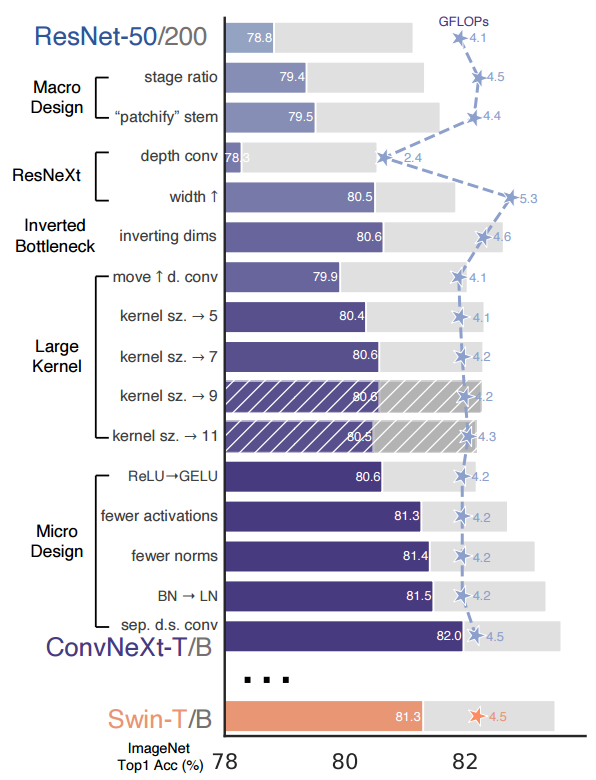
ResNet50/200을 base로 hierarchical Transformer를 CNN으로 변환하여 점차 성능을 높인 ConvNeXt라는 모델을 제안하면서 FLOPs(4.5x10⁹)가 서로 비슷한 Swim-T와 비교함.
Contents
1. Training Techniques
저자들은 Base model(ResNet-50/200)에 다음과 같은 modern training techniques를 적용
- original 90 epochs -> extended to 300 epochs
- AdamW optimizer
- Data Augmentation : Mixup, Cutmix, RandAugment, Random Erasing, regularization schemes including Stochastic Depth, Label Smoothing
위와 같은 기법들을 적용했을때 ResNet-50의 성능인 76.1%에서 78.8% 달성
2. Macro Design
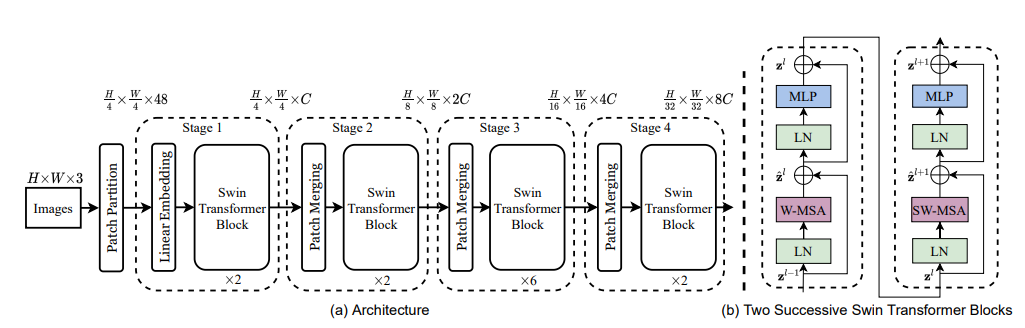
위 그림과 같이 Swin-Transformer는 Input을 Patch단위로 나누고, Hierarchical 구조를 4개의 Block단위로 분리하였다. 이 두가지를 아래와 같이 적용시킴
Changing stage compute ratio.
Swin-T에서는 1:1:3:1 비율로 Block이 실행되며 Large 모델은 1:1:9:1로 되어있다. 기존 ResNet-50에서 사용하던 (3,4,6,3)의 residual block 개수를 (3,3,9,3)으로 변경시켰고 정확도가 78.8% -> 79.4%
block개수가 많아진 만큼 FLOPs도 4.1G에서 4.5G로 증가함
Changing stem to “Patchify”.
기존 모델들의 Stem부분은 ResNet은 7x7 filter, stride 2, max pool를 통해 input image를 4배 downsampling 저자는 4x4 filter size에 stride 4를 주어 convolution을 수행하여 Non-overlapping convolution이 Swin-T의 stem이랑 유사한 일을 할 수 있도록하였음.
patchify stem을 적용한 결과 정확도는 79.4%에서 79.5%로 미세하게 올랐으며 FLOPs는 0.1G 감소하는 이점을 얻음
ResNeXt-ify
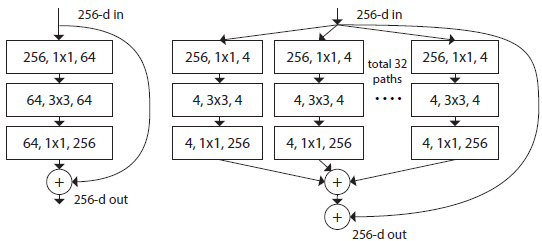
RssNeXt의 아이디어를 통해 FLOPs와 Accuracy 간의 더 좋은 Trade-off를 얻으려고함
ResNeXt의 특징은 input channel을 32개의 patch로 나누어 각자 연산을 한 후 다시 concatenate시키는 grouped convolution을 함.
Swin-T와 채널을 맞추기 위해 width를 64에서 96으로 증가시켜 결과적으로 80.5%(1% up) Accuracy, 5.3G FLOPs(0.9G up)
Inverted Block
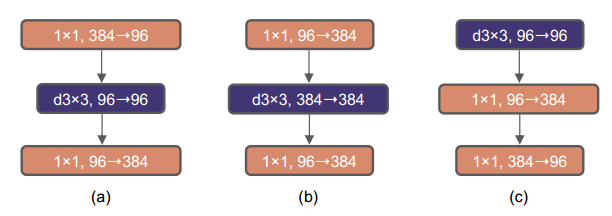
Transformer block에서도 inverted bottleneck이 이미 사용되고 있음.
Transformer의 MLP block에서는 채널을 4배 늘린 후 다시 원래로 되돌리는데 1x1 convolution이 결국에는 fc layer와 같은 일을 함.
ConvNeXt에도 inverted bottleneck을 적용하였는데 downsampling residual block에 의해 많은 FLOPs가 감소되었으며 80.6% Accuracy (0.1% up) 4.6G FLOPs(0.7 down)
Large Kernel Sizes
Swin Transformer에서는 window size를 7x7(49개의 patch)로 가져감.
이에 저자들은 기존 ResNe(X)t 모델의 3x3 kernel 대신 larget kernel-size conv를 사용해서 실험
저자들은 3,5,7,9,11 kernel size 모두 실험을 통해 7x7 kernel size가 saturation 되었다고 하며 FLOPs는 거의 유지된 상태로 정확도는 79.9%(3x3) 에서 80.6%(7x7)으로 향상
3. Micro Design
Replacing ReLU with GELU
NLP에서는 ReLU의 smoother vaiant 버전인 GELU(Gaussian Error Linear Unit)가 BERT, ViT등 해당 연구에서 많이 사용됌. 정확도와 FLOPs는 변하지 않았지만 저자들은 모든 activation function을 GELU로 활용
Fewer activation functions
MSA 부분에는 activation이 없고 MLP block에 단 한개의 activation function만 포함함.
Transformer의 전략을 가져오기 위해 ConvNeXt에서는 두개의 1x1 convolution(위 그림 c) 사이에 하나의 GELU만을 사용, 정확도를 81.3%(0.7% up) 까지 올림
Substituting BN with LN
Transformer에서는 Layer Normalization을 통해 높은 성능을 냄.
LN을 바로 ResNet에 적용시키면 오히려 성능이 떨어지지만 지금까지 언급한 테크닉들을 적용한 ConvNeXt에서는 약간의 성능 향상(81.5%(0.1% up))을 함
Separate downsampling layers.
Swin Transformer에서는 downsampling layer(patch merging)가 따로 존재함.
ConvNeXt에서도 downsampling을 위한 layer를 추가. 이때 2x2 conv, stride 2를 사용함.
단순히 레이어만 추가했을 때 학습이 발산되어 Normalization layer을 추가하여 학습을 안정화 시켰고 결국 82.0% 까지 정확도를 달성 → LN을 사용한 이유
Comparison(Experiments)
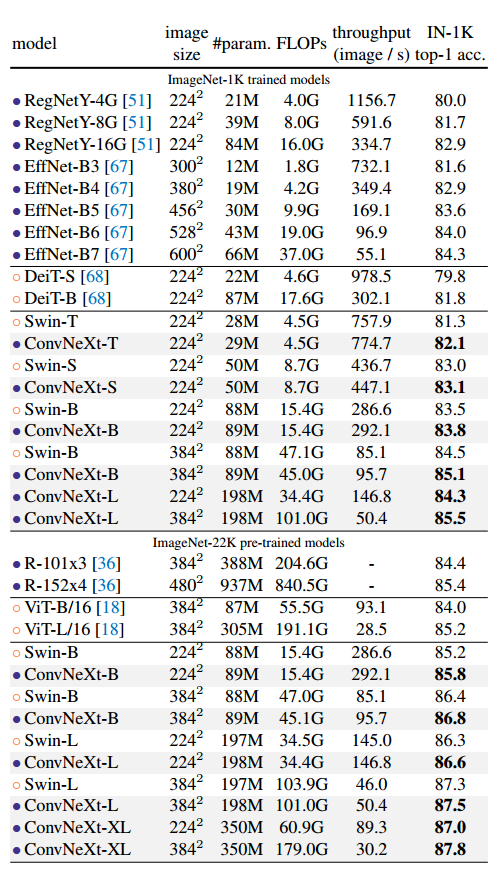
Swin Transformer와 직접적으로 비교를 하면서 같은 조건하에 ConvNeXt의 성능이 더 좋은것을 볼 수 있음
ConvNeXt가 FLOPs 대비 성능만 좋은것이 아니라 실용적으로도 효율성이 있다는 것을 언급함.
Conclusion
- CNN은 아직 강건하고 효율적(efficiency)이다.
- 잘 디자인 된 CNN은 큰 데이터셋에 대한 성능이 뒤지지않고 오히려 넘어선다.
- Transformer의 효율성은 self-attention과 관련된 것이 아니라 Convolution의 inductive bias에서 옴. → 사실상 bias를 가지고 해당 기술을 활용하여 구조에 적용하고 있음
- 제안한 모델만 augmentation을 heavy하게 적용하여 비교, EffNet-v2가 아닌 EffNet-v1을 비교함으로써 실험에 대한 형평성 논란이 있음.
Reference
- Liu, Zhuang, et al. "A ConvNet for the 2020s." arXiv preprint arXiv:2201.03545 (2022).
