Idea
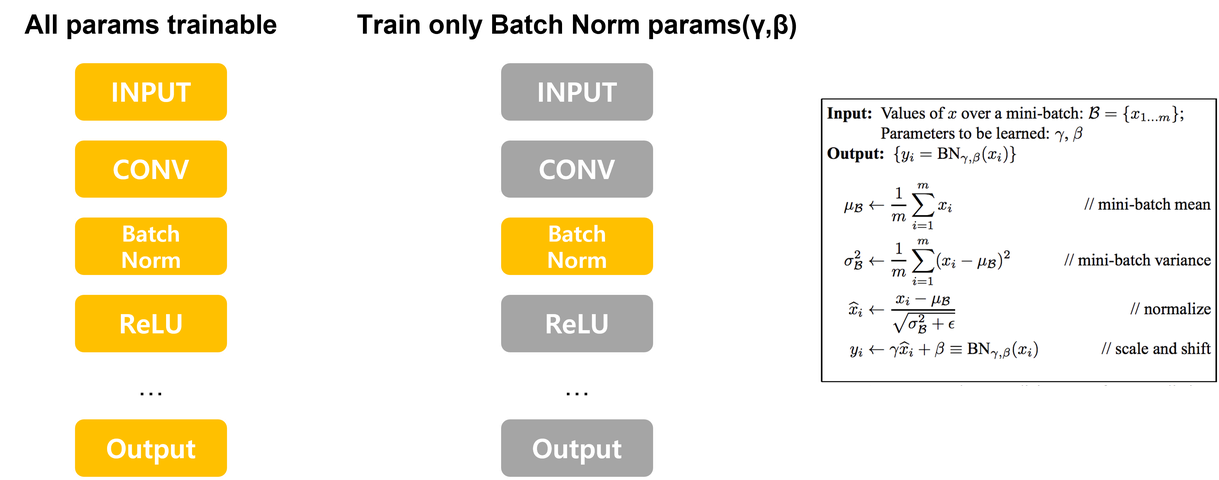
해당 논문의 목적은 실제로 Batch Norm(Batch Normalization)에서 Scale과 Shift에 해당하는 γ(gamma) 와 β(beta) 표현력에 대해서 알지못함. 본 논문은 네트워크에서 Batch Norm의 파라미터를 제외하고 Random으로 Initialization한 Weights는 Freeze 시킨후 학습함으로서 γ,β 의 그 표현력과 한계를 탐색하고자함.
Contents
1. Exploiting the expressive power of affine transformations
Batch Norm에서 적용되는 아핀 변환(affine transformation)통해서 해당 파라미터를 다양하게 활용하는 연구는 아래와 같이 많은 논문과 연구가 있었음
Multi-tasking learning
Per-Task Batch norm(K for the Price of 1: Parameter-efficient Multi-task and Transfer Learning )
하나의 학습된 네트워크를 가지고 다른 task에 적용할 때는 Batch Norm parameters만을 학습
(Residual Adaptor Modules을 설계해 하나의 task에 대해 학습된 모델을 다른 visual domain에 적용)
Style transfer and Style generation
- Instance normalization을 활용해, content feaure를 다양한 style feature에 인코딩할 수 있도록 적용
- Style GAN(A Style-Based Generator Architecture for Generative Adversarial Networks )
- Aaptive instance normlization(AdaIN,Arbitrary Style Transfer in Real-time with Adaptive Instance Normalization )
- Conditional instnace normalization(A Learned Representation For Artistic Style )
2. Training only BatchNorm
Network의 다양한 부분을 Freeze하면서 Batch Norm Params(γ와β)만을 학습 시켜 CIFAR-10 Networks(DenseNet and an unspecified Wide ResNet)에서 61% and 31% 정확도 (Intriguing Properties of Randomly Weighted Networks: Generalizing... )
3. Research background
어떻게 BatchNorm Params(γ와β)만을 학습했을때 좋은 성능이 나오는지 깊은 연구 필요
소수의 parameter를 학습한 결과와 BatchNorm parameter training 결과를 비교해 BatchNorm parameter의 표현력 확인
다양한 범위의 network에서 BatchNorm parameter training가 가능한지 확인
4. Comparison
실험 설정
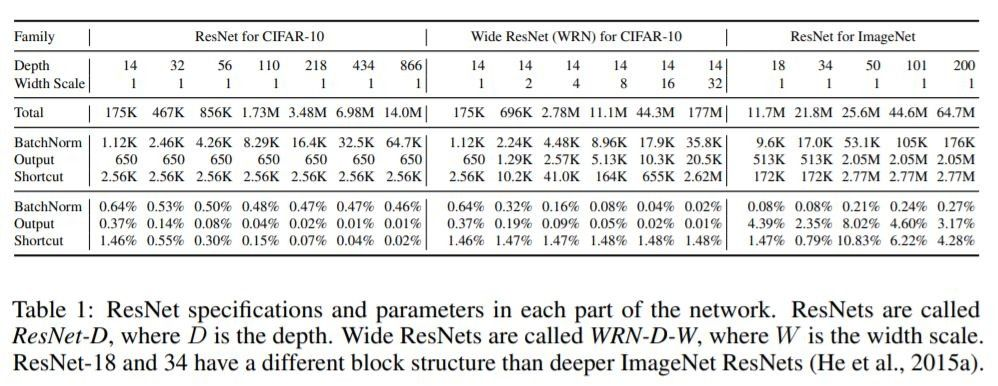
- ResNet for CIFAR-10 과 ResNet for ImageNet은 기본 구조로 활용 → Random initialization
- Depth와 Width 조절해가며 실험 → ResNet를 선택한 이유
- Depth 조절 → Kaiming He et al, CVPR 2015 논문을 따라서 layer을 더 쌓음
- Width 조절 → layer당 채널을 늘림
- Activation 전에 BatchNorm을 배치(Kaiming He et al, ECCV 2016)
실험에 대한 Training only batchnorm의 최고 정확도
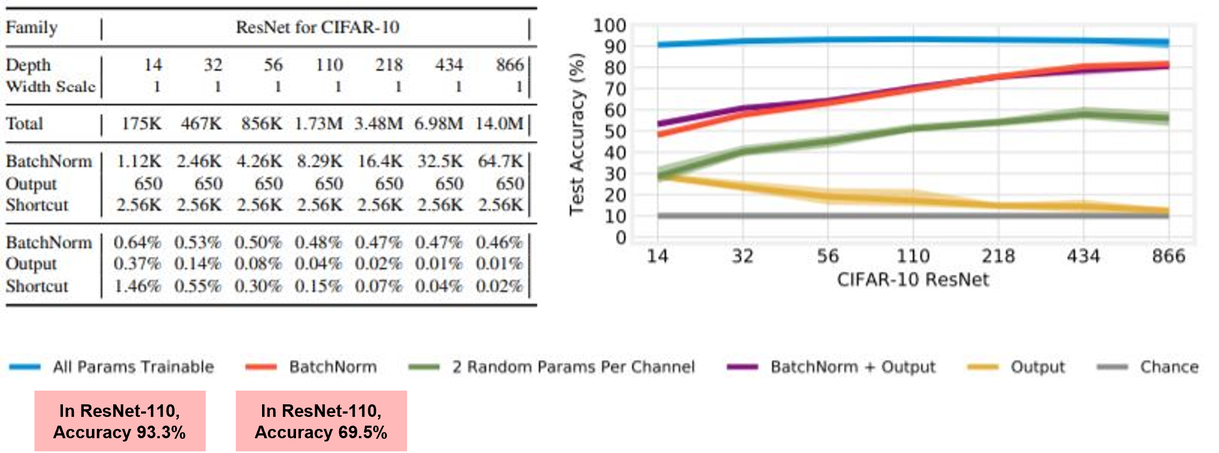
- Random Feature를 recsaling, shifting 하는 parameter를 학습하는 것만으로도 CIFAR-10 에서 높은 Accuracy 달성 → Accruacy 69.5 ~ 82%
네트워크 깊이와 너비에 따른 실험
Dataset → CIFAR-10
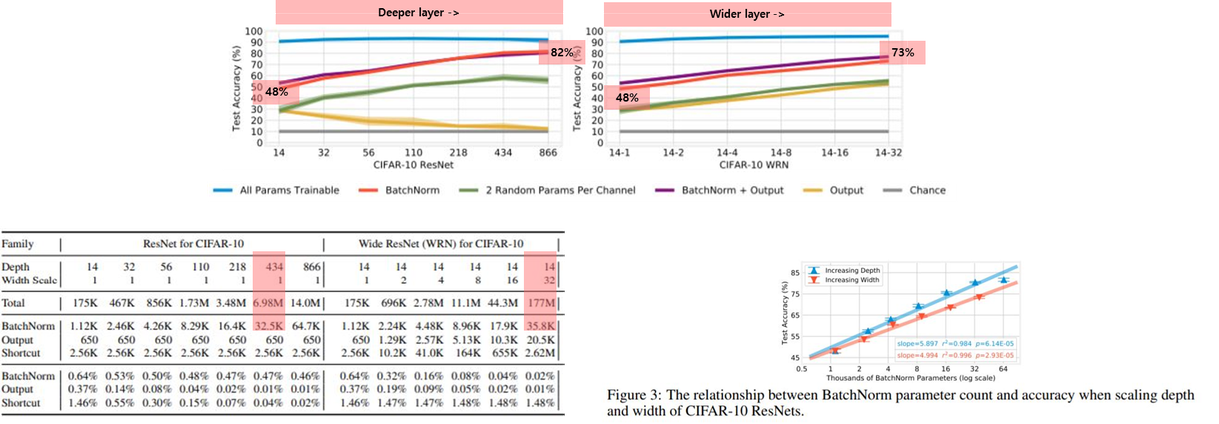
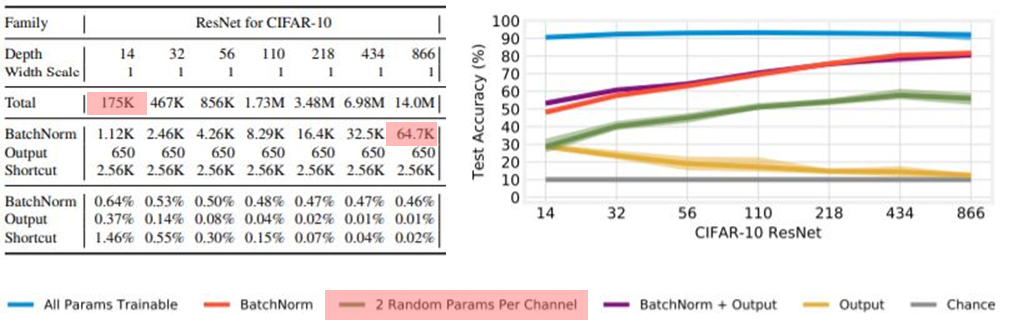
- 네트워크의 width와 depth를 늘림에 따라 정확도가 높아짐
- 네트워크를 깊게 쌓을때가 넓게 만드는것보다 batch parameter training의 효율이 높아지는는 것을 볼 수 있음(Figure 3)
Dataset → ImageNet
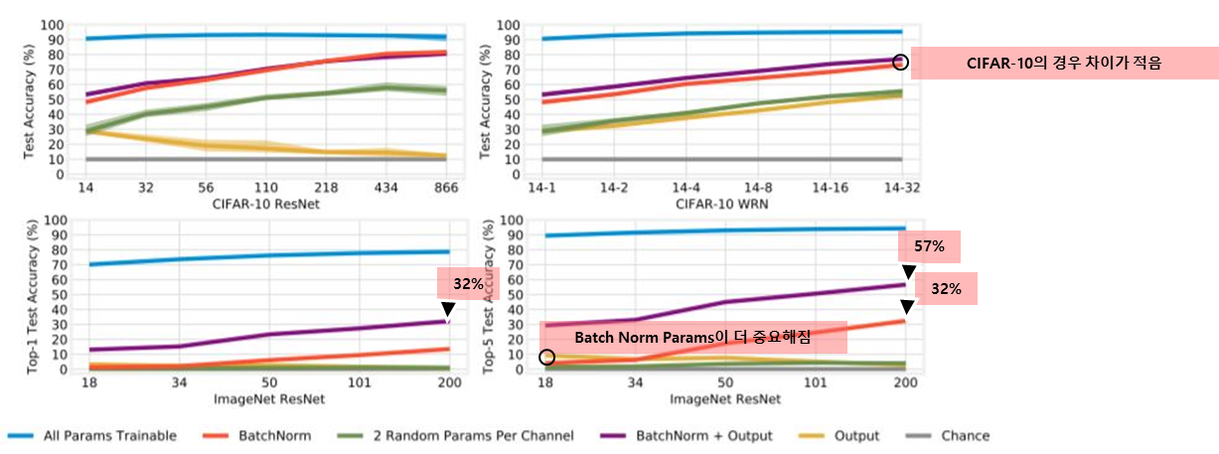
- 1000개의 classes가 있는 ImageNet 의 경우, Output layer를 같이 학습시켜 1000개의 class간의 fined-grained distinctions을 학습하는것이 필요
다른 임의의 2개의 parameters를 학습한 결과를 봤을때 → 해당 파리미터(γ,β)가 특별한 점
- Batch normalization parameters(γ와β)가 아닌 다른 임의의 2개의 parameters를 학습한 결과 성능이 더 낮아지는 것을 볼 수 있음
- Batch normalization parameters가 다른 종류의 parameters들 보다 정확도에 큰 영향을 미치는것이 확인됌
- Scaling parameters를 통해 전체 Random features를 조정하는 것이 일부 parameter를 수정하는것보다 중요하다
Examining the values of γ and β
γ 에 대한 실험(γ 의 역할)
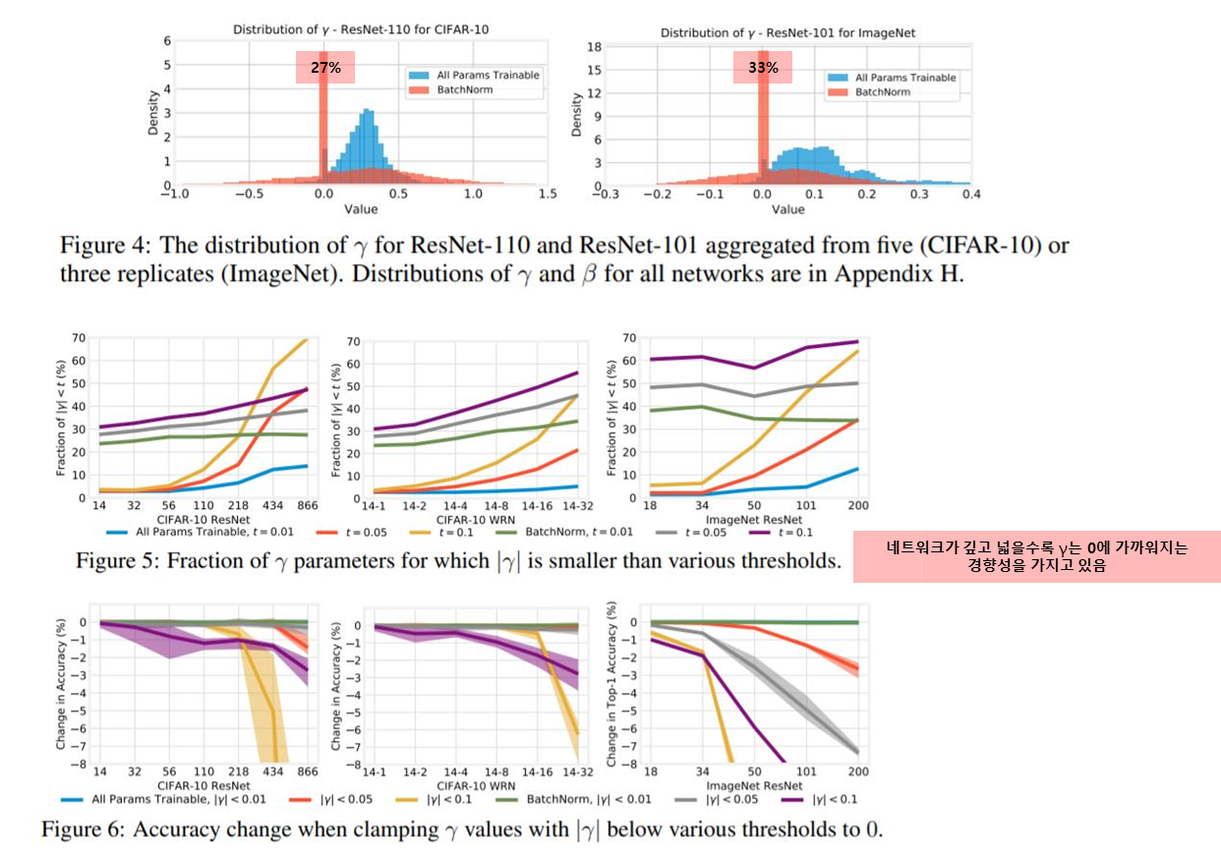
- figure 4를 통해서 γ에 대한 histogram을 산출
- γ 를 0에 가깝게 설정함으로써 네트워크의 1/4~1/3를 비활성화하는 방법을 배우는 것으로 보임
- 저자들은 γ 가 0에 가까워지는 것이 exploding activations를 막기 위함 → γ 와 β가 per-feature sparsity를 부과함으로서 모델의 높은 정확도에 기여함
- figure 6을 통해서 γ를 0으로 만들어서 정확도를 측정함 → 성능 매우 저하
- 0에 가깝긴한데 0은 아니다
γ 와 β 의 에 대한 실험(γ,β 의 역할)
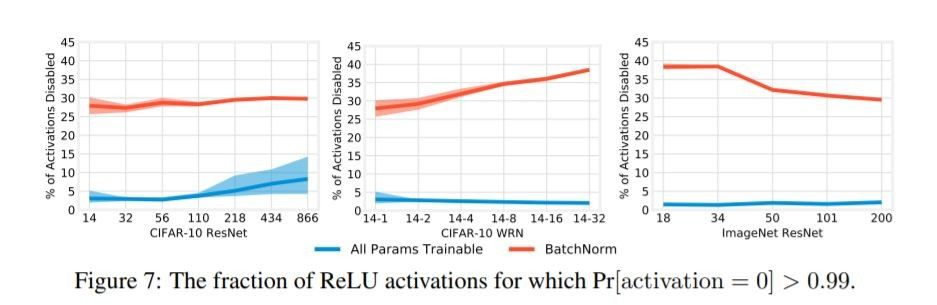
-
β 는 bias 역할(단순히 더하기 때문에..)만 가지고 어떤역할을 하는지 알기 어려움 → activation 지난후에 어떻게 되는지를 측정(비활성화 유무)
- Batch Norm 만 학습 → 30~40% 비활성화 되는것을 관측
- All parameters 학습 → 10% 내외 비활성화 관측
-
Batch normalization parameter가 γ가 activation을 조정하는 역할을 한다.
Conclusion
- Affine parameters가 learnd features들과 관계없이 큰 표현력을 가진다.
- Random feature를 recaling,shifting 하는 parameters를 학습하는 것 만으로도 높은 정확도를 가짐
- γ 와 β 로 인한 feature scaling 과 bias만으로 높은 표현력을 가짐
- γ 와 β 가 per-feature sparsity를 부과함으로서 모델의 높은 정확도를 기여함
- Batch normalization parameter가 γ가 activation을 조정하는 역할
- Random initialized feature로 구성된 network를 훈련 시키는 방법을 모색하는 것이 더 효율적일 것으로 보임
- Ouput layer만 학습하는것보다 Batch normalization parameter만 학습하는것이 더 효과적임
- 학습 비용을 줄일 수 있는 건 아니지만, inference를 위해 random seed와 Batch normalization parameter 저장하여 이후에 Random initialization을 통해 성능을 높일 수 있는 가능성
- 다른 네트워크에 대한 연구 필요
- Training only batchnorm 조건일때 hyperparameter tuning 연구 필요
- 네트워크에서 Batchnorm이 없는 경우에 대한 대처 방안 필요
Reference
- Frankle, Jonathan, David J. Schwab, and Ari S. Morcos. "Training batchnorm and only batchnorm: On the expressive power of random features in cnns." arXiv preprint arXiv:2003.00152 (2020).
