1) 샤딩과 파티셔닝
- 공통점 : 큰 데이터를 여러 서브셋으로 나누어 저장하는 기술
- 샤딩 :
- 데이터를 물리적으로 나누어 데이터 베이스를 여러개 사용하여 저장 됨.
- 이때 수평분할 방식으로 분산저장
- 이렇게 하는 경우 물리적으로 데이터가 나누어 지기때문에 JOIN 등 다양한 부분에서 제약이 발생 - 파티셔닝 :
- 큰 테이블이나 인덱스를 관리하기 쉬운 크기로 분할
- 한 데이터베이스안에서 이루어짐
2) Storage Engine - Sharding
- 샤딩과 파티셔닝 이야기를 하기위해서 중요한 부분
- DB에는 여러가지 엔진이 존재
- MySQL의 경우 다음과 같은 엔진 종류가 있음
> - innoDB > - MyISAM > - Memory > - Archive > - CSV > - Federated - 설계단계에서 이를 고려하여 상황에 맞는 DB 엔진을 선택해야함.
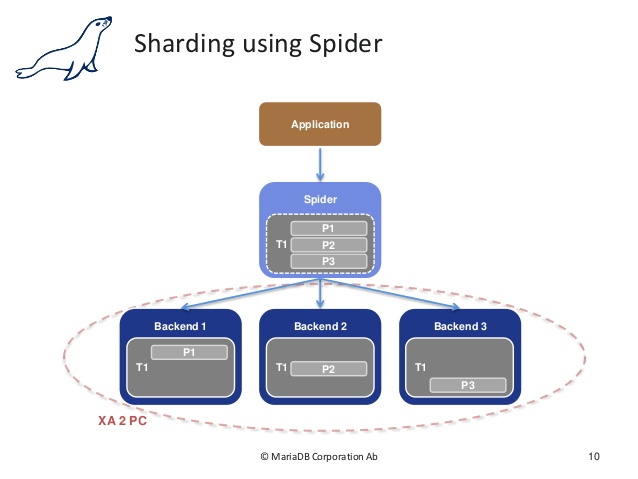
- MariaDB
Spider 엔진은 샤딩기능이 내장된 스토리지 엔진 - 샤당을 하게되면 Read, Write와 같은 쿼리를 여러 인스턴스로 분산하여 처리할 수 있음.
- 다음과 같이 구성된다.
2) DB 파티셔닝
- 테이블의 사이즈가 커서 인덱스의 크기가 메모리 크기보다 큰 경우 파티셔닝 이용
- 파티셔닝을 이용해 분할할 경우 인덱스도 각각 생성되어 작은 인덱스 크기로 메모리에서 빠른 쿼리작업 가능
- 단 테이블간 Join 연산이 존재하는 경우 비용이 증가하며, 테이블과 인덱스를 별도로 파티셔닝을 할 수 없음
- 파티셔닝은 보통 특정 컬럼을 기준, 날짜나, 숫자, 해시를 기준으로 분할함.
- List Partitioning (범위 분할)
분할 키 값이 범위 내에 있는지 여부로 구분한다.
예를 들어, 우편 번호를 분할 키로 수평 분할하는 경우이다.
- Range Partitioning (목록 분할)
값 목록에 파티션을 할당 분할 키 값을 그 목록에 비추어 파티션을 선택한다.
- Hash Partitioning (해시 분할)
해시 함수의 값에 따라 파티션에 포함할지 여부를 결정한다.
예를 들어, 4개의 파티션으로 분할하는 경우 해시 함수는 0-3의 정수를 돌려준다.

-
항상 파티셔닝을 진행할 수 있는게 아님 -> unique 컬럼이 index가 존재해야 파티셔닝이 가능
-
파티셔닝이 항상 좋은 결과를 보장하는 것은 아님
-
SQL을 효율적으로 짜는 것이 첫번째이고 그 다음에 파티셔닝을 고려해보아야함.
-
파티션 구성방법
ALTER TABLE `His_Ai` PARTITION BY RANGE( TO_DAYS(HIS_TIME) ) (
PARTITION p20210401 VALUES LESS THAN (TO_DAYS('2021-04-02')),
PARTITION p20210402 VALUES LESS THAN (TO_DAYS('2021-04-03')),
PARTITION p20210403 VALUES LESS THAN (TO_DAYS('2021-04-04')),
PARTITION p20210404 VALUES LESS THAN (TO_DAYS('2021-04-05')),
PARTITION p20210426 VALUES LESS THAN (TO_DAYS('2021-04-27')),
PARTITION p20210426 VALUES LESS THAN (TO_DAYS('2021-04-28')),
PARTITION p20210426 VALUES LESS THAN (TO_DAYS('2021-04-29')),
PARTITION p20210426 VALUES LESS THAN (TO_DAYS('2021-04-30')),
PARTITION future VALUES LESS THAN MAXVALUE
);- 파티션 조회
# 파티션 항목 조회
SELECT * FROM His_Ai PARTITION (p20210401);
# 현재 데이터베이스 파티션의 정보 확인
SELECT TABLE_SCHEMA, TABLE_NAME, PARTITION_NAME, PARTITION_ORDINAL_POSITION, TABLE_ROWS
FROM INFORMATION_SCHEMA.PARTITIONS
WHERE TABLE_NAME = `His_Ai`;- 파티션 삭제
ALTER TABLE His_Ai DROP PARTITION p20210401;- 파티션 추가
위와 같이 파티션을 구성한경우
(04-30) 이후에 적재되는 데이터는 자동으로 추가되지 않고 (05-01, 05-02)와 같은
추가된 데이터는 자동으로 (04-30)에 쌓이게됨.
이렇게 된 경우 파티션을 분할하는 의미가 없어져 마지막 날짜를 기준으로 파티션을 분할하여 재구성
해주어야 함- 날짜를 기준으로 추가를 하는 경우 스케쥴러에 넣어서 서버를 운영하는 방식
ALTER TABLE `His_Ai` REORGANIZE PARTITION p20210430 INTO (
PARTITION p20210430 VALUES LESS THAN ('2021-05-01') ENGINE = InnoDB,
PARTITION p20210501 VALUES LESS THAN MAXVALUE ENGINE = InnoDB
);3) ORDMS
- 대용량 데이터를 처리하기 위한 새로운 방법
- 객체 관계형 데이터 베이스
- PostreSQL이 최근 각광받고 있음.
![]()
- Array DataType을 지원
CREATE TABLE contacts (
id serial PRIMARY KEY,
name VARCHAR (100),
phones TEXT[]
);
INSERT INTO contacts (name, phones)
VALUES('홍길동', ARRAY [ '031-132-7890','02-678-9876' ]);
INSERT INTO contacts (name, phones)
VALUES
('일지매', ARRAY [ '02-789-5432' ]),
('김갑환', '{"010-4567-8765", "063-123-1234"}'),
('김형준', '{"063-432-8765", "010-4567-8765"}');- 데이터 조회
SELECT name, phones FROM contacts;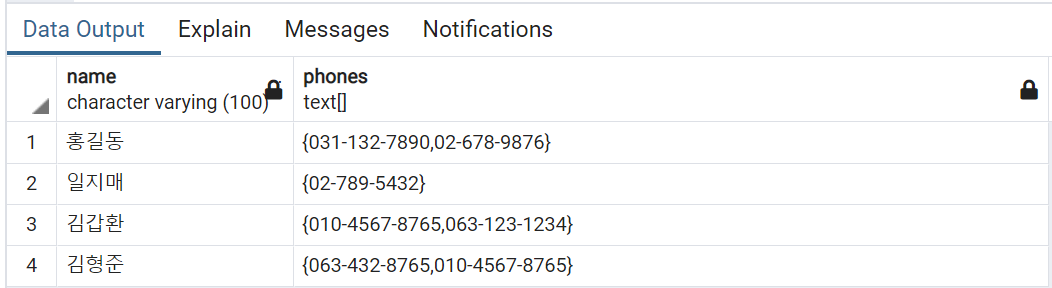
# 특정 인덱스 조회 가능
SELECT name, phones[2] FROM contacts;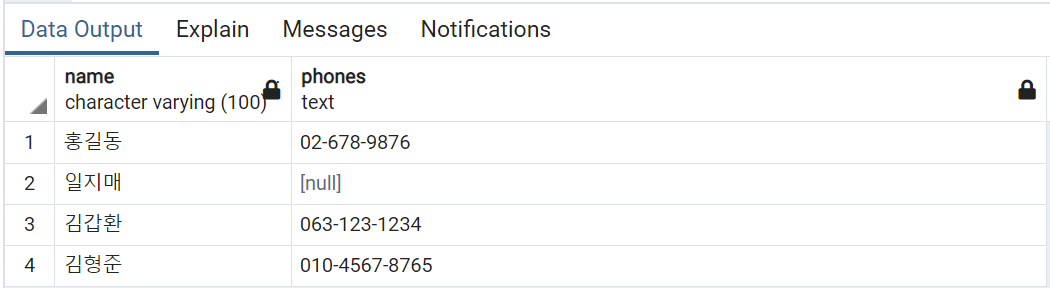
- 부분인덱스를 지원
- 인덱스를 만드는 구문에서 WHERE 조건절을 사용해서 부분 인덱스 생성
- 부분 인덱스란 테이블 전체 자료를 대상으로 하지 않고, 특정 부분 자료를 대상으로 인덱스를 만드는 것
CREATE [ UNIQUE ] INDEX [ CONCURRENTLY ] [ [ IF NOT EXISTS ] 이름 ] ON [ ONLY ] 테이블이름 [ USING 색인방법 ]
( { 칼럼이름 | ( 표현식 ) } [ COLLATE 문자정렬규칙 ] [ 연산자클래스 ] [ ASC | DESC ] [ NULLS { FIRST | LAST } ] [, ...] )
[ INCLUDE ( 칼럼이름 [, ...] ) ]
[ WITH ( 저장_매개변수 [= 값] [, ... ] ) ]
[ TABLESPACE 테이블스페이스이름 ]
[ WHERE 조건절 ]
참고 사이트 출처

내맘대로 주제잡고 재미로 글쓰는 개발일지 블로그 👨💻