참고 자료 출처: 딥러닝을 이용한 자연어 처리 입문
목차
- 인코더(Encoder)
- 인코더의 셀프 어텐션
- 셀프 어텐션 의미와 이점
- Q, K, V 벡터 얻는 방법
인코더(Encoder)
인코더의 구조에 대해 알아보겠습니다!
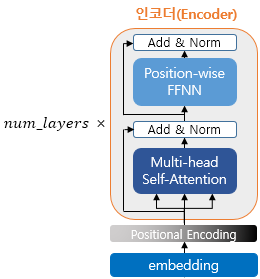
트랜스포머는 하이퍼파라미터인 num_layers 개수의 인코더 층을 쌓습니다. 논문에서는 6개의 층을 사용했습니다. 인코더가 하나의 층이라 생각한다면, 하나의 인코더 층은 크게 총 2개의 서브층(sublayer)로 나뉘어집니다.
- self attention
- feed forward layer
위의 그림에서는 Multi-head self-Attention과 Position-wise FFNN로 적혀 있지만, 멀티 헤드 셀프 어텐션이 셀프 어텐션을 병렬적으로 사용하였다는 의미이고, 포지션 와이즈 피드 포워드 신경망은 우리가 알고 있는 일반적 피드 포워드 신경망입니다.
인코더의 셀프 어텐션
트랜스포머에서는 셀프 어텐션이란 어텐션 기법이 등장합니다. 앞에서 배웠던 어텐션 함수 Attention(Q, K, V) = Attention Value가 셀프 어텐션과 무엇이 다른지 보겠습니다.
셀프 어텐션 의미와 이점
어텐션 함수는 주어진 '쿼리(Query)'에 대해서 모든 '키(Key)'와의 유사도를 각각 구합니다. 구해낸 이 유사도를 가중치로 하여 키와 맵핑되어있는 각각의 '값(Value)'에 반영해줍니다. 그리고 유사도가 반영된 '값(Value)'을 모두 가중합하여 리턴합니다.
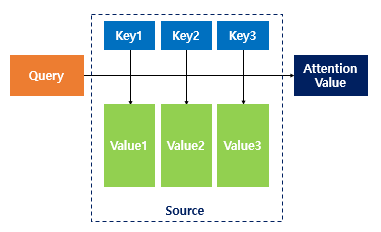
이건 앞에서 배웠던 어텐션의 개념과 동일합니다. 셀프 어텐션(self-attention)이라는 것은 어텐션을 자기 자신에게 수행한다는 의미입니다.
앞의 seq2seq에서 어텐션을 사용한 경우의 Q, K, V의 정의를 보면
seq2seq에서 어텐션에서 Q, K, V의 정의
- Q = Query : t 시점의 디코더 셀에서의 은닉 상태
- K = Keys : 모든 시점의 인코더 셀의 은닉 상태들
- V = Values : 모든 시점의 인코더 셀의 은닉 상태들
그런데 t라는 건 계속 변화하고, 변화하며 쿼리를 수행하므로 결국 전체 시점에 대해 일반화가 가능합니다.
전체 시점의 일반화한 Q, K, V의 정의
- Q = Querys : 모든 시점의 디코더 셀에서의 은닉 상태들
- K = Keys : 모든 시점의 인코더 셀의 은닉 상태들
- V = Values : 모든 시점의 인코더 셀의 은닉 상태들
이처럼 기존에는 디코더 셀의 은닉 상태가 Q이고 인코더 셀의 은닉 상태가 K라는 점에서 Q와 K가 서로 다른 값을 가지고 있었습니다. 셀프 어텐션은 Q, K, V가 전부 동일합니다.
트랜스포머 셀프 어텐션의 Q, K, V의 정의
그래서 트랜스포머의 셀프 어텐션의 Q, K, V의 의미는
- Q : 입력 문장의 모든 단어 벡터들
- K : 입력 문장의 모든 단어 벡터들
- V : 입력 문장의 모든 단어 벡터들
이 됩니다. 셀프 어텐션을 통해 얻을 수 있는 결과를 눈으로 보며 이해해봅시다.

위의 문장은 '그 동물은 길을 건너지 않았다. 왜냐하면 너무 피곤했기 때문이다.' 라고 번역할 수 있습니다. 그런데 여기서 'it'이 '길(street)'인지 '동물(animal)'인지 기계는 어떻게 알아 낼까요?
셀프 어텐션은 입력 문장 내의 단어들끼리 유사도를 구하면서 'it'이 동물과 연관되어 있을 확률이 높다는 것을 찾아냅니다!
Q, K, V 벡터 얻는 방법
앞에서 트랜스포머의 하이퍼파라미터에 대해 설명을 했습니다. 참고
d_model, num_layers, num_heads, d_ff가 있었습니다.
셀프 어텐션은 인코더의 초기 입력 d_model의 차원을 가지는 단어 벡터들을 사용하여 수행하지 않습니다. 각 단어 벡터들로부터 Q, K, V 벡터를 얻는 작업을 거칩니다.
이때 Q, K, V 벡터들은 초기 입력인 d_model의 차원을 가지는 단어 벡터보다 더 작은 차원을 가집니다. 논문에서는 d_model=512 차원을 가졌던 각 단어 벡터들을 64차원을 가진 Q, K, V 벡터로 변환했습니다.
여기서 64차원은 num_heads로 인해 결정됩니다. 트랜스포머는 d_model을 num_heads로 나눈 값으로 차원을 결정합니다. 64차원을 가졌으니 num_heads는 8이었겠네요.
예시로 보겠습니다.
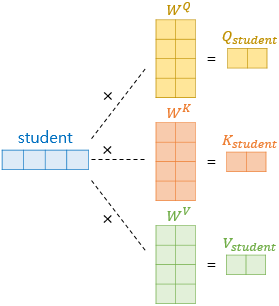
기존의 벡터로부터 더 작은 벡터는 가중치 행렬을 곱하며 완성됩니다. 각 가중치 행렬은 d_model*(d_model/num_heads)의 크기를 가집니다.
가중치 행렬의 크기: d_model*(d_model/num_heads)
이 가중치 행렬은 훈련 과정에서 학습됩니다.
d_model은 512, num_heads가 8이라면 각 벡터에 3개의 서로 다른 가중치 행렬을 곱하고 64의 크기를 갖는 Q, K, V 벡터를 얻어 냅니다. 모든 단어 벡터에 위와 같은 과정을 거치면 'I', 'am', 'a', 'student'는 각각의 다른 Q, K, V 벡터를 얻습니다.
