참고 자료 출처: 딥러닝을 이용한 자연어 처리 입문
스케일드 닷-프로덕트 어텐션(Scaled dot-product Attention)
Q, K, V 벡터를 얻었다면 지금부터는 기존에 배운 어텐션 메커니즘과 동일합니다. 각 Q 벡터는 모든 K 벡터에 대해서 어텐션 스코어를 구하고, 어텐션 분포를 구한 뒤에 이를 사용하여 모든 V 벡터를 가중합하여 어텐션 값 또는 컨텍스트 벡터를 구하게 됩니다. 그리고 이를 모든 Q 벡터에 대해서 반복합니다.
위의 정의와 아래 내용을 정리하며 행렬 연산으로 일괄 처리하는 방법을 배워보겠습니다.
- Q, K, V는 단어 벡터를 행으로 하는 문장 행렬이다.
- 벡터의 내적(dot product)는 벡터의 유사도를 의미한다.
- 특정 값을 분모로 사용하는 것은 값의 크기를 조절하는 스케일링(Scakling)을 위함이다.
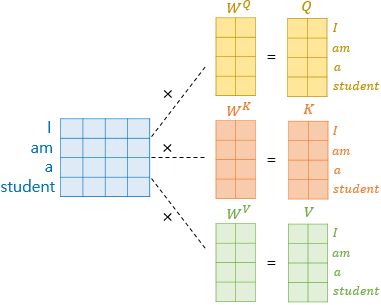
우선, 각 단어 벡터마다 일일히 가중치 행렬을 곱하는 것이 아니라 문장 행렬에 가중치 행렬을 곱하여 Q, K, V 행렬을 구합니다.
이제 행렬 연산을 통해 어텐션 스코어는 어떻게 구할 수 있을까요? 여기서 Q 행렬에 전치한 K 행렬과 곱해봅시다. 이렇게 되면 각각의 단어의 Q, K 벡터의 내적이 각 행렬의 원소가 되는 행렬이 결과로 나오게 됩니다.
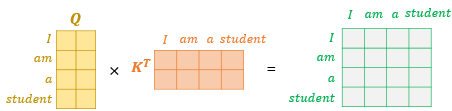
위 초록색 행렬이 의미하는 값은 무엇일까요? 예를 들어 'am' 행과 'student' 열의 값은 Q 행렬에 있던 'am' 벡터와 K 행렬에 있던 'student 벡터'의 내적값을 의미합니다. 결국 각 단어 벡터의 유사도가 모두 기록된 유사도 행렬입니다.
이 유사도 값을 스케일링 해주기 위해 행렬 전체를 특정 값으로 나눠줍니다. 이건 유사도를 0~1 사이의 값으로 Normalize 해주기 위함으로 softmax 함수를 사용합니다.
여기까지가 Q와 K의 유사도를 구하는 과정이었습니다. 여기에 문장 행렬 V와 곱하면 어텐션 값(Attention Value)를 얻습니다.
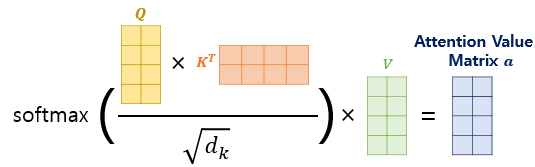
이를 계산식으로 나타내면 아래와 같습니다.
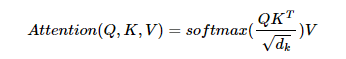
이 수식은 내적(dot product)을 통해 단어 벡터 간 유사도를 구한 후에, 특정 값을 분모로 나눠주는 방식으로 Q와 K의 유사도를 구하였다고 하여 스케일드 닷 프로덕트 어텐션(Scaled Dot Product Attention) 이라고 합니다.
스케일드 닷-프로덕트 어텐션 구현하기
def sacled_dot_product_attention(query, key, value, mask):
# query 크기: (batch_size, num_heads, query의 문장 길이, d_model/num_heads)
# key 크기: (batch_size, num_heads, key의 문장 길이, d_model/num_heads)
# value 크기: (batch_size, num_heads, value의 문장 길이, d_model/num_heads)
# padding_mask: (batch_size, 1, 1, key의 문장 길이)
# Q와 K의 곱. 어텐션 스코어 행렬
matmul_qk = tf.matmul(query, key, transpose_b=True)
# 스케일링
# dk의 루트값으로 나눠준다.
depth = tf.cast(tf.shape(key)[-1], tf.float32)
logits = matmul_qk / tf.math.sqrt(depth)
# 마스킹, 어텐션 스코어 행렬의 마스킹 할 위치에 매우 작은 음수값을 넣는다.
# 매우 작은 값이므로 소프트맥스 함수를 지나면 행렬의 해당 위치의 값은 0이 된다.
if mask is not None:
logits += (mask * -1e9)
# 소프트맥스 함수는 마지막 차원인 key의 문장 길이 방향으로 수행도니다.
# attention weight: (batch_size, num_heads, query의 문장 길이, key의 문장 길이)
attention_weights = tf.nn.softmax(logits, axis=-1)
# output : (batch_size, num_heads, query의 문장 길이, d_model/num_heads)
output = tf.matmul(attention_weights, value)
return output, attention_weights코드는 위의 내용을 이해했다면 어렵지 않습니다.
Q 행렬과 K 행렬을 전치한 행렬을 곱하고, 소프트맥스 함수를 사용하여 어텐션 분포 행렬을 얻은 뒤에 V 행렬과 곱합니다. 코드에서 mask가 사용되는 if문은 아직 배우지 않은 내용으로 지금은 무시하고 넘어갑니다.
scaled_dot_product_attention 함수가 정상 작동하는지 테스트를 해보겠습니다. 우선 temp_q, temp_k, temp_v라는 임의의 Query, Key, Value 행렬을 만들고, 이를 scaled_dot_product_attention 함수에 입력으로 넣어 함수가 리턴하게 됩니다.
