참고 자료 출처: 딥러닝을 이용한 자연어 처리 입문
인코더, 디코더 (Encoder, Decoder)
인코더와 디코더 모델은 번역기를 만드는데 사용하는 대표적인 모델입니다. 번역기는 두 아키텍처로 구성되 있는데, 인코더로 입력 문장이 들어가고, 디코더는 이에 상응하는 출력 문장을 생성합니다.
그리고 이것을 훈련한다는 것은 결국 입력 문장과 출력 문장 두 가지 병렬 구조로 구성된 데이터셋을 훈련한다는 의미입니다.
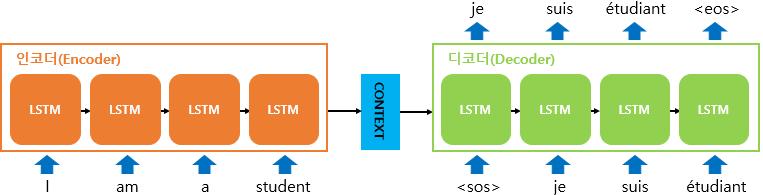
훈련 데이터셋의 구성
- 입력 문장: I am a student
- 출력 문장: je suis étudiant
이렇게 병렬적으로 구성된 데이터셋을 인코더, 디코더로 학습하는 경우는 번역기 이외에 다양합니다. 질문에 대해 대답을 하도록 구성된 데이터셋을 인코더와 디코더 구조로 학습한다면 주어진 질문에 답변할 수 있는 챗봇 또한 만들 수 있습니다.
훈련 데이터셋의 구성(질문-답변)
- 입력 문장: 오늘의 날씨는 어때?
- 출력 문장: 오늘은 매우 화창한 날씨야
트랜스포머(Transformer)
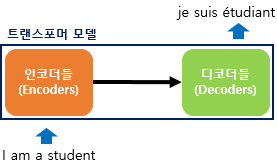
트랜스포머는 RNN을 사용하지 않지만 기존 seq2seq처럼 인코더에서 입력 시퀀스를 입력 받고, 디코더에서 출력 시퀀스를 출력하는 인코더-디코더 구조입니다. 다만, 다른 점은 인코더와 디코더라는 단위가 N개 존재할 수 있다는 점입니다!
이전 seq2seq 구조에서는 인코더와 디코더에 각각 하나의 RNN이 t개의 시점(time-step)을 가지는 구주였는데 이번엔 인코더와 디코더라는 단위가 N개로 구성되는 구조입니다.
트랜스포머의 인코더와 디코더
인코더와 디코더가 6개씩 존재하는 트랜스포머의 구조입니다. 위의 그림은 인코더로부터 정보를 전달받아 디코더가 출력 결과를 만들어내는데요.
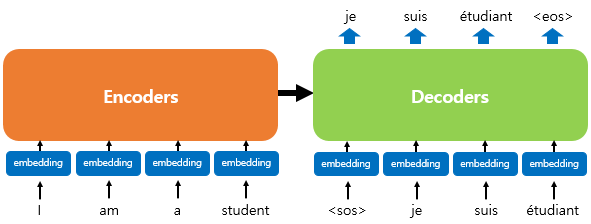
블랙박스로 가려져 있는 내부 구조는 열어보면 아래와 같습니다.
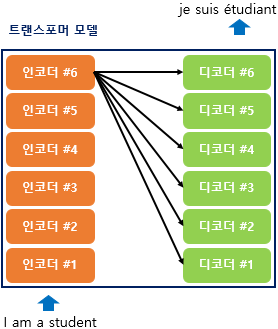
주황색 색깔의 도형을 인코더 층(Encoder layer), 초록색 색깔의 도형을 디코더(Decoder layer)라고 하였을 때,
- 입력 문장은 누적해 쌓아 올린 인코더의 층을 통해서 정보를 뽑아냄
- 디코더는 누적해서 쌓아 올린 디코더의 층을 통해 출력 문장의 단어를 하나씩 만들어가는 구조
이제 트랜스포머의 구조를 더 살펴보도록 하겠습니다!
