해당 글을 참고 전 알아야 할 것!
-
실습 프로젝트 내려 받는 곳
github 이동 -
책은 제공하는 notebook 파일을 기준으로 실습을 진행합니다.
❗ 그러므로 해당 실습에서 보여주는 경로와 제가 직접 작성한 경로 설정이 책과 다릅니다. 블로그 글은 당연 제 기준입니다.
❗ 저는 제공하는 노트북 파일을 사용하지 않았습니다. 제공하는 노트북 파일에는 이미 코드가 다 입력되어 있습니다. 다 지우고 다시 쳐보는 방법을 사용하거나 새로운 .ipynb 파일을 파줘서 실습을 진행해줍시다!
이거에 대한 설명이 책엔 자세히 안 나와 있어서 조금 당황스러웠습니다! shift+enter만 누르면 된다고 말해주다니...🤔
📚 책에서 제공하는 디렉터리 구조
실습에 필요한 파일은 'data' 폴더 안에, 실습 파일은 notebook 폴더 안에, output은 실습 후 데이터 처리가 끝난 완성 파일을 넣어둔 폴더 같습니다.
📚 제 디렉터리 구조


임을 참고 부탁드립니다.
그래서 저는 기본적으로 실습 진행 시 data를 불러오기 위해 상위 폴더로 두 번 이동해야 했고, ../../doit_pandas-master/data/파일이름 의 형식을 사용했습니다.
굳~이 이렇게 상세히 적는 이유는 저는 처음에 데이터 불러오는 작업부터 얼마나 어려운지 잘 알기 때문에 ^^; 그리고 실제로 작년에 데이터처리프로그래밍 수업을 들으면서도 느낀 거지만, 데이터 불러오는 것조차 못하는 사람이 많았다는 점... 물론 저도 아직도 서툽니다.😂 데이터를 불러오는데 수많은 방법이 있습니다. 여기는 이 책에선 pandas를 이용하는 방법만 알려줄 것 같긴 합니다.
그 뒤에 코드는 그냥 외우고 적용하고 적응하면 되지만, 데이터 불러오는 거에서 오래 걸릴 수 있습니다. 전 그랬거든요... 아니라면 당신은 재능충!🤗
그리고 그냥 가장 쉬운 방법은 한 폴더에 다 때려 박기! 그것도 나쁘지 않다고 생각합니다. 어차피 혼자 공부하는 거니까... 그러면 그냥 read_cvs('파일')만 해주면 되니까요. 아무튼 선택은 여러분들의 몫. 본격적으로 공부하러 가봅시다.
2-1. 데이터 집합 불러오기
데이터 불러오기
데이터 분석을 위해 데이터를 불러와야 합니다(넘나 당연한 말). 이때 불러오는 데이터를 데이터 집합이라 표현합니다. 첫 번째 실습에선 갭마인더(Gapminder) 데이터를 불러오겠습니다.
- 판다스 라이브러리 불러오기
import pandas as pd책에선 pandas만 불러오고 뒤에 몰랐지? pd라는게 있지롱😝 하는 방식이지만 그냥 미리 as pd 까지 해줍시다. (귀찮음)
notebook에서 실행 단축키는 'shift+enter'입니다.
- read_csv 메서드 사용
데이터 불러오려면 read_csv 메서드를 사용해야 합니다. 이 메서드는 기본적으로 쉼표(,)로 열이 구분되어 있는 데이터를 불러옵니다.
gabminder 파일은 tab으로 구분되어 있습니다. 그래서 이 파일을 불러올 때는 얘는 tab으로 구분되어 있어! 라고 알려줄 속성이 필요합니다.
파이썬에서는 '\t'이 tab을 의미합니다.
df = pd.read_csv('../../doit_pandas-master/data/gapminder.tsv', sep='\t')
print(df)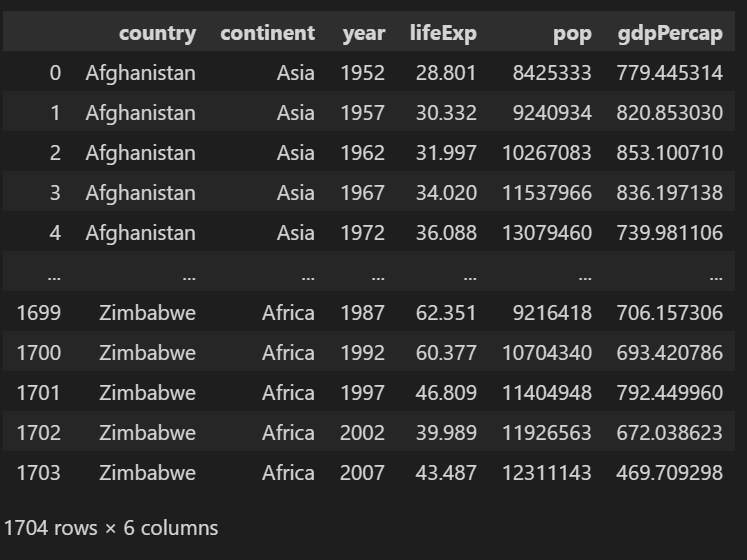
주피터는 print 하지 않아도 알려주지만 제가 주피터에 익숙해졌다가 파이썬에서 print를 치지 않는 실수를 굉장히 많이 하기 때문에 print를 일일히 해보겠습니다.🤣
시리즈와 데이터프레임
갭마인더 집합을 불러왔습니다. 이제 판다스에서 사용되는 자료형을 알아봅시다. 판다스는 데이터를 효율적으로 다루기 위해 Series와 DataFrame이라는자료형을 사용합니다.
데이터프레임은 엑셀에서 볼 수 있는 시트(sheet)와 동일한 개념입니다.
시리즈는 시트의 열 1개를 의미합니다.
파이썬으로 비유하면 데이터프레임은 시리즈들이 각 요소가 되는 딕셔너리라고 생각하면 됩니다.
불러온 데이터 집합 살펴보기
- read_csv 메서드는 데이터 집합을 읽어 들여와서 DataFrame 자료형으로 변환합니다.
데이터프레임에는 데이터분석에 유용한 메서드가 미리 정의되어 있습니다. 하나씩 살펴보겠습니다.
그리고 보통 read_csv라고 불러온 DataFrame을 변수 'df'로 저장합니다. data, original_data, dataset 등 변수 설정은 본인 마음대로!
데이터를 df에 저장하고 데이터 처리 전에 원래 파일을 그대로 저장해주고 싶을 때 copy를 사용하거나 (import copy 필요) 간단하게는 df2 = df 의 방법 등이 있습니다.
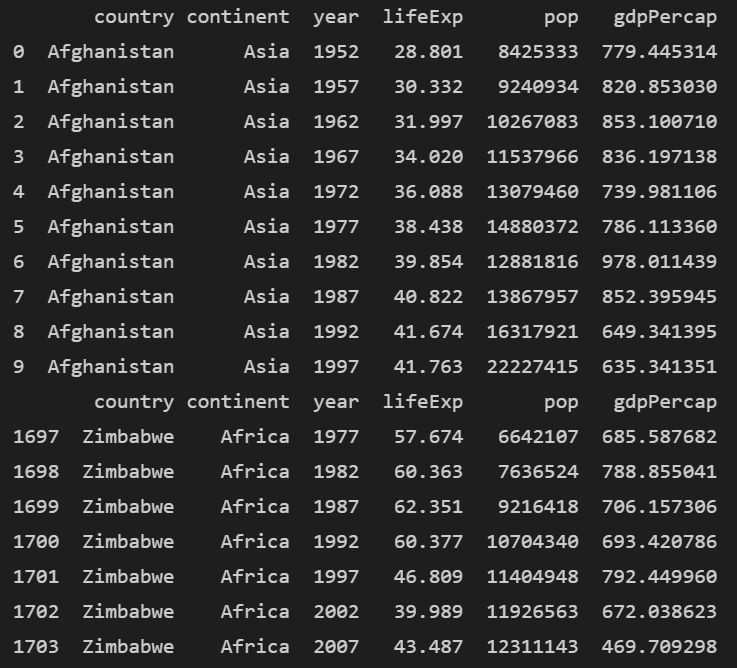
print(df.head())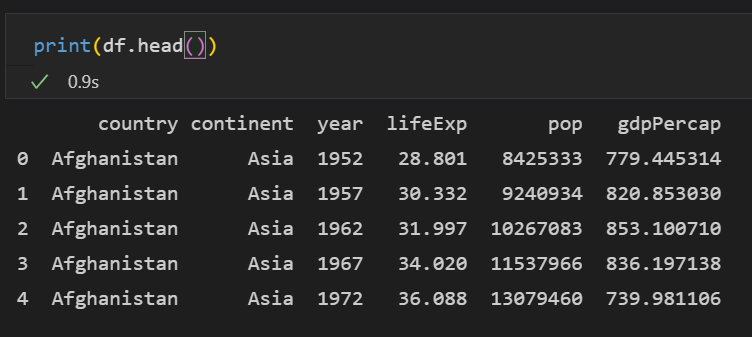
head()는 df의 가장 앞에 있는 5개의 행을 출력합니다.
print(df.tail())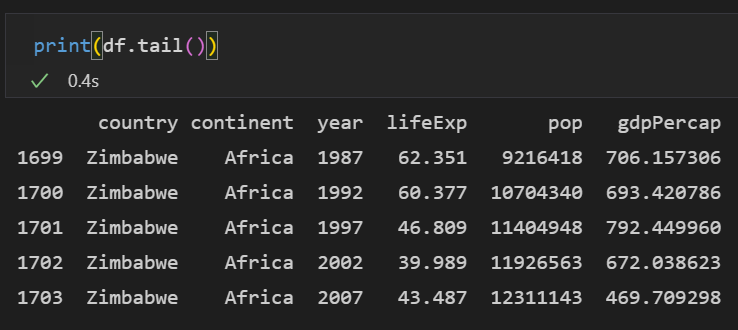
tail()도 있습니다. df의 가장 뒤에 있는 5개의 행을 출력합니다.
만약 10개를 보고 싶다면
print(df.head(10))
print(df.tail(7))의 방법도 가능합니다.
- 자료형 확인
이번엔 df에 저장된 데이터의 자료형이 무엇인지 확인하고 싶습니다.
print(type(df))
type() 안에 df를 넣어주면 됩니다.
- 데이터의 행과 열의 크기 확인
데이터에 몇 개의 행과 열이 잇는지 정보를 알고 싶다면
print(df.shape)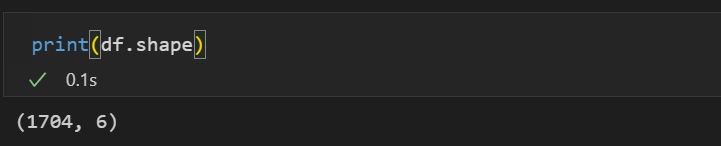
을 이용하면 됩니다. shape에는 ()가 붙지 않습니다. 뭔가 뒤에 괄호의 유무는 얘는 있었다, 없었다 외우는 것보다 쳐보면서 error 뜨면 고치는게 더 나은 듯 합니다.
- 열 속성 확인
아까 shape을 통해 행과 열의 갯수는 알았는데 상세한 정보를 알고 싶습니다. 보통 columns은 이 데이터의 속성을 파악하기 위해 가장 중요한 정보가 될 테니까요.
print(df.columns)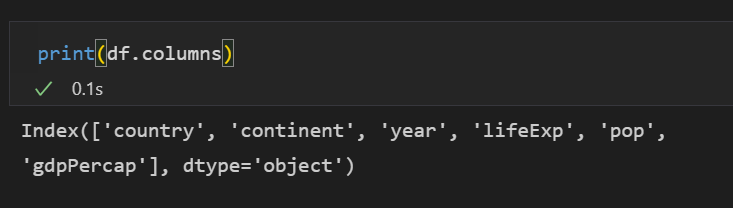
총 6개의 열이 있습니다.
- 데이터프레임을 구성하는 값의 자료형은 데이터프레임의 dtype 속성이나 info 메서드로 쉽게 확인할 수 있습니다.
print(df.dtypes)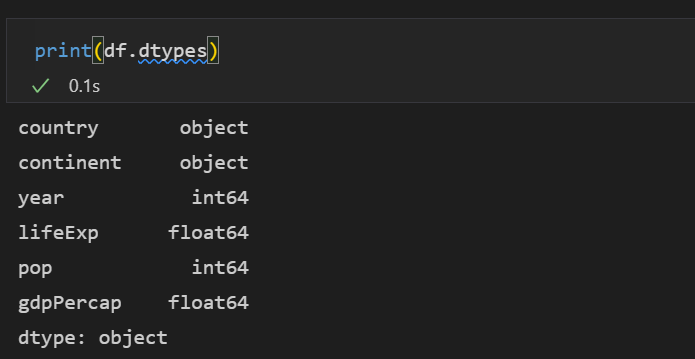 ,
,
print(df.info())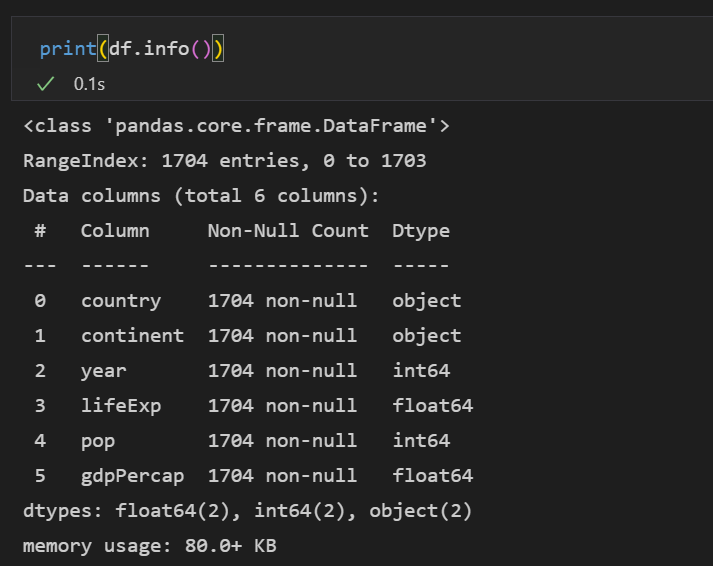
아까 앞의 type()과는 살짝 다릅니다. type은 데이터 집합의 자료형의 결과를 알려줍니다.
dtype은 각 컬럼별의 데이터 속성을 알려줍니다. gapminder 자료는 object, int64, float64 등이 조회됩니다.
info는 type과 dtype으로 조회 가능한 모든 정보를 모두 보여줍니다.
판다스와 파이썬 자료형 비교
판다스를 공부하며 자주 다루게 될 자료형은 아래와 같습니다. 그리고 이는 파이썬의 자료형과 다르게 인식한다고 합니다. 아래 표를 통해 참고 바랍니다.
| 판다스 자료형 | 파이썬 자료형 | 설명 |
|---|---|---|
| object | string | 문자열 |
| int64 | int | 정수 |
| float64 | float | 소수점을 가진 숫자 |
| datetime64 | datetime | 파이썬 표준 라이브러리인 datetime이 반환하는 자료형 |
