
저는 이지스퍼블리싱 출판사의 'Do it! 데이터 분석을 위한 판다스 입문'의 책으로 공부하고 정리합니다.🐼
실습 프로젝트 내려 받는 곳
자료는 이곳에서 다운로드 받을 수 있습니다.
2장
2-2. 데이터 추출하기
목차
1. 열 단위 데이터 추출하기
2. 행 단위 데이터 추출하기
3. 인덱스와 행 번호 개념 알아보기
4. loc 속성으로 행 데이터 추출하기
5. iloc 속성으로 행 데이터 추출하기
6. 슬라이싱 구문, range 메서드
열 단위 데이터 추출하기
데이터프레임에서 열 단위 데이터를 추출하려면 대괄호와 열 이름을 사용하면 됩니다. 열 이름은 따옴표를 사용하여야 합니다.
그 전 사용 데이터는 gapminder입니다.
import pandas as pd
df = read_csv('..경로/gapminder.tsv', sep='\t')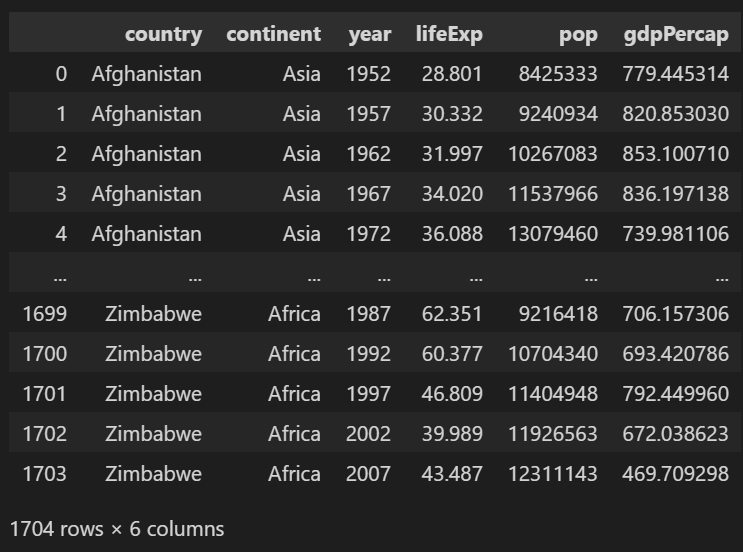
이렇게 생겼습니다.
해당 과정을 잘 모르겠다면? 👉 클릭
1. 열 이름이 country인 열을 추출하여 저장하기
country_df = df['country']
print(type(country_df))
print(country_df.head())
print(country_df.tail())notebook은 print를 사용하지 않고 변수명만 입력해도 값을 알려줍니다. 하지만 하나의 shell에서 출력시 print 구문을 사용해야 한다는 점을 알아주세요.
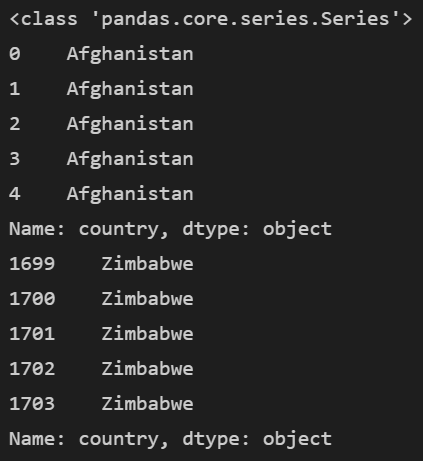
차례대로 열 속성, 앞의 5행, 뒤의 5행의 결과를 보여줍니다.
데이터프레임에서 열 하나를 추출했으니 series가 되었겠지요. 그래서 series라 뜨고, 5개씩 인덱스 번호와 함께 어떤 값이 있는지 보여줍니다.
2. 여러 개의 열 추출하기
이제 country, continent, year의 3개 열을 추출하겠습니다.
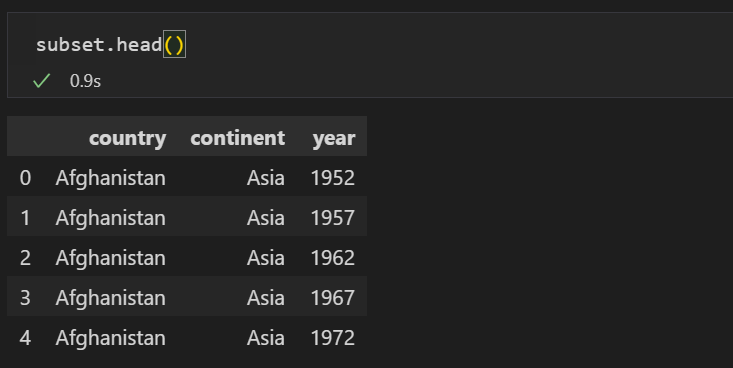
subset = df[['country', 'continent', 'year']]
print(type(subset))
print(subset.head())
print(subset.head())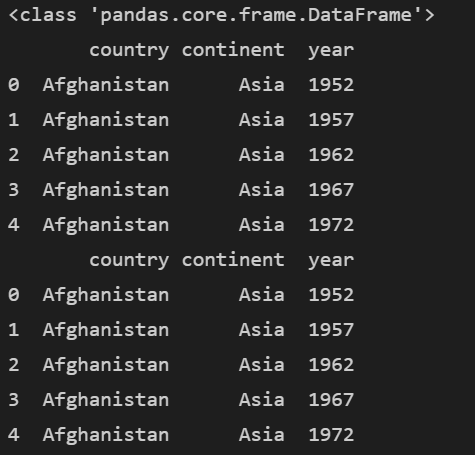
2개 이상의 열을 추출할 때는 시리즈가 아니라 데이터프레임 속성입니다. 그리고 추출한 열의 값이 잘 나왔음을 알 수 있습니다.
표로 보고 싶다면 print를 지우고 하나씩 실행해주세요. dataframe 자료형은 표로 자동으로 보여줍니다. 데이터 시각화에 특화된 notebook📚입니다.
시리즈와 데이터프레임이 뭔지 모른다면? 👉 클릭
행 단위 데이터 추출하기
열을 뽑았으니 행도 뽑아봅시다!
행 단위를 추출하기 위해선 loc, iloc라는 속성을 이용해야 합니다.
| 속성 | 설명 |
|---|---|
| loc | 인덱스를 기준으로 행 데이터 추출 |
| iloc | 행 번호를 기준으로 행 데이터 추출 |
제 생각엔 pandas 공부할 때 제일 헷갈리는 파트가 아닐까 생각이 듭니다.
저는 파이썬 모르는 채로 pandas만 배웠어서 처음엔 인덱스가 뭔지, 인덱스와 행이 무슨 차이가 있는 지도 몰랐습니다. 인덱스가 0부터 시작하는 것도 모르는 채로 그냥 공부했습니다.
하지만 이제 와서 느낀 거지만 python 공부 후에 pandas를 하는 게 당연합니다. 급해도 저처럼 돌아가는 길 말고 적어도 천천히 python 자료형을 공부 후에 오는 걸 추천합니다... 결국 모든 걸 처음부터 공부하는 절 보면 아실 거라 생각합니다... 이하 생략.
인덱스와 행 번호 개념 알아보기
print(df.head())다시 df를 불러와봅시다.
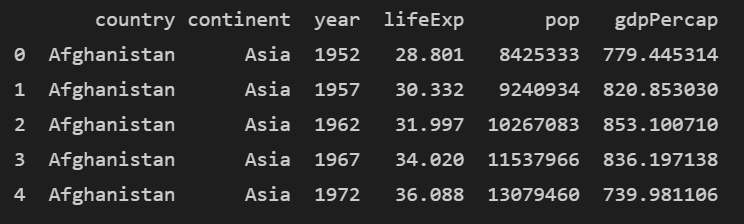
제일 왼쪽 열을 봐주세요.
0부터 시작하는 값을 보실 수 있을 것입니다. 그게 인덱스입니다. 인덱스는 보통 0부터 시작합니다. 데이터가 삭제되거나 추가되면 인덱스는 변합니다. 숫자가 아닌 문자열로 변경도 가능합니다.
인덱스 명을 바꾸는 것이 가능하단 얘기입니다. 반면엔 행 번호는 데이터의 순서를 알려주는 고유한 속성이라 생각하면 됩니다. 인덱스가 변화한다고 해서 행 번호가 바뀌는 건 아닙니다.
행 번호는 말 그대로 순서를 알려주기 위한 번호이며 정수 값을 가집니다. 데이터를 추출하는데 사용되며 실제 데이터프레임에서는 보여지는 값은 아닙니다.
loc 속성으로 행 데이터 추출하기
1. loc으로 행 데이터 추출하기
print(df.loc[0])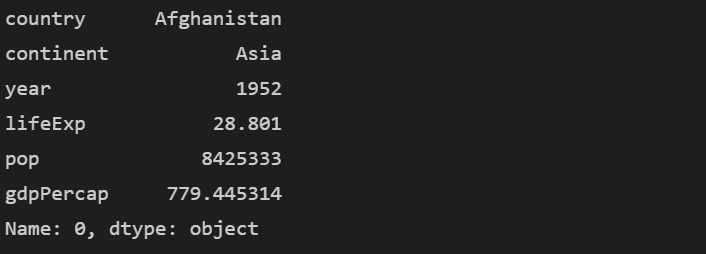
대괄호 안의 값은 인덱스 값입니다. 인덱스 0은 첫 번째 행입니다.
인덱스 0 = 첫 번째 행
그러면 해당 코드는 무엇을 출력할까요?
print(df.loc[-1])KeyError: -1마지막 행을 보여줄 것 같지만 그렇지 않습니다. 에러명도 KeyError입니다. 이는 즉 loc 속성에 -1이라는 key가 없는데 왜 썼냐... 이런 의미겠죠. 왜냐하면 loc는 인덱스를 기준으로 행을 추출하기 때문입니다. 인덱스에는 음수값의 속성이 없습니다.
-1로 마지막 행을 추출하는 건 조금 뒤에 다시 나옵니다.
2. 마지막 행 추출하는 방법
그렇다면 loc로 마지막 행을 추출하려면 마지막 인덱스 번호가 몇 번인지를 알아내야 합니다.
그 전에 행과 열의 정보를 알려주는 shape을 배웠습니다. shape은 (행 개수, 열 개수)를 알려주는 녀석입니다.
print(df.shape) # 행과 열의 개수를 알려줌
print(df.shape[0]) # 행 개수만 알려줌결과로는
(1704, 6)
1704가 나옵니다. 그러면 마지막 인덱스를 알았으니 우리는 마지막 행을 추출할 수 있습니다.
print(df.loc[1704])이라고 하면 또 keyerror가 나옵니다. (ㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋ) 왜냐하면... 다시 다시 돌아가서 shape은 행 개수입니다. 1704개의 행이 있습니다. 인덱스는 0부터 시작합니다. 그래서 1703을 해줘야 합니다.
print(df.loc[1703])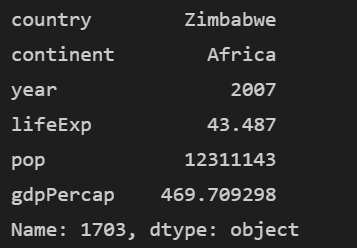
책에선 다른 방법도 설명 중입니다.
num_rows = df.shape[0]
last_index = num_rows -1
print(df.loc[last_index])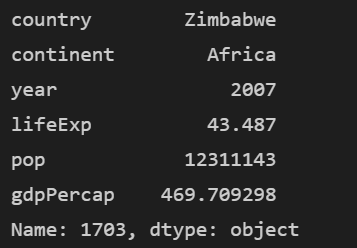
켁... 슬슬 피곤해지는 중.
3. tail 메서드를 이용해서 마지막 행 추출하기
tail()의 기본 속성은 마지막 행 5개를 추출해주는 것이었고 괄호 안에 숫자를 입력하면 마지막 행을 기준으로 그 개수만큼 추출해줍니다. 그냥 숫자를 넣어도 되고 n=1 의 식으로 작성해주어도 됩니다.
print(df.tail(1))
보여주는 형식은 다릅니다. 왜 다를까요? loc 속성으로 추출하는 데이터 자료형은 시리즈이고, tail은 데이터프레임의 속성으로 추출하기 때문입니다.
4. 특정 인덱스 추출하기
print(df.loc[[0,99,999]])
잘 뽑혀 나왔습니다!
iloc 속성으로 행 데이터 추출하기
1. iloc로 행 추출
iloc와 loc의 차이점은 iloc는 행 번호를 사용하여 데이터를 추출한다는 점이었습니다.
print(df.iloc[1])
print(df.iloc[99])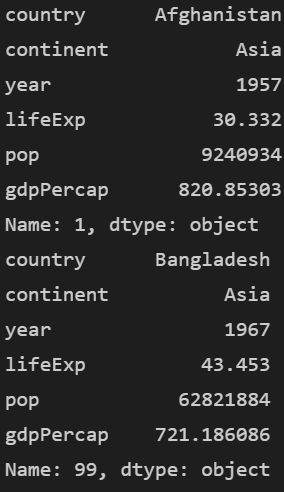
이 데이터는 행 번호와 인덱스 번호가 같다는 점을 유의해주세요.
2. 음수 사용 가능한 iloc
print(df.iloc[-1])이렇게 사용하면 마지막 행이 추출됩니다.
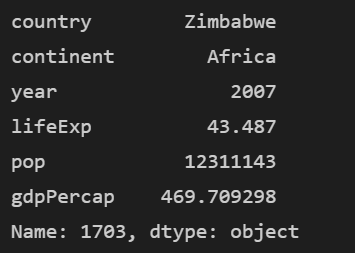
행 개수는 1704개가 맞습니다. 행 번호가 인덱스와 동일하게 0으로 시작한다는 점을 유의해서 봐주세요~
3. iloc로 데이털르 한 번에 추출하기
print(df.iloc[[0,99,999]])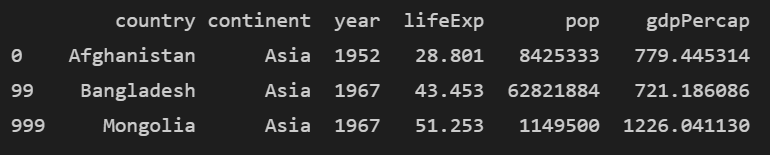
loc, iloc 속성 사용 방법
위 두 개의 속성을 더 잘 이용하기 위해서 추출할 데이터의 행과 열을 지정하는 방법이 있습니다.
df.loc[[행],[열]])
df.iloc[[행], [열]])
이렇게 행, 열을 지정하기 위해 슬라이싱 구문, range 메서드를 사용하면 됩니다.
1. 슬라이싱 구문으로 데이터 추출
- 모든 행의 데이터에 대해 year, pop 열을 추출하는 방법 👉 :
subset = df.loc[:, ['year', 'pop']]
print(subset.head())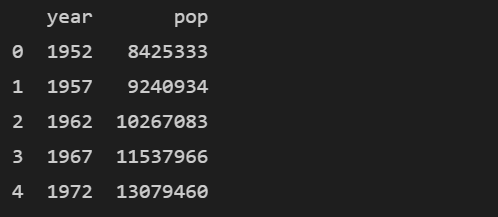
subset = df.iloc[:, [2,4,-1]]
print(subset.head())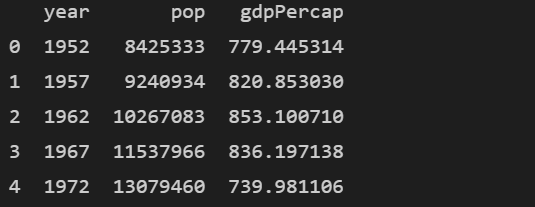
차이가 느껴지시나요? 행의 조건엔 모든 행을 추출한다는 조건 ':'이 동일하게 들어가 있습니다. 열은 조금 다릅니다. loc에는 컬럼명을 '' 안에 담아 지정해주었고, iloc에는 컬럼 번호를 지정해주었습니다.
loc, iloc는 지정해줘야 하는 열 속성이 다릅니다.
loc 👉 문자열 리스트
iloc 👉 정수 리스트
2. range 메서드로 데이터 추출
range 속성에 대해 조금 이해가 필요한데요, range 메서드는 지정한 정수 리스트를 반환하는 것 같지만 제너레이터를 반환합니다.
iloc 속성은 제너레이터 속성으로 데이터 추출이 불가하여 이를 list로 변환 시켜줘야 합니다.
list(range(5))
처럼 말이죠. 이렇게 리스트로 변환 시키면 iloc의 열 속성 값에 들어갈 수 있습니다.
small_range = list(range(5))
print(small_range)
print(type(small_range))
[0,1,2,3,4]
<class 'list'>subset =df.iloc[:, small_range]
print(subset.head())
3. range 활용
range(0,6,2)를 이용해 봅시다. 0부터 5까지의 컬럼에서 2만큼 건너뛰는 제너레이터가 생성될 것이고 이를 list로 변환 시켜서 사용해 봅시다.
small_range = list(range(0,6,2))
subset =df.iloc[:, small_range]
print(subset.head())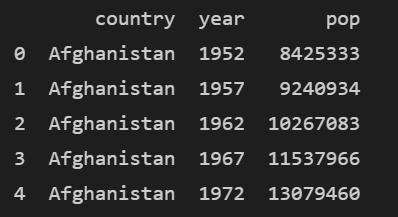
4. 슬라이싱 구문과 range 메서드 비교하기
그런데 range를 사용하는 건 너무 불편하죠. 그래서 슬라이싱 구문을 더 선호합니다.
list(range(5))를 사용한 값은 [:5]와 동일합니다.
subset = df.iloc[:, :5]
print(subset.head())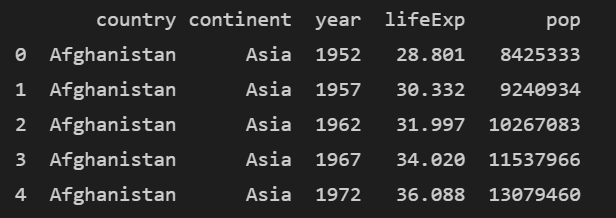
5. 0:6:2
그러면 list(range(0,6,2))는 어떻게 표현할까요? 슬라이싱 구문으로는 이와 같습니다. 👉 [0:6:2]
subset =df.iloc[:, 0:6:2]
print(subset.head())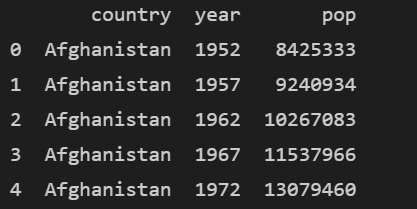
6. loc, iloc 속성 자유자재로 사용하기
iloc 속성으로 0,99,999번째의 행의 0,3,5번째 열 데이터를 추출해봅시다.
print(df.iloc[[0,99,999], [0,3,5]])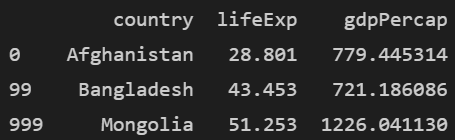
7. loc로 6번에서 불러온 데이터 추출해보기
iloc가 더 간편하긴 하지만 나중에 코드만 봐서는 어떤 데이터를 불러온 것인지 잘 모를 수 있습니다. loc는 열 이름을 사용하기 때문에 무슨 데이터를 불러왔는지는 한 눈에 알 수 있습니다.
print(df.loc[[0,99,999], ['country', 'lifeExp', 'gdpPercap']])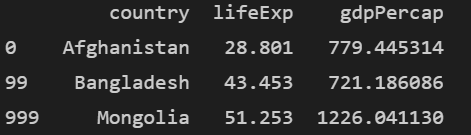
2개 이상의 행과 열을 추출할 땐 대괄호가 한 번 더 필요합니다!
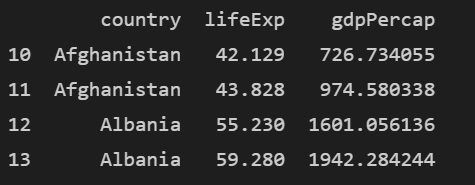
8. 인덱스가 10인 행부터 13번인 행의 country, lifeExp, gdpPercap 열 데이터 추출하는 코드
직접 쳐봅시다~
print(df.loc[[10:13],['country', 'lifeExp', 'gdpPercap']])전 또 오류를.............
위는 잘못된 코드입니다. 왜냐하면 행 번호를 대괄호 안에 넣어주었기 때문에 ^^...
print(df.loc[10:13,['country', 'lifeExp', 'gdpPercap']])고쳐주었습니다.(머쓱🤣)
이렇게 loc, iloc의 긴 여정이 끝이났습니다!
