목차
- XOR Problem
- Motivation
- Perceptron
- Matrix Multiplication
- XOR and Simple Neural Network
1. XOR and Simple Neural Network
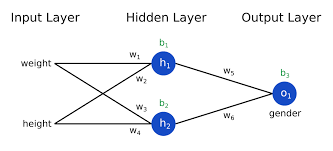
결국은 앞에서 계속 반복해서 그렸던 위의 그림이 Double layer perceptron이라 할 수 있습니다.
이렇게 layer(층)을 계속 깊게 쌓아 올라가는 것을 Deep Learning이라 합니다.
앞의 이전 글에서 함수를 S(x)로 표현을 했는데요.
그 이유는 Sigmoid에서 이름을 따왔기 때문입니다.
2. Sigmoid Function
Sigmoid function은 분류 작업을 할 때 대표적으로 쓰입니다.
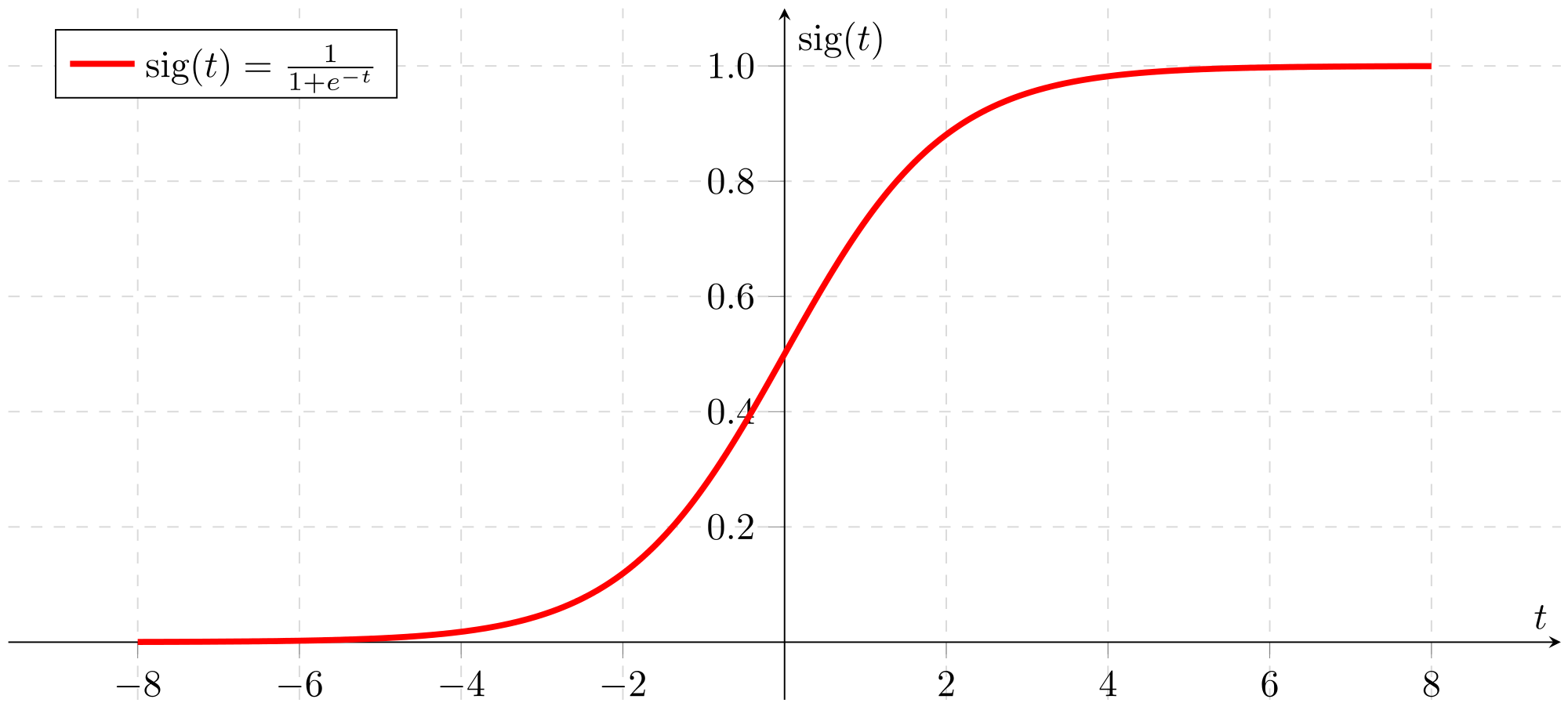
왜 그럴까요?
분류한다는 것은 classification이죠. 머신러닝에서는 분류와 회귀 문제로 이어지는데, sigmoid는 classification 문제를 해결할 때 대표적으로 쓰이는 함수입니다.
sigmoid 이외에도 다양한 함수들을 사용할 수 있습니다.
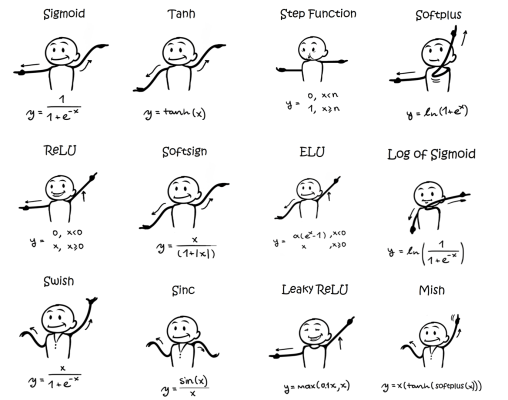
이런 함수들을 참고로 activation function이라 부릅니다!
3. Cross Entropy Error
딥러닝을 하기 위해 Loss라는 개념이 있었습니다.
w 값을 최적화 시키는 과정도 있었고, loss 값을 구하는 방식도 중요한대요.
loss 중에 하나인 Cross Entropy Error라는 것이 있습니다.
Cross Entropy Error은 classfication 할 때 굉장히 많이 쓰이는 loss입니다.
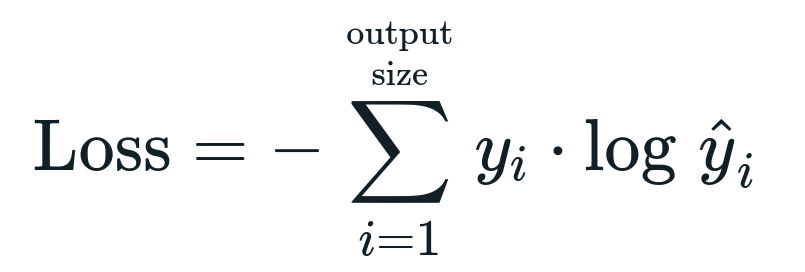
Cross Entropy Error의 식은 위와 같고 아래 예시를 통해 간단히 보고 가겠습니다.

train 시켜보기
loss_arr = []
for num_epoch in range(epoch):
optimizer.zero_grad()
prediction = model(X)
loss = loss_function(prediction, y) # (예측값, 실제값)
loss.backward()
optimizer.step()
loss_arr.append(loss.item())
if num_epoch % 5000 == 0:
print("epoch ==> {}\tloss ==> {:.5f}".format(num_epoch, loss))
print("Finish train")training 후, weight와 bias를 확인할 수 있습니다.

AI/ML Engineer