저는 참고 자료에 적힌 책을 바탕으로 개념을 정리하고 있습니다. 해당 파트는 5-6에 해당됩니다.
참고 자료
📚 딥러닝 교과서, 출판사: 이지스 퍼블리싱
모델은 복잡한데 비해 그만큼 충분한 데이터가 제공되지 않으면 모델이 데이터를 암기해 버리는 상황이 발생합니다.
이런 경우 과적합이 되는데, 과적합을 막는 가장 근본적 방법은 훈련 데이터를 늘리는 방법입니다.
훈련 데이터셋 크기가 커질수록 훈련 오류가 증가하고 테스트 오류는 감소하여 두 곡선의 차가 나타내는 일반화 오류 또는 과적합의 정도가 줄어듭니다.
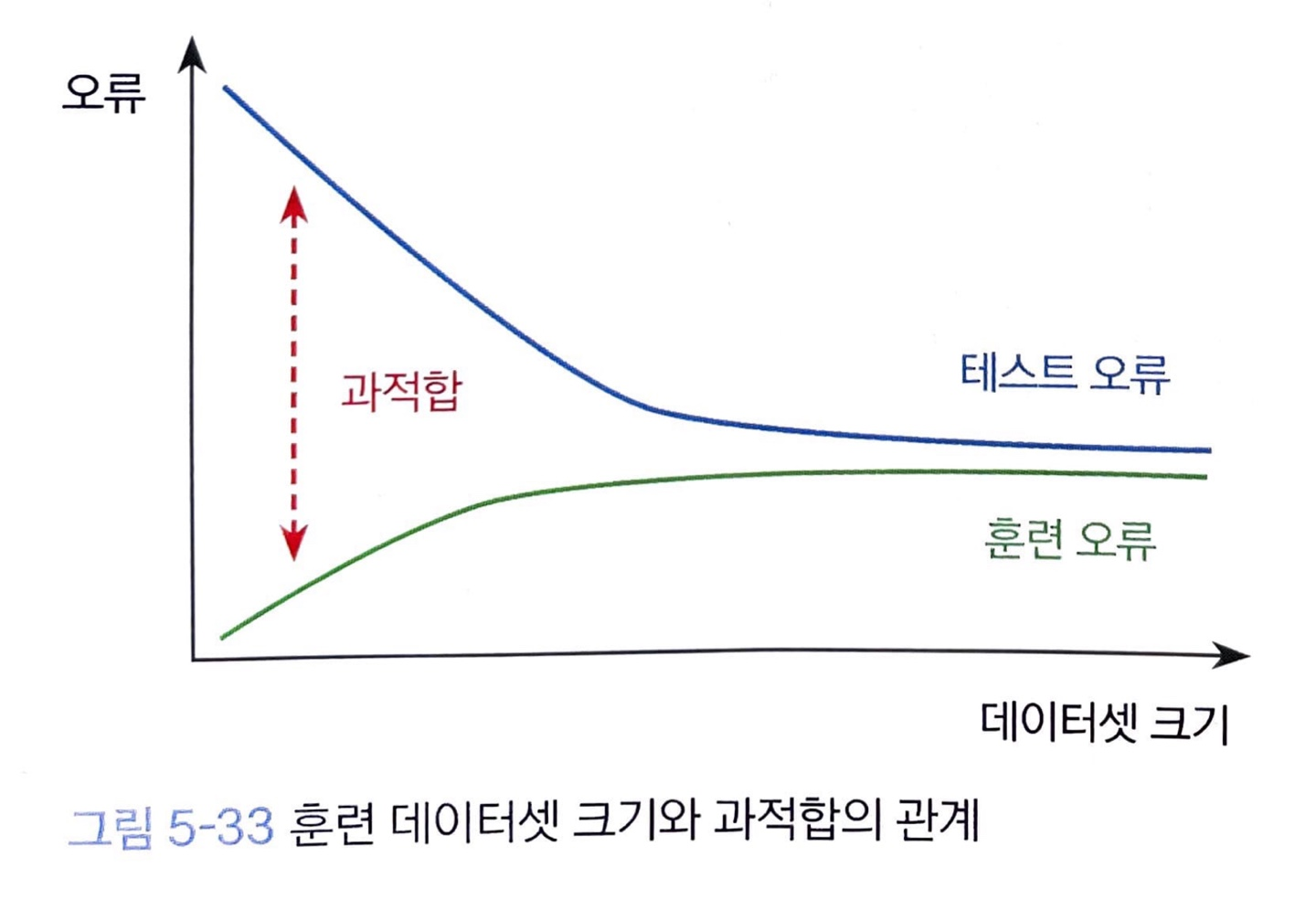
하지만 언제나 충분한 데이터가 있는 것은 아닙니다.
데이터를 수집해서 큰 데이터셋을 만드는 방법보다 좀 데이터를 늘려주는 방법이 필요합니다.
데이터 증강(Data augmentation) 기법은 훈련 데이터셋을 이용해서 새로운 데이터를 생성하는 기법입니다.
데이터 증강 기법
데이터 증강 기법 중 가장 기본적인 증강 방법은 훈련 데이터를 조금씩 변형(transformation)해서 새로운 데이터를 만드는 방법입니다.
또 훈련 데이터의 분포를 학습해서 생성 모델(geneartive model)을 만든 뒤에 새로운 데이터를 생성하는 방법이 있습니다.
이 경우에는 훈련 데이터의 분포를 따르는 검증된 데이터를 바로 얻을 수 있습니다.
또한, 생성 모델을 이용하면 더 쉽게 현실감 있는 데이터로 합성하거나 변환할 수 있습니다.
데이터 증강 방식
데이터를 확률적으로 변형하면 무한히 많은 변형이 생기므로 훈련 과정에서 실시간으로 데이터를 증강합니다.
훈련 데이터를 읽어서 모델에 입력하기 전에 데이터를 증강합니다.
매번 다른 형태가 되도록 변형하여 무한히 많은 데이터가 있는 것과 같은 효과를 봅니다.
클래스 불변 가정
데이터 증강을 할 때는 클래스 불변 가정(class-invariance assumption)을 따라야 합니다.
클래스 불변 가정은 데이터를 증강할 때 클래스가 바뀌지 않도록 해야 한다는 가정입니다.
만약 데이터 증강 과정에서 클래스의 결정 경계를 넘어서면 다른 클래스로 인식을 하기 때문에, decision boundary 안에서 데이터를 변형해야 합니다.
저 같은 경우는 object detection을 할 때, 변형(transformation)을 시켜주면 label 값이 변해서 증강을 시도했다가 실패했던 기억이 나네요.
더 쉬운 예로, MNIST 숫자 '6'을 90도 회전시키면 '9'가 나옵니다. 이 경우는 클래스가 바뀌는 경우인데요.
숫자를 회전 시키면 변형된 이미지가 클래스 경계 지점에 속하게 돼서, 주의해야 합니다.
데이터 증강 방식 선택
데이터 증강 방식은 데이터의 종류와 문제에 따라 매우 다양합니다.
만일 이미지 분류 문제를 푼다면 이미지 이동, 회전, 늘리기, 좌우/상하 대칭, 왜곡, 잡음 추가, 색깔 변환, 잘라내기, 떼어내기 등의 다양한 방법이 있습니다.
최근에는 데이터 증강 방식을 자동으로 찾아내는 자동 데이터 증강(automatic data augmentation) 기법이 연구되고 있다고 합니다.
