Cross Entropy 개념은 딥러닝 분류 모델 학습의 기초를 이룹니다. 그 외에도 엔트로피 개념이 활발하게 쓰이는 분야를 하나만 더 짚어보자면 의사결정나무(Decision Tree) 계열의 모델일 것입니다.
의사결정나무(Decision Tree)
하나의 데이터셋으로 예시를 들며 설명을 해보겠습니다. 아래와 같은 DataFrame이 있습니다.
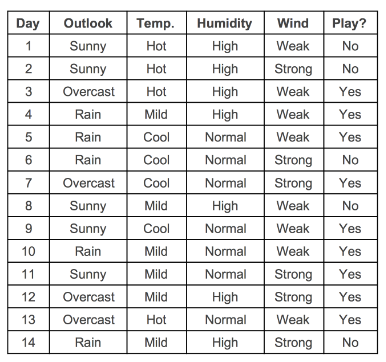
컬럼은 총 4개입니다. 여기서 'Play?(Yes/No)'가 label입니다.
- Outlook : 전반적 날씨 (Sunny(맑은), Overcast(구름 낀), Rainy(비 오는))
- Temperature : 기온 정보(섭씨온도)
- Humidity : 습도 정보 (수치형 변수(%), 범주형으로 변환된 경우 (high, normal))
- Wind : 풍량 정보 (TRUE(바람 붊), FALSE(바람 안 붐) )
의사결정트리는 가지고 있는 데이터에서 어떤 기준으로 데이터를 나눴을 때, 나누기 전보다 엔트로피가 감소하는지를 따집니다. 엔트로피가 감소하면 모델 내부에서는 정보 이득(Information Gain)을 얻었다고 보는 관점입니다. 엔트로피 증가가 정보 손실량이라고 정의하는 것과 반대의 관점입니다!
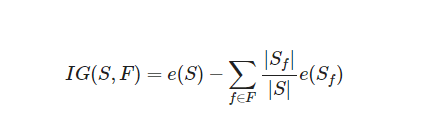
- S : 전체 사건의 집합
- F : 분류 기준으로 고려되는 속성(feature)의 집합
- f in F∈f : f는 F에 속하는 속성 (예를 들어 F가 Outlook일 때, f는 Sunny, Overcast, Rainy 중 하나가 될 수 있다. )
- S_f: f 속성을 가진 S의 부분집합
- |X∣ : 집합 X의 크기(원소의 개수)
- e(X) : X라는 사건 집합이 지닌 엔트로피
위 수식 IG(S,F)는 F라는 분류 기준을 선택했을 때, 엔트로피를 전체 사건의 엔트로피에 빼준 값입니다.
즉 분류 기준 채택을 통해 얻은 정보 이득의 양을 말합니다.
먼저 e(S)부터 구해보겠습니다. 전체 14가지의 경우 중 play하는 경우가 9번이고 하지 않은 경우는 5번입니다.
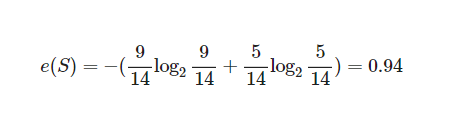
그럼 F가 Outlook일 때, 즉 f가 sunny, Overcast, Rainy 중 하나일 때의 엔트로피를 구해보겠습니다.
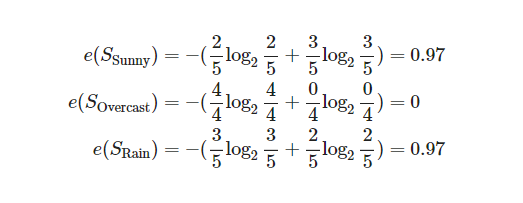
그러므로 정보 이득을 정리해보겠습니다.
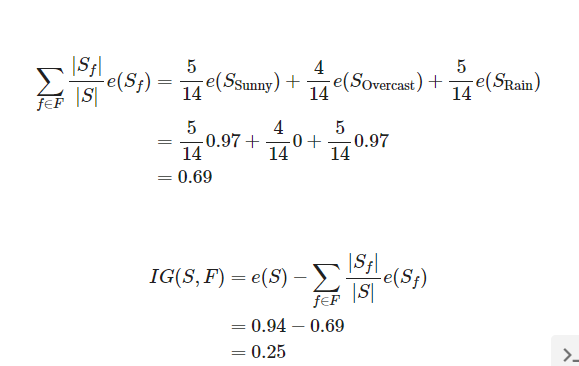
이런 방식으로 IG(S,F)를 계산합니다.
모든 분류 기준 F에 대해 정보 이득을 계산해서 가장 정보 이득이 큰 순서대로 전체 사건을 2등분합니다. 그 후 다시 분류 기준으로 위에서 했던 것과 동일하게, 첫 번째로 사용했던 기준으로 나눈 절반의 사건 집합 안에서의 정보 이득을 계산하는 방식입니다.
이렇게 사건의 분류 기준을 세워나가며 세부 분류 기준을 찾아갑니다. 이후엔 전체 사건 분류 기준이 트리 구조가 되기 때문에 이를 의사결정나무(Decision Tree)라고 부릅니다.
그렇다고 엔트로피가 낮은 쪽으로 간다는 것이 무조건 정교한 분류는 아닙니다. 왜 그럴까요?
이제 실습을 통해서 의사결정나무를 시각화해보겠습니다.
실습
위의 데이터셋 말고 이번 실습에서 사용할 데이터셋은 피마 인디언 데이터셋입니다. Pima Indians Diabetes Database
필요한 모듈
import pandas as pd
import numpy as np
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn import metricsData Load
import os
csv_path = os.getenve('HOME')+'/aiffel/information_theory/diabetes.csv'
col_names = ['pregnant', 'glucose', 'bp', 'skin', 'insulin', 'bmi', 'pedigree', 'age', 'label']
df = pd.read_csv(csv_path, header=0, names=col_names)
df.head()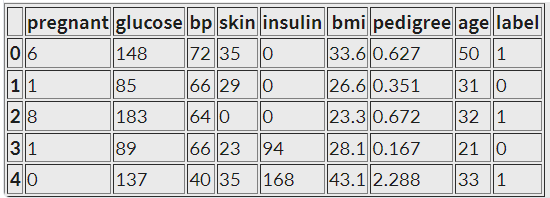
Dataset 준비, Split train, test
feature_cols = ['pregnant', 'insulin', 'bmi', 'age', 'glucose', 'bp', 'pedigree']
x = df[feature_cols]
y = df.label
# Split dataset into training set and test set
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=1)모델 학습
# Decisio Tree 모델 학습
# Create Decision Tree classifier object
clf = DecisionTreeClassifier()
# Train Decision Tree Classifier
clf = clf.fit(X_train y_train)
# Predict the respnse for the dataset
y_pred = clf.predict(X_test)
print("Accuracy:", metrics.accuracy_score(y_test, y_pred)
Accuracy: 0.683982683982684여러 분은 몇의 Accuracy가 나왔나요? 아마 약 60% 후반에 나올 듯합니다.
Decsion Tree의 장점은 어떻게 모델이 이런 결과를 내었는지 분류 기준을 따져보고 시각화를 통한 원인 추적이 가능한 것입니다. 다음과 같이 방금 학습시킨 Decision Tree 모델을 시각화해 보겠습니다.
데이터 시각화
from sklearn.tree import export_graphviz
from six import StringIO
from IPython.display import Image
import pydotplus
dot_data = StringIO()
export_graphiviz(clf,
out_file=dot_data,
filled=True,
rounded = True,
special_characters = True,
feature_names=feature_cols,
class_names=['0', '1'])
graph = pydotplus.graph_from_dot_data(dot_data.getvalue())
graph.write_png('diabetse1.png')
Image(graph.create_png(), retina=True)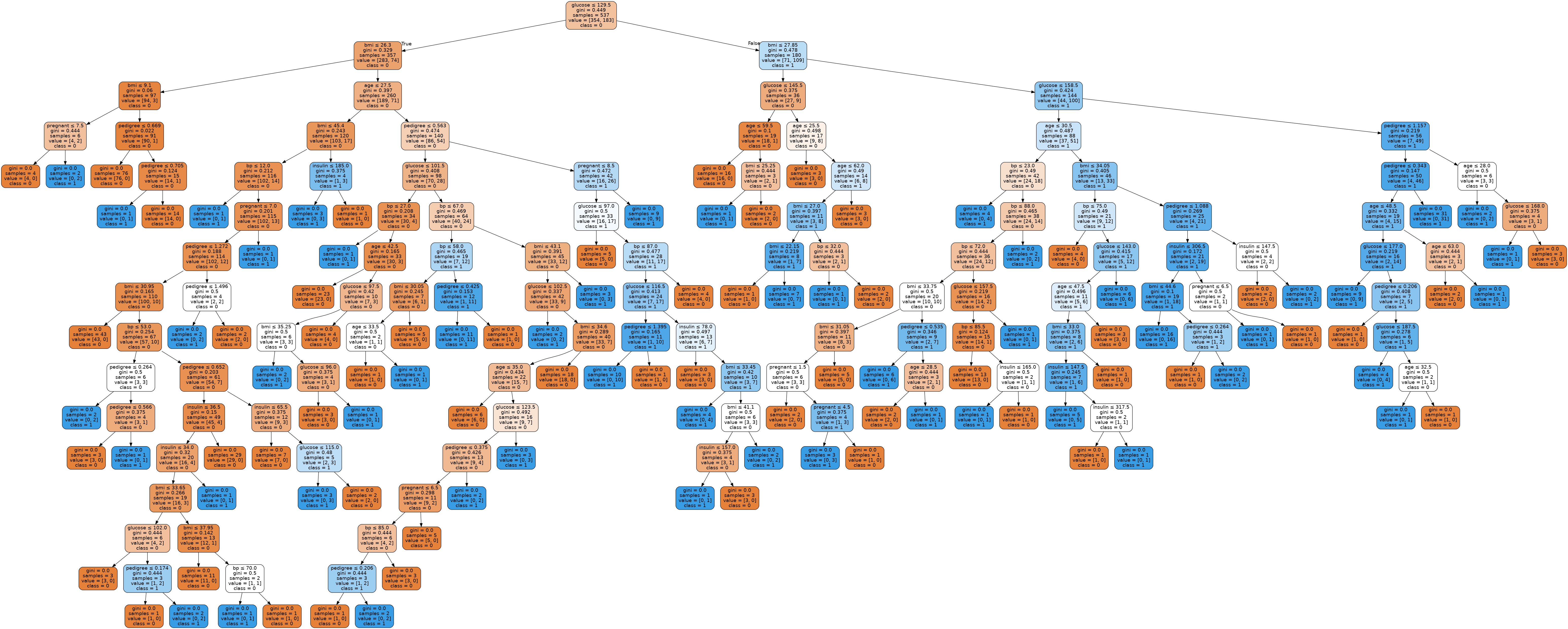
Wow... 엄청난 트리가 나왔네요. 여기서 사용한 정보의 총량을 알아보겠습니다. 정보 이득이 되지 않은 Impurity를 측정해 보겠습니다. 이게 낮을 수록 많은 정보를 사용했다는 뜻이겠죠?
Impurity 측정
ccp_path1 = clf.cost_complexity_pruning_path(X_train, y_train)
ccp_path2 = clf.cost_complexity_pruning_path(X_test, y_test)
print(np.mean(ccp_path1.impurities))
print(np.mean(ccp_path2.impurities))
0.153053671865334
0.14633934707314158위 두 가지 결과를 볼 때 우리가 학습시킨 Decision Tree 는 정보 이득을 최대화할 수 있는 지점까지 극한적으로 많은 분류 기준을 적용한 경우임을 알 수 있었습니다. 근데 이게 좋은 걸까요?
비교 실험을 해 보겠습니다. 우리는 Decision Tree를 3depth까지만 만들어보겠습니다.
max_depth 조절
clf = DecisionTreeClassifier(criterion='entropy', max_depth=3)
# Train Decision Tree Classifier
clf = clf.fit(X_train, y_train)
# Predict the response for test dataset
y_pred = clf.predict(X_test)
# Model Accuracy, how often is the classifier correct?
print("Accuracy: ", metrics.accuracy_score(y_test, y_pred)
Accuracy: 0.7705627705627706Depth 길이를 더 짧게 조절해주었더니 Accuracy가 훨씬 더 좋아졌습니다!👏
이때 트리 구조 시각화 및 남은 엔트로피 총량을 다시 조회해보겠습니다.
데이터 시각화, Impurity 조회
dot_data = StringIO()
export_graphiviz(clf,
out_file=dot_data,
filled=True,
rounded = True,
special_characters = True,
feature_names=feature_cols,
class_names=['0', '1'])
graph = pydotplus.graph_from_dot_data(dot_data.getvalue())
graph.write_png('diabetse2.png')
Image(graph.create_png(), retina=True)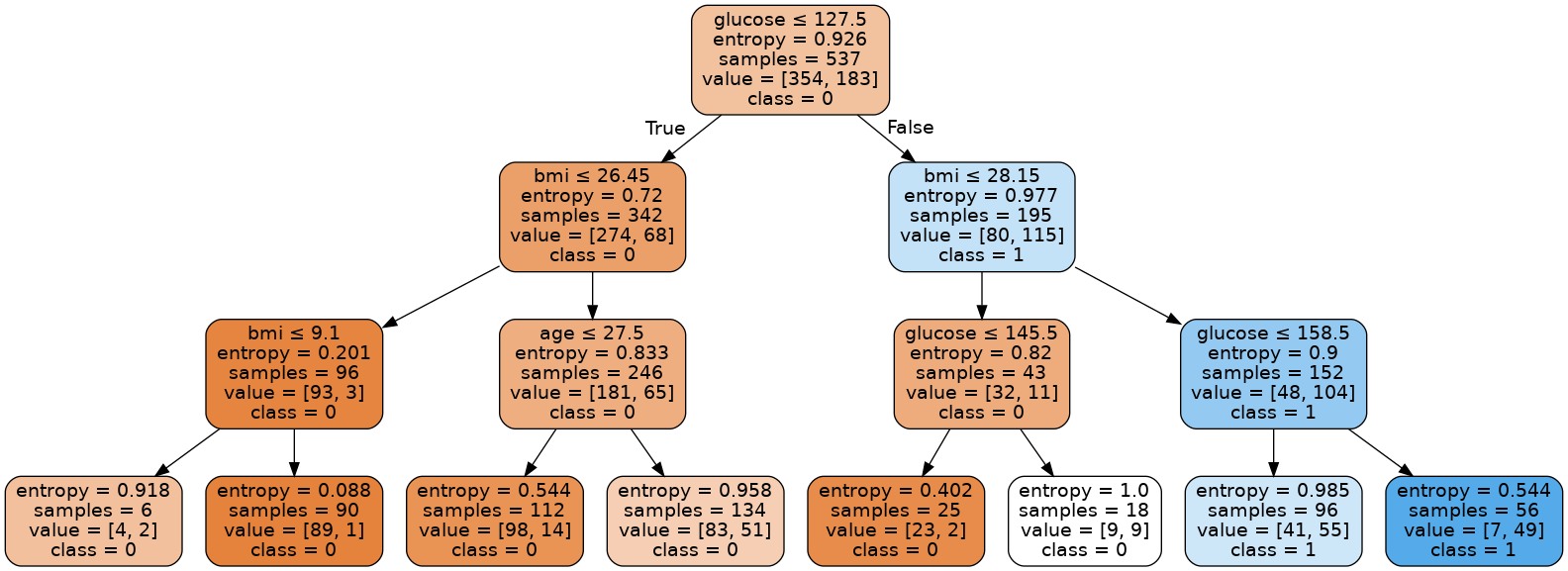
# 정보이득이 되지 않고 남은 Impurity 총량 측정
ccp_path1 = clf.cost_complexity_pruning_path(X_train,y_train)
ccp_path2 = clf.cost_complexity_pruning_path(X_test,y_test)
print(np.mean(ccp_path1.impurities))
print(np.mean(ccp_path2.impurities))
0.7474881472739515
0.6878691771636323분명히 엔트로피 기준으로 훨씬 더 많은 정보 이득을 얻을 수 있었습니다. 하지만 분류 기준을 더 세우지 않았습니다. 그리고 이 결과가 모델의 정확도를 향상하는데 더 도움을 주었다는 것을 확실하게 살펴보았습니다.
무조건적인 정보 이득이 좋지 않은 이유는 의사결정나무의 특성 때문입니다.
Decision Tree의 분류 기준은 임의로 정하기 때문
가지를 아래로 더 넓게 펼쳐서 엔트로피를 떨어뜨릴 수 있지만, 그것은 결국 Overfitting 의 결과를 낳게 됩니다. 시각화를 통해 비교해 보았을 때, 나무의 복잡도를 볼 수 있었죠?
하지만 다양한 분류 기준을 가진 Decision Tree 여러 개를 앙상블한 Random Forest 모델은 이런 문제점을 극복해줍니다. 이는 훌륭한 성능을 보여주기도 합니다!
오늘의 학습은 여기에서 끝이 났고, Depth 설정을 통해 최고 향상된 Accuracy를 찾아보세요!
max_depth 설정
max_depth = 2 -> Accuracy: 0.7705627705627706
max_depth = 4 -> Accuracy: 0.7922077922077922
max_depth = 5 -> Accuracy: 0.7662337662337663
max_depth = 10 -> Accuracy: 0.7489177489177489
