SRGAN을 간단하게 구현해보겠습니다. 이전 SRCNN을 실습(보러가기)할 때 사용했던 DIV2K 데이터셋을 사용합니다.
목차
- 데이터 준비하기 - DIV2K
- SRGAN 구현하기
- SRGAN 학습하기
- SRGAN 테스트하기
1. 데이터 준비
SRCNN은 저해상도 이미지에 대해 interpolation하여 고해상도 이미지 크기로 맞춘 후에 입력으로 사용했었습니다.
SRGAN은 interpolation 과정을 거치지 않습니다.
import cv2
import numpy as np
import matplotlib.pyplot as plt
import tensorflow_datasets as tfds
# 데이터 불러오기
train, valid = tfds.load(
"div2k/bicubic_x4",
split=['train', 'validation'],
as_supervised=True
)
def preprocessing(lr, hr):
hr = tf.cast(hr, tf.float32) / 255.
# 이미지의 크기가 크므로 (96,96,3) 크기로 임의 영역을 잘라내어 사용합니다.
hr_patch = tf.image.random_crop(hr, size=[96,96,3])
# 잘라낸 고해상도 이미지의 가로, 세로 픽셀 수를 1/4배로 줄입니다
# 이렇게 만든 저해상도 이미지를 SRGAN의 입력으로 사용합니다.
lr_patch = tf.image.resize(hr_patch, [96//4, 96//4], "bicubic")
return lr_patch, hr_patch
train = train.map(preprocessing).shuffle(buffer_size=10).repeat().batch(8)
valid = valid.map(preprocessing).repeat().batch(8)2. SRGAN 구현하기
먼저, 저해상도 이미지를 입력받아 고해상도 이미지를 생성하는 Generator를 구현해 보겠습니다. SRGAN의 Generator 부분은 아래와 같습니다.
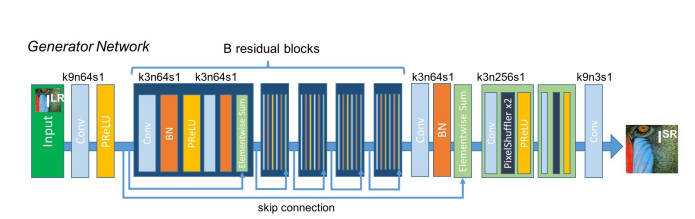
- k9n64s1: Conv layer 내의 Hyperparameter 설정에 대한 정보
- k: Kernel size
- n: 사용한 필터의 수
- s: strride
Tensorflow로 구현한다면 Conv2D(filters=64, kernel_size=9, strides=1, padding="same")처럼 작성할 수 있습니다.
추가로 모든 stride가 1인 convolutional layer에는 패딩을 통해 출력의 크기를 계속 유지합니다.
SRGAN의 Generator에는 skip-connection을 가지고 있으며, 이는 Sequential API로 구현할 수 없으므로 Functional API를 이용해 구현하겠습니다.
위 Generator 그림에서 각 layer를 따라 비교해봅시다.
from tensorflow.keras import Input, Model, layers
# 그림의 파란색 블록을 정의합니다.
def gene_base_block(x):
out = layers.Conv2D(64, 3, 1, "same")(x)
out = layers.BatchNormalization()(out)
out = layers.PReLU(shared_axex=[1,2])(out)
out = layers.Conv2D(64, 3, 1, "same")(out)
out = layers.BatchNormalization()(out)
return layers.Add()([x,out])
# 그림의 뒤쪽 연두색 블록을 정의합니다.
def upsample_block(x):
out = layers.Conv2D(256, 3, 1, "same")(x)
# 그림의 PixelShuffer라고 쓰여진 부분을 구현합니다.
out = layers.Lambda(lambda x: tf.nn.depth_to_space(x,2))(out)
return layers.PReLU(shared_axes=[1,2])(out)
# 전체 Generator을 정의합니다.
def get_generator(input_shape=(None, None, 3)):
inputs = Input(input_shape)
out = layers.Conv2D(64, 9, 1, "same")(inputs)
out = residual = layers.PReLU(shared_axes=[1,2])(out)
for _ in range(5):
out = gene_base_block(out)
out = layers.Conv2D(64, 3, 1, "same")(out)
out = layers.BatchNormalization()(out)
out = layers.Add()([residual, out])
for _ in range(2):
out = upsample_block(put)
out = layers.Conv2D(3, 9, 1, "same", activation='tanh')(out)
return Model(inputs, out)생성된 고해상도 이미지와 원본 고해상도 이미지 사이에서 판별해내는 Discriminator을 아래 그림에 따라 구현하겠습니다!
Generator과 마찬가지로 Functional API를 사용합니다.
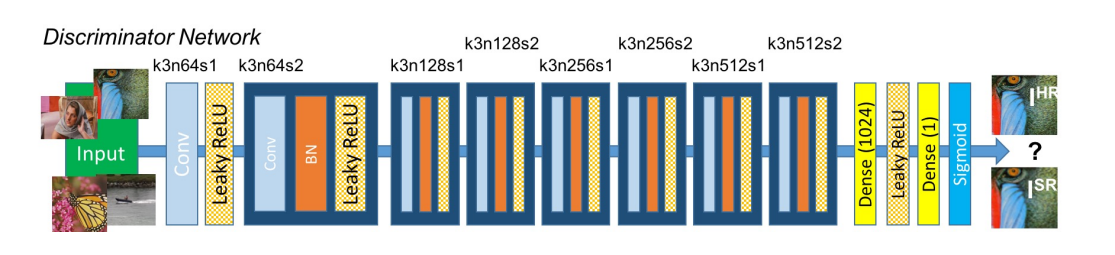
# 그림의 파란색 블록을 정의합니다.
def disc_base_block(x, n_filters=128):
out = layers.Conv2D(n_filters, 3, 1, "same")(x)
out = layers.BatchNormalization()(out)
out = layers.LeakyReLU()(out)
out = layers.Conv2D(n_filters, 3, 2, "same")(out)
out = layers.BatchNormalization()(out)
return layers.LeakyReLU()(out)
# 전체 Discriminator 정의합니다.
def get_discriminator(input_shape=(None, None, 3)):
inputs = Input(input_shape)
out = layers.Conv2D(n_filters, 3, 1, "same")(inputs)
out = layers.LeakyReLU()(out)
out = layers.Conv2D(64, 3, 2, "same")(out)
out = layers.BatchNormalization()(out)
out = layers.LeakyReLU()(out)
for n_filters in [128, 256, 512]:
out = disc_base_block(out, n_filters)
out = layers.Dense(1024)(out)
out = layers.LeakyReLU()(out)
out = layers.Dense(1, activation="sigmoid")(out)
return Model(inputs, out)SRGAN은 VGG19으로 content loss를 계산합니다. Tensorflow는 이미지넷 데이터로부터 잘 학습된 VGG19를 제공하고 있습니다. 이걸 활용해보겠습니다!
from tensorflow.python.keras import applications
def get_feature_extractor(input_shape=(None, None, 3)):
vgg = applications.vgg19.VGG19(
include_top = False,
weights = "imagenet",
input_shape=input_shape
)
# 아래 vgg.layers[20]은 vgg 내의 마지막 conv layer입니다.
return Model(vgg.input, vgg.layers[20].output)3. SRGAN 학습하기
이제 앞에 함수로 정의해둔 신경망을 활용하여 SRGAN을 학습해 보겠습니다. 200번의 epoch만 학습하겠습니다. 10번 마다 한 번씩 loss를 출력하도록 하였습니다.
from tensorflow.keras import losses, metrics, optimizers
generator = get_generator()
discriminator = get_discriminator()
vgg = get_feature_extractor()
# 사용할 loss function 및 optimizer를 정의합니다.
bce = losses.BinaryCrossentropy(from_logits=False)
mse = losses.MeanSquareError()
gene_opt = optimizers.Adam()
disc_opt = optimizers.Adam()
def get_gene_loss(fake_out):
return bce(tf.ones_lie(real_out), real_out) + bce(tf.zeros_like(fake_out), fake_out)
@tf.function
def get_content_losS(hr_real, hr_fake):
hr_real = applications.vgg19.preprocess_input(hr_real)
hr_fake = applications.vgg19.preprocess_input(hr_fake)
hr_real_feature = vgg(hr_real) / 12.75
hr_fake_feature = vgg(hr_fake) / 12.75
return mse(hr_real_feature, hr_fake_feature)
@tf.function
def step(lr, hr_real):
with tf.GradientTape() as gene_tape, tf.GradientTape() as disc_tape:
hr_fake = generator(lr, training=True)
real_out = discriminator(hr_real, training=True)
fake_out = discriminator(hr_fake, training=True)
perceptual_loss = get_content_losS(hr_real, hr_fake) + 1e-3 * get_gene_loss(fake_out)
discriminator_loss = get_disc_loss(real_out, fake_out)
gene_opt.apply_gradients(zip(gene_gradient, generator.trainable_variables))
gene_opt.apply_gradients(zip(disc_gradient, discriminator.trainable_variables))
return perceptual_loss, discriminator_loss
gene_losses = metrics.Mean()
disc_losses = metrics.Mean()
for epoch in range(1, 2):
for i, (lr, hr) in enumerate(train):
g_loss, d_loss = step(lr, hr)
gene_losses.update_state(g_loss)
disc_losses.update_state(d_loss)
# 10회 반복마다 loss 출력하기
if (i+1) % 10 == 0:
print(f"EPOCH[{epoch}] - STEP[{i+1}] \nGenerator_loss:{gene_losses.result():.4f} \nDiscriminator_loss:{disc_losses.result():.4f}", end="\n\n")
if (i+1) == 200:
break
gene_losses.reset_states()
disc_losses.reset_states()
Downloading data from https://storage.googleapis.com/tensorflow/keras-applications/vgg19/vgg19_weights_tf_dim_ordering_tf_kernels_notop.h5
80142336/80134624 [==============================] - 0s 0us/step
EPOCH[1] - STEP[10]
Generator_loss:0.0011
Discriminator_loss:1.9552
EPOCH[1] - STEP[20]
Generator_loss:0.0010
Discriminator_loss:1.5159
EPOCH[1] - STEP[30]
Generator_loss:0.0013
Discriminator_loss:1.1870
EPOCH[1] - STEP[40]
Generator_loss:0.0018
Discriminator_loss:1.0092
EPOCH[1] - STEP[50]
Generator_loss:0.0021
Discriminator_loss:0.8299
EPOCH[1] - STEP[60]
Generator_loss:0.0025
Discriminator_loss:0.6961
EPOCH[1] - STEP[70]
Generator_loss:0.0028
Discriminator_loss:0.6042
EPOCH[1] - STEP[80]
Generator_loss:0.0032
Discriminator_loss:0.5358
EPOCH[1] - STEP[90]
Generator_loss:0.0034
Discriminator_loss:0.4802
EPOCH[1] - STEP[100]
Generator_loss:0.0036
Discriminator_loss:0.4339
EPOCH[1] - STEP[110]
Generator_loss:0.0039
Discriminator_loss:0.3957
EPOCH[1] - STEP[120]
Generator_loss:0.0041
Discriminator_loss:0.3633
EPOCH[1] - STEP[130]
Generator_loss:0.0043
Discriminator_loss:0.3357
EPOCH[1] - STEP[140]
Generator_loss:0.0045
Discriminator_loss:0.3121
EPOCH[1] - STEP[150]
Generator_loss:0.0047
Discriminator_loss:0.2914
EPOCH[1] - STEP[160]
Generator_loss:0.0048
Discriminator_loss:0.2733
EPOCH[1] - STEP[170]
Generator_loss:0.0050
Discriminator_loss:0.2574
EPOCH[1] - STEP[180]
Generator_loss:0.0052
Discriminator_loss:0.2431
EPOCH[1] - STEP[190]
Generator_loss:0.0053
Discriminator_loss:0.2304
EPOCH[1] - STEP[200]
Generator_loss:0.0055
Discriminator_loss:0.21894. SRGAN 테스트하기
SRGAN이 만족스러운 결과를 도출할 때까지는 상당히 많은 학습 시간을 요구한다고 합니다.
그래서 현재 실습 과정에서는 이미 학습이 완료된 SRGAN을 준비해두었다고 하네요! 이걸 이용해서 test 하러 갑니다.
SRGAN은 크게 두 개의 신경망(Generator, Discriminator)으로 구성되어 있습니다.
그러나 테스트에서는 Generator만 이용합니다. Generator는 저해상도 입력을 넣어 고해상도 이미지를 출력하는 역할을 합니다.
테스트 과정을 진행하는 함수 정의 뒤에 이 함수를 이용해 이전에 사용했던 이미지에 대한 SRGAN 고해상도 결과값을 생성해보겠습니다.
import numpy as np
def apply_srgan(image):
image = tf.cast(image[np.newaxis, ...], tf.float32)
sr = srgan.predict(image)
sr = tf.clip_by_value(sr, o, 255)
sr = tf.round(sr)
sr = tf.cast(sr, tf.unit8)
return np.array(sr)[0]
train, valid = tfds.load(
"div2k/bicubic_x4",
split=["train", "validation"],
as_supervised=True
)
for i, (lr, hr) in enumerate(valid):
if i == 6: break
srgan_hr = apply_srgan(lr)이미지 전체를 시각화 했을 때 세부적인 것은 확인하기 어렵습니다. 앞서 했던 것처럼 일부 영역만 잘라서 비교를 해보겠습니다!
아래 코드를 이용해서 이때까지 배운 3개의 이미지를 비교해 보겠습니다.
bicubic interpolation vs SRGAN vs Origian❗
# 자세히 시각화하기 위해 3개 영역을 잘라냅니다.
# 아래는 잘라낸 부분의 좌상단 좌표 3개의 값입니다.
left_tops = [(400,500), (300,1200), (0,1000)]
images = []
for left_top in left_tops:
img1 = crop(bicubic_hr, left_top, 200, 200)
img2 = crop(srgan_hr, left_top, 200, 200)
img3 = crop(hr, left_top, 200, 200)
images.extend([img1, img2, img3])
labels = ["Bicubic", "SRGAN", "HR"] * 3
plt.figure(figsize=(18,18))
for i in range(9):
plt.subplot(3,3,i+1)
plt.imshow(images[i])
plt.title(labels[i], fontsize=30)
어떤가요? 제 눈에는 bicubic interpolation 보다 SRGAN의 해상도가 훨씬 좋다는 것이 느껴지고, 원본보다는 아쉽지만 좋은 결과를 보여준 것 같습니다!
SRGAN은 이전에 사용했던 SRCNN보다 더 깊은 Conv layer를 사용하고, GAN과 VGG 구조를 이용한 손실함수를 사용하여 복잡하게 학습 과정을 구성했다는 점! 잊지맙시다... (코드 다 치면서 힘들었...🤣)
논문

논문에서도 SRGAN을 구현하여 비교합니다. SRResNet은 SRGAN의 Generator를 의미합니다. Generator 구조만 이용해 SRCNN과 비슷하게 MSE 손실함수로 학습한 결과인데요.
오른쪽으로 갈수록 GAN 및 VGG 구조를 이용하여 점점 더 이미지가 선명해짐을 느낄 수 있습니다.
다음엔 Super Resolution 결과를 평가하는 방법에 대해 알아보겠습니다!
그리고 SRCNN, SRGAN의 정량적 평가 결과를 비교해봅시다! 👏

수연님 마지막 이미지 시각화 코드가 활성화되지 않습니다... 혹시 도움 좀 주실수 있으실까요??