안녕하세요. GAN. 다시 만나서 반갑습니다. 솔직히 이렇게 빨리 다시 만날 줄 몰랐습니다.
이번엔 GAN을 활용한 Super Resolution 과정에 대해 다뤄보려 합니다. 고해상도 이미지를 만들어 내는데 GAN이 어떻게 활용이 될까요? 어떤 과정일지 상상이 가시나요?
다시 한 번, GAN
GAN은 Generative adversarial network의 줄임말입니다. 비지도학습 GAN은 원 데이터가 가지고 있는 확률분포를 추정하도록 하고, 인공신경망이 그 분포를 만들어 낼 수 있도록 한다는 점에서 단순한 군집화 기반의 비지도학습과 차이가 있습니다.
SRGAN을 학습하기 위해선 GAN을 안다는 전제하에 진행한다고 합니다. 이전에 GAN에 관련하여 정리한 자료가 있습니다. 참고하시길 바랍니다.
SRGAN = Super Resoultion + GAN
최근 SR 분야에서 GAN은 많이 활용되고 있습니다. 가장 처음으로 SR에 GAN을 이용한 연구인 SRGAN에 대해 알아보겠습니다.
SRGAN은 2016년 발표된 "Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network" 논문에서 제안되었습니다.
SRCNN보다 더 복잡한 구조를 갖습니다.
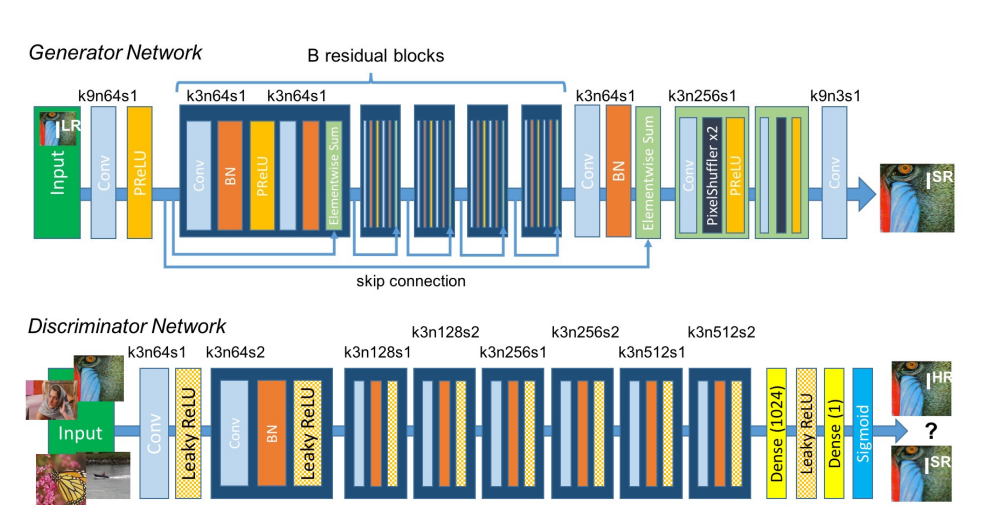
Generator Network(생성모델), Discriminator Network(판별모델) 구조를 보여주고 있습니다.
네트워크를 간략하게 이해해봅시다. Generator가 저해상도 이미지를 입력 받아서 가짜 고해상도 이미지를 만들어내면, Discriminator은 생성된 가짜 고해상도 이미지와 실제 고해상도 이미지 중 진짜를 판별합니다.
Generator와 Discriminator은 진짜를 가려내려는 학습이 진행될 수록 서로 경쟁자가 되어 둘 모두 함께 발전합니다.
학습이 거의 완료될 즈음 최종적으로 Generator가 생성해낸 가짜 고해상도 이미지는 Discriminator가 진짜인지 가짜인지 구분하기 힘들 정도로 좋은 품질을 가진 고해상도 이미지가 됩니다.
SRGAN의 loss Function
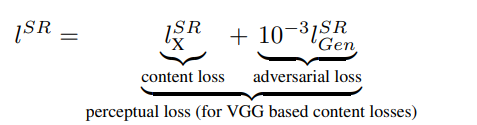
SR loss 값은 content loss와 adversarial loss로 구성되어 있습니다. 이중 adversarial loss는 우리가 일반적으로 알고 있는 GAN의 loss입니다. 조금 특별한 부분은 content loss입니다.
content loss를 더 살펴보겠습니다.
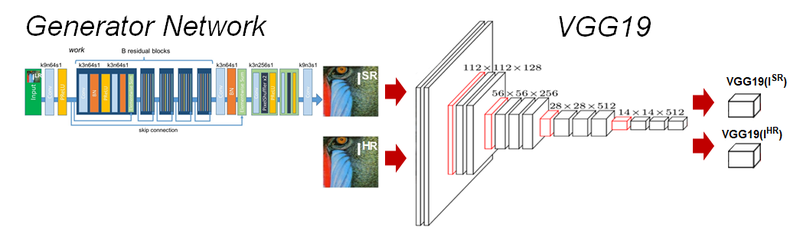
content loss는 Generator을 이용해 얻어낸 가짜 고해상도 이미지를 진짜 고해상도 이미지와 직접 비교하는 것이 아니라,
각 이미지를 이미지넷으로 사전 학습된(pre-trained) VGG 모델에 입력하여 나오는 feature map에서의 차이를 계산합니다.
즉, 이전에 학습한 SRCNN은 생성해낸 고해상도 이미지를 원래 고해상도 이미지와 직접 비교를 통해 loss를 계산했었습니다.
하지만 SRGAN에서는 생성된 고해상도 이미지와 실제 고해상도 이미지를 VGG에 입력하여 모델 중간에서 추출해낸 특징을 비교해서 loss를 계산합니다.
SRGAN은 VGG를 이용해서 content loss 및 GAN을 사용함으로써 발생하는 adversarial loss를 합하여 최종적으로 perceptual loss라고 정의하여 이를 학습에 적용 시킵니다..
SRGAN은 왜 그렇게 복잡한 손실함수를 선택했을까요?
일단 CNN 알고리즘을 크게 한 번 훑은 적은 있지만 VGG특징이 잘 기억이 안 나서 VGG를 공부하고 가면 좋을 듯 합니다.
VGG 다시 재공부🤣
다음엔 SRGAN을 구현해보겠습니다!
