앞서 Fashion MNIST Dataset에 대한 소개를 하였습니다.
이제 이 데이터셋을 텐서플로우 기반으로 활용해 보겠습니다. 데이터를 Load하고 활용하기 위한 package와 module 등을 불러오겠습니다.
라이브러리 설치
# 설치 여부 확인
$ pip list | grep -E 'imageio|Pillow'설치가 안 되어 있다면 설치. 설치는 이제 익숙하죠. 핍인스톨😝
$ pip install imageio
$ pip install Pillow그리고 각자 필요한 작업 환경을 구성해주세요! 디렉토리 생성은 make directory의 약자 'mkdir -p ~ ' 입니다. -p는 상위 경로도 생성해준다는 의미입니다. 여러 가지 약자가 있는데 -v는 디렉토리 생성 후 확인할 때 쓰는 약자이며 -m은 mode의 약자, 권한 설정이라 합니다.
필요한 모듈
뭐가 굉장히 많은데요.
import os
import glob # glob는 파일들의 리스트를 뽑을 때 사용, 파일의 경로명을 활용할 때 사용
import time
import PIL
import imageio
import numpy as np
import tensorflow as tf
from tensorflow.keras import layers
from IPython import display
import matplotlib.pyplot as plt
%matplotlib inline
print("tensorflow", tf.__version__)MNIST 데이터셋은 직접 다운로드 할 필요 없이 tf.keras 안에 있는 datasets에서 꺼내오겠습니다.
이때 사용하는 것이 load_data()이며, 특히 이번에는 분류 문제와 달리 이미지가 어떤 카테고리인지 나타내주는 라벨이 필요 없습니다, 즉, 우리가 MNIST 데이터로 분류 문제를 풀었을 때 필요한 y_train, y_test에 해당하는 데이터를 쓰지 않습니다.
그렇다면 필요 없는 데이터를 가져오지 않는 방법은 무엇이 있을까요?
저는 사실 '_' 이 언더 스코어 기능을 잘못 알고 있었던 것 같습니다. 그냥 써주는 거라 들었는데😢 해당 데이터를 무시한다는 의미가 될 수 있다고도 하네요. 찾아보니 다른 여러 가지 의미가 있습니다. 갑분파이썬
❗ 언더 스코어
Data Load
fashion_mnist = tf.keras.datasets.fashion_mnist
(train_x, _), (test_x, _) = fashion_mnist.load_data()이미지 정규화
Fashion MNIST는 Image Dataset이며, 28x28px의 이미지라는 것을 알고 있습니다. 이미지 픽셀은 0~255 사이의 정숫값을 가집니다.
>>> print("max pixel:", train_x.max())
>>> print("max pixel:", train_x.min())
max pixel: 255
min pixel: 0min, max 값이 잘 출력 되었습니다. 이미지를 한 번이라도 다뤄본 분이 계시다면 정규화를 해 본 경험이 있을것입니다. 이미지를 정규화시키면 픽셀의 값이 0~1까지의 값을 갖게 됩니다.
여기서는 -1, 1 사이의 값을 갖고 중간값이 0이 되도록 맞춰주기 위해 127.5를 뺀 후 127.5로 나눠주는 작업을 하고 있습니다.
👉 이해가 안 되신다면? 0~255 픽셀 값을 가지는 이미지에 255를 나누면 최소 0(0 나누기 255) 부터 최대 1(255 나누기 255) 값을 가지게 되는데요. 여기서는 [-1, 1] 의 값을 만들어주고 싶다고 했으니, 255의 반값인 127.5를 빼고 127.5를 나눠준다고 합니다. 그러면 만약 0 픽셀 값을 가진 이미지라면 (0-127.5)/127.5 = -1 이 되는 것입니다.
코드로 살펴보겠습니다.
>>> train_X = (train_x - 127.5) / 127.5
>>> print("max pixel:", train_x.max())
>>> print("max pixel:", train_x.min())
max pixel: 1.0
min pixel: -1.0Data의 shape을 보고 가겠습니다.
>>> train_x.shape
(60000, 28, 28)한 가지 추가해야 할 점이 있다고 합니다.
channel 추가
>>> train_x = train_x.reshape(train_x.shape[0], 28, 28, 1).astype('float32')
>>> train_x.shape
(60000, 28, 28, 1)뒤에 1이 더 붙었습니다. 이것은 채널을 의미합니다. CNN 계층에서도 채널에 대해 배운 적이 있습니다. 딥러닝에서 이미지를 다루려면 채널 수에 대한 차원이 필요합니다. 이는 어떤 이미지이냐에따라 달라집니다.
RGB 는 많이 들어보셨죠? 포토샵이나 ppt할 때 이미지 픽셀 값을 입력해주어 색상을 지정해주었습니다. 이건 3개의 채널이 있다고 하고 채널 수가 3으로 입력됩니다. Gray Scale은 흑백 이미지로 1개의 채널만 필요하빈다. 이 이미지는 흑백 이미지입니다. 그래서 채널 값은 1입니다.
데이터 확인
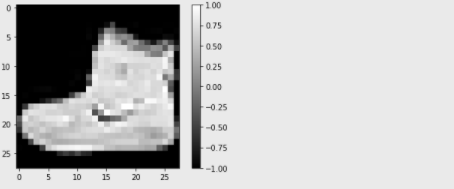
>>> plt.imshow(train_x[0].reshape(28, 28), cmap='gray')
>>> plt.colorbar()
>>> plt.show()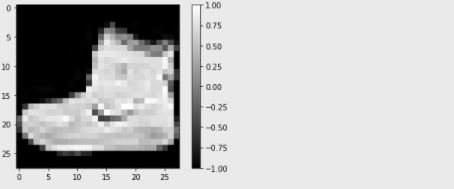
첫 번째 인덱스(train_x[0])는 신발이었습니다. 대충 봤는데도 왠지 나이키 신발 같은데요? 갠적으로 나이키 신발 별로...🙄
plt.colorbar()를 이용해 각 픽셀의 값과 그에 따른 색도 확인해 보겠습니다. 픽셀에는 아까 지정한대로 -1~1까지의 값을 가지는 걸 보이시나요? 어두울 수록 -1, 밝을 수록 1이네요.
for문을 통해 여러 장의 이미지를 출력하겠습니다.
>>> plt.figure(figsize=(10,5))
>>> for i in range(10):
plt.subplot(2, 5, i+1)
plt.imshow(train_x[i].reshape(28,28), cmap='gray')
plt.title(f'index: {i}')
plt.axis('off')
plt.show()
- plt.figure(figsize=(10,5))는 이미지의 전체 프레임 크기를 결정합니다. 행과 열이라 생각하면 되고 더 키워주고 싶으면 숫자를 키우면 됩니다. 하지만 28x28이미지니 그 픽셀 값보다 더 크게하면... 상당히 많이 깨지겠죠?
- plt.subplot(2,5,index)는 10개의 이미지를 2x5 형태로 해당하는 index만큼 보고 싶다는 말입니다.
- plt.title('title') 함수를 이용해서 제목을 지정할 수 있습니다.
- plt.axis('off') 함수로 불필요한 축을 지울 수 있습니다.
Q11. for 문을 활용해서 이미지 25개를 5x5 의 배열로 띄워보세요. 단, 모든 이미지는 train_images에서 랜덤으로 추출해 보세요. (힌트 : numpy에서 랜덤으로 정수를 추출해주는 함수를 찾아보세요!)
plt.figure(figsize=(10, 12))
for i in range(25):
plt.subplot(5, 5, i+1)
random_index = np.random.randint(1, 60000)
plt.imshow(train_X[random_index].reshape(28,28), cmap='gray')
plt.title(f'index: {random_index}')
plt.axis('off')
plt.show()
해당 코드는 random_index를 지정해주었기 때문에 실행할 때마다 다른 이미지가 나타납니다.😊
이제 데이터를 기본적으로 불러오고 확인하는 과정까지 마쳤습니다. 정규화까지 했으니 이미지 데이터에 대한 전처리까지 마친 셈입니다. 이렇게 정리된 이미지는 모델에 넣어 학습시켜야 하니 텐서플로우의 Dataset을 이용해 준비하도록 하겠습니다.
BUFFER_SIZE, BATCH_SIZE
BUFFER_SIZE = 60000
BATCH_SIZE = 256BUFFER_SIZE는 전체 데이터를 섞기 위해 60,000으로 설정하고 shuffle() 함수가 데이터셋을 잘 섞어서 모델에 넣어주는 역할을 합니다.
BATCH_SIZE는 모델이 한 번에 학습할 데이터의 양입니다. 너무 많으면 메모리 활용에 비효율적이고 오래 걸린다는 단점이 있습니다. 그래서 적절한 크기로 잘라 학습하도록 도와주는 것이 미니배치 학습입니다.
train_dataset = tf.data.Dataset.from_tensor_slices(train_x).shuffel(BUFFER_SIZE).batch(BATCH_SIZE)tf.data.Dataset 모듈의 from_tensor_slices() 함수를 사용하면 리스트, 넘파이, 또는 텐서플로우의 텐서 자료형에서 데이터셋을 만들 수 있습니다. 위 코드는 train_x라는 넘파이 배열(numpy ndarray)형 자료를 섞고, 이를 배치 사이즈에 따라 나누도록 합니다. 데이터가 잘 섞이게 하기 위해서는 버퍼 사이즈를 총 데이터 사이즈와 같거나 크게 설정하는 것이 좋습니다.
