강화학습(reinforcement learning) - 원리와 성질, 계산 모형, state, action, reward, Markov Decision Process
Machine Learning
cs231n 마지막 강의 Lecture14를 준비하면서 대망의 Deep Reinforcement Learning 파트를 공부하게 되었습니다.(15,16강은 특강이라 pass) 강화학습은 뭐랄까... 저한테 늘 최종 보스 같은 느낌이었는데요. 어쩌다보니 발표도 맡게 되었습니다. 강의를 두 번 정도 돌려보며 머리를 치다가 그냥 책을 펼쳤습니다.
이 책은 사놓고 두껍고 거부감이 들어 모셔만 놓다가 이번에 머신러닝 개념을 정리하기 시작하면서 다시 보고 있습니다. 알고리즘과 수식 위주의 책이긴 하지만, 내용은 좋습니다. 대신 영어판으로 구입하는 걸 추천 드립니다. 모든 용어를 한국어로 번역 해놓아서 혼란스럽습니다.

Preview

[그림 9-1]을 보면 아이가 걸음마를 배우는 과정이 있고 이를 기계에 적용하여 로봇이 안정적으로 걷기를 배우는 과정을 보여준다. 위 사례에서 강화 학습(reinforcement learning)이 과업을 달성하는데 사용된다.
그림을 자세히 관찰하면 로봇은 매 순간 어떤 '상태'에 있고, 어떤 '행동'한다. 로봇이 울퉁불퉁한 산길을 걷다가 자세가 불안정하면 안정적인 상태가 되도록 반작용 행동을 한다. 이렇게 로봇은 외부 환경과 상호작용하여 상태 변화와 행동을 번갈아 수행한다.
이전에 학습한 supervised learning과 unsupervised learning은 이 상황에 적용할 수 있을까?
supervised learning은 feature vector와 label로 구성된 train set이 있어야 하는데, [그림9-1]은 딱히 그런 부분이 없습니다. unsupervised learning은 clustering, Density Estimation, 공간 변환을 수행하므로 적용할 수 없다.
강화학습(reinforcement learning)은 외부 환경과 상호작용하면서 목표를 달성하는 목표 지향적 기계 학습 방법이다.
강화 학습 원리와 성질
강화 학습의 기초 개념과 더불어 사용하는 중요한 용어인 상태(state)와 행동(action)이 있었다. 강화 학습은 상태 변화와 행동을 번갈아 가면서 목표를 달성하려 노력한다.
1. 계산 모형
상태(state), 행동(action), 보상(reward)
상태 변화와 행동만으로 아이의 걷기 학습 과정을 설명할 수 없다. 여기에 보상(reward) 개념이 추가된다.
강화 학습은 시간에 따라 state, action, reward를 순차적으로 처리한다.
t=0, 1, 2, 3, …, T
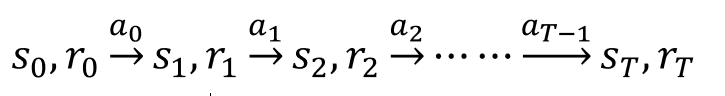
t는 시간을 나타내는 변수라서 연속일 수 있지만 보통은 이산값을 사용한다. s는 state이다. s0이 시작 상태가 된다. 이 상태에선 아무 일도 벌어나지 않으므로 reward의 r0은 0으로 설정한다. 여기서 행동 a0을 취하면 s1로 변하고 r1이 따라온다. 이러한 형식을 반복하다가 종료 상태에 도달한다. 마지막은 T로 표기한다.
이 내용을 수식으로 표현하면
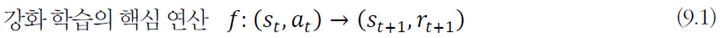
이와 같다.
그런데 중간에 취해줘야 할 reward의 책정이 불가능한 경우가 많다. [그림9-1]에서도 r1, r2, r3, r4의 보상액을 알 수 없다.
그래서 중간에는 reward를 0으로 설정하고 마지막 순간에 reward를 결정한다. 아기가 마지막에 아빠한테 걸어가면 1이라는 보상을, 실패하면 -1이라는 보상을 준다.
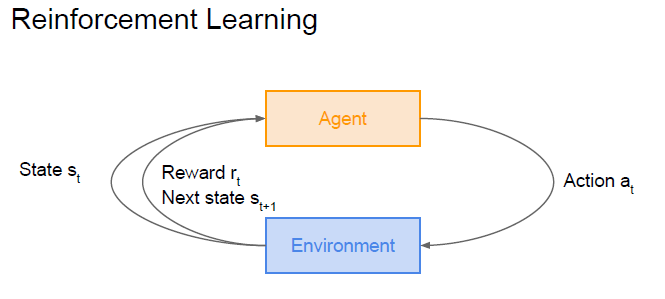
cs231에서도 이를 그림으로 잘 표현하였다. (cs231n Lecture14 Slide)
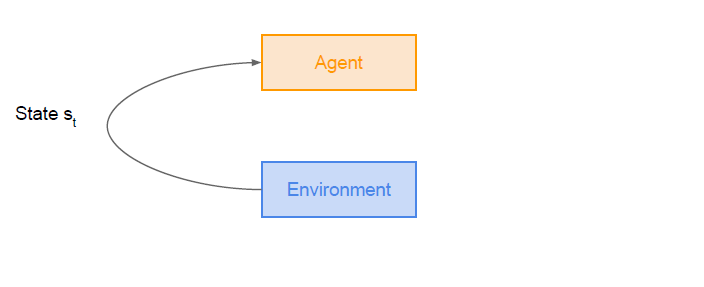
- Agent와 Environment가 있다.
- agent는 행동을 결정
- environment는 state 전환과 reward 결정
- MDP(Markov decision precess)는 문제를 정의할 때 따라 주어지는 정보. environment가 MDP에 따라 netxt state와 reward를 결정한다.
- State s_t (state 전환)
- Action a_t (action을 취함)
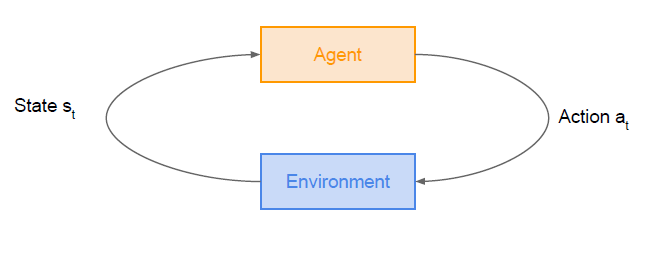
- reward r_t 결정

- Next state s_t+1(다음 state 전환)

그림을 순서대로 보면 어느 정도 이 과정이 이해될 것이다. environment는 MDP를 갖고 state 전환과 reward를 결정한다.
강화 학습의 목표는 '누적' reward를 최대화하는 것이다.
책에서는 이를 위의 [그림9-1]로 설명을 하고 있는데,
- 아이가 안정적으로 걸으면 1
- 아이가 불안정하게 걸으면 -1 (혹독한 사회다)
- 아빠에게 안기면 500
- 아빠에게 안기려다 넘어지면 -500 (혹독한 사회다2)
으로 보상을 주는 것이다. 500이라는 reward을 위해 -1이라는 reward를 감수하게 하는 것이다. 이처럼 순간적인 이익 보다는 '누적 reward'를 목표로 두고 있는 것이 강화 학습의 목표이다.
이는 supervised learning이 목적함수의 최적점을 찾아가는 방식과 비슷하다. 하지만 지도 학습은 목적함수를 미리 정해야 하고 train set에 따라 최적점을 찾아가지만, reinforcement learning은 순간마다 보상이 주어지며 agent는 누적 reward가 최대가 되도록 매 순간 최적의 action을 결정해야 한다.
순간 이득 최대화 ❌
긴 시간 동안의 누적 reward 최대화⭕
agent가 action을 선택하는 데 사용하는 규칙을 policy라고 하며, 강화 학습의 학습 알고리즘은 최적의 policy를 찾아야 한다!
state, action, reward의 표현
- 대부분 응용에서는 이산값을 가진다.
- state는 𝓈, action은 𝒶, reward는 𝓇로 표기
- state set 𝒮={𝓈1,𝓈_2,⋯,𝓈𝑛 }, action set 𝒜={𝒶1,𝒶_2,⋯,𝒶𝑚 }, reward set ℛ={𝓇1,𝓇_2,⋯,𝓇𝑙 }으로 표기
- 확률 변수와 확률 변수의 값 표기를 주의❗ 소문자 s, a, r은 확률변수, 𝓈, 𝒶, 𝓇은 확률 변수의 값이다.
- 예를 들어, 𝑃(𝑠(𝑡+1)=𝓈_58 |𝑠𝑡=𝓈_122)는 t 순간에 𝓈_122 상태에 있다가 다음 순간에 𝓈_58 상태로 바뀔 확률을 뜻한다.(t는 시간이다.)
- 또한, 𝑃(𝑠(𝑡+1)=𝓈_58 |𝑠𝑡=𝓈122,𝑎𝑡=𝒶_2)는 t 순간에 𝓈_122 상태에서 행동 𝒶_2를 취했을 때 𝓈_58 상태로 바뀔 확률을 의미한다.
예제 9-1


격자 세계라는 이 로봇의 동서남북 챌린지를 천천히 읽어보십시오! 그렇게 어렵지 않습니다.
- 로봇은 동서남북으로 이동 가능함
- 격자 세계 밖으로 나가면 reward -1
- 밖으로 안 나가고 이동하면 reward 0
- 종료 지점 1 or 16에 도착하면 reward 5
policy
[예제9-1]에서 agent가 방향을 결정했다(=action을 결정). environment는 그에 따라 state 변화를 결정하고 reward를 제공하였다. 이때 agent는 일정한 확률 규칙으로 action을 결정해야 하는데, 이 규칙을 policy라고 한다.

동, 서, 남, 북 네 방향을 동일 확률로 선택하는 policy를 선택했을 경우, 이를 수식으로 표현하면 위와 같다. 그렇다면 동일 확률을 사용하는 이 policy가 좋을까?
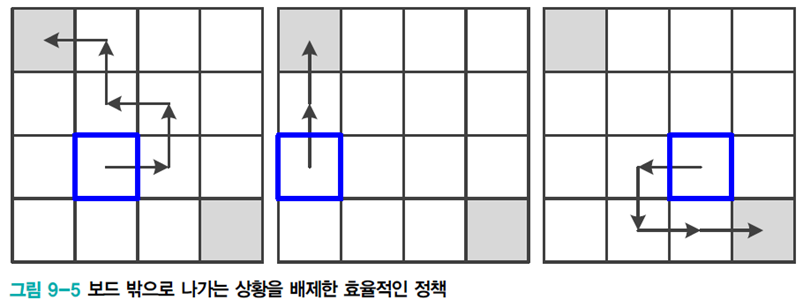
[그림9-5]를 살펴보니 이 policy가 매우 안 좋다는 것을 보여준다. 보드 밖으로 나가지 않으며 5라는 누적 reward를 받을 수 있도록 개선한 그림이다. 이를 수식으로 표현하면 아래와 같다.
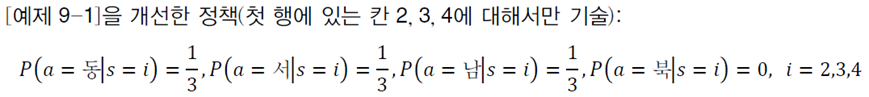
이 policy는 북으로 가는 확률을 0으로 부여하여 선택에서 배제시킨다. 나머지 동, 서, 남에는 1/3로 동일 확률을 부여한다.
2. exploration and exploitation
번역하면 탐험과 탐사라고 합니다. 하지만 이 용어는 전혀 쓰는 것 같지 않으니 영어 단어로 사용하겠습니다.
최적화 문제를 풀 떄는 때때로 exploration and exploitation conflict 현상이 발생한다. exploration 은 전체 공간을 골고루 찾아보는 전략이고, exploitation은 특정한 곳 주위를 집중적으로 찾아보는 전략이다. 예를 들어, gradient descent은 exploitation 알고리즘이다.
exploration은 너무 오래 걸리는 문제가 있고, exploitation은 다른 곳에 있는 더 좋은 해를 놓쳐 local optima에 머무는 문제가 있다.
기계 학습 알고리즘 대부분은 gradient descent과 gradient descent의 변형에 기초한다. 따라서 지금까지
exploitation 위주의 알고리즘을 사용했고, global optima와 비슷한 성능이 입증되었으니 걱정할 필요는 없다.
하지만 강화 학습에서는 exploitation으로 치우치면 열등한 해를 얻는 상황이 발생할 가능성이 크므로 주의해야 한다.

예로 k-손잡이 밴딧 문제가 있다. 카지노에서 슬롯머신 k개를 가지고 게임하는 상황이다. 손잡이를 당기면 0 또는 잭팟이라는 reward 두 가지가 있다고 하자. [그림9- 6]의 위 숫자는 잭팟이 터질 확률이고 플레이어는 이 확률을 당연히 모른다.
처음에 exploration 방식으로 게임을 하다가 12번 만에 잭팟이 터졌다.
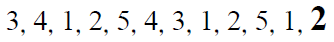
이 상황에서 극단적인 방식을 예시하면 다음과 같다.
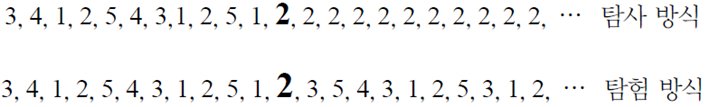
exploitation 2번 기계에서 잭팟이 터졌으니 또 터질 가능성이 크다고 보고 계속 2번에서 시도하는 방식이다. 이렇게 하면 실제로 훨씬 더 유리한 4번 기계를 시도할 기회를 놓친다.
exploration은 2번 기계에서 잭팟이 터졌으니 또 터질 가능성이 높을 것이라는 정보를 완전히 무시하는 방식이다.
exploration, exploitation 둘 다 균형을 이루는 방식이라면 어떻게 시도하면 좋을까?
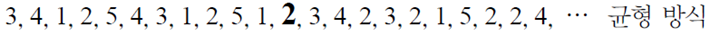
이 방식은 다른 기계에 비해 2번 기계를 더 자주 선택한다. 하지만 다른 기계에도 기회가 주어지긴 한다. 이후에 또 잭팟이 터지면 또 새로운 정보를 고려하여 확률 배분을 수정하고 시도한다.
여기에는 기회가 무한정으로 주어지는 경우, 주머니 사정이 어려워진 경우도 있다. 이 environment에 따라 또 다른 policy를 선택해야 한다.
강화 학습은 균형 방식을 사용한다.
Monte-Carlo 방법이나 temporal defference learning 에서도 균형 있게 sample을 조절한다.
3. Markov Decision Process
마르코프 결정 프로세스라 읽는다.
강화 학습에서 가장 중요한 연산은 어떤 state에서 가장 유리한 action을 선택하는 것이다.
여기서 Markov 성질은 행동을 결정할 때 이전 이력이 중요하지 않게 보는 것이다.
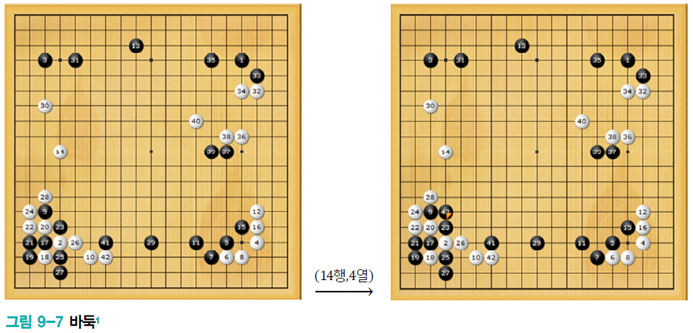
바둑을 둔다고 하여도 어떤 경로를 거쳐왔는지는 중요하지 않고, 현재 state만 보고 next action을 결정하는 것이다.
이 예시를 일반화하면, 현재 state에서 action을 결정할 때 이전 이력은 중요하지 않다.고 말할 수 있다. 그리고 어떤 과업이 이러한 조건을 만족하면 Markov property를 지녔다고 한다.
이 성질을 수식으로 표현하면
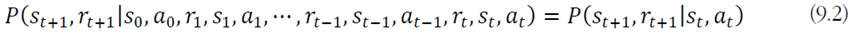
인데, 첨자를 생략해서 더 간단히 표현하면
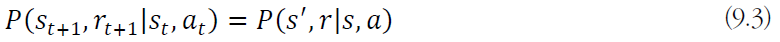
이다. 하지만 모든 문제가 Markov property를 만족하진 못한다.😥
예를 들어, 오늘 날씨에 따라 내일 행동을 결정하는 문제에서 오늘 날씨만 보는 것과 오늘, 어제, 그제 등의 날씨를 같이 고려하는 것은 정확도 차이가 클 것이다. 바둑도 이전에 둔 이력을 보면 상대의 수를 읽는데 도움이 된다.
강화 학습은 Markov property를 만족한다는 전제하에 동작한다. 따라서 Markov property을 근사하게라도 만족하는 문제에 국한하여 적용해야 한다.
Markov property을 만족하지 못하는 문제
- 크게 벗어나면 강화 학습 적용할 수 없음
- 근사하게 만족하도록 상태 표현 설계 가능
- 예, 날씨에 따른 행동 결정 문제에서는 이틀 날씨를 상태로 표현
- 예, 로켓 발사 제어 문제에서 위치 정보만 사용하는 대신 위치, 속도, 가속도 정보로 상태를 표현
MDP(Markov decision process)
Deterministic MDP
Stochastic MDP
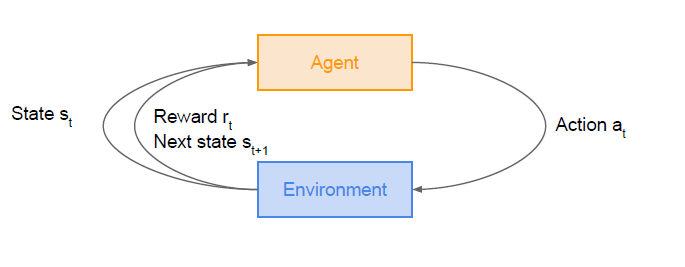
이 그림을 참고해보자.
agent는 현재 state에서 action을 선택한다. agent가 선택한 action을 취하면 environment는 새로운 state로 바꾸고 reward를 책정한다.
프로세스에서는 모든 state, action, reward 값이 발생할 수 있으므로 이를 확률분포로 정의해야 한다.
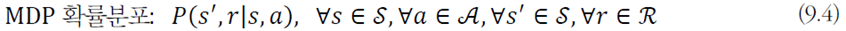
위 식을 MDP의 확률분포라고 한다. 이 확률 분포는 Markov property를 만족한다. 또한, environment가 process를 수행하는데 필요한 정보를 제공한다.
예로, [예제 9-1]의 경우 state 10에서 동쪽이라는 action을 취하면 next state는 11이고 reward는 0일 확률이 1이며 나머지는 모두 0이다. 이처럼 딱 한 가지 state와 reward가 있는 경우를 결정론적 MDP라 한다.
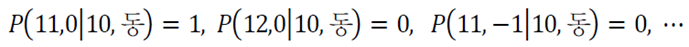
예외로, 가끔 돌풍이 불어 동쪽 행동을 취했는데 일정한 확률로 11이 아니라 7이나 15로도 갈 수 있는 경우가 있다. 이처럼 next state와 reward가 확률적으로 결정되는 경우를 stochastic MDP라고 한다.
강화 학습은 주어진 MDP에 따라 최적의 action을 결정해주는 policy를 찾아야 한다❗
