Text detection + Text recognition
이번엔 딥러닝을 이용해 이미지에서 텍스트의 위치를 찾는 Text Detection 방법에 대해 공부할 예정입니다.
Object Detection과 Segmentation을 위한 기법들이 떠오를 수 있습니다. Text는 몇 개가 모여서 단어 혹은 문장을 이루고 있어서 이미지 내에서 문자를 검출해낼 때엔 검출하기 위한 최소 단위를 생각해야 합니다.
예를 들어, 이미지 속에서 문장, 단어, 글자가 모두 단위가 될 수 있는 것이죠. 길이가 길어질 수도, 짧아질 수도 있습니다. 대신, 글자로 찾을 경우에는 이 글자들을 다시 맥락에 맞게 묶어주는 과정이 필요합니다.
[1]
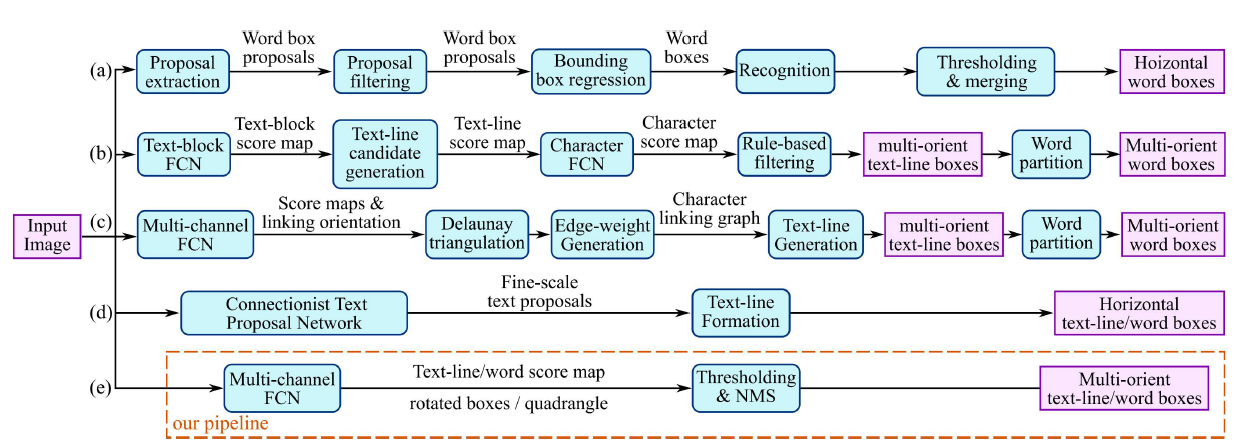
2017년 발표된 EAST: An Efficient and Accurate Scene Text Detector란 논문에서는 Text detection 기법을 정리했습니다.
Text의 Bounding Box를 구하는 방식 위주였는데, 그 이후로 Horizontal으로 Text Box를 구하거나, 기울기를 조절하거나 세로 방향의 Multi-oriented의 Text Box를 구하는 방식이 다양하게 소개되었습니다.
해당 논문에서 제시하는 (e)의 경우, 전체 파이프라인의 길이가 짧고 간결해서 빠르면서도 정확한 Text detection 성능을 보인다고 소개하고 있습니다.
위엔 단어 단위의 탐지와 글자 단위의 탐지가 모두 활용되고 있습니다.
단어 단위의 탐지는 앞서 배운 object detection의 Regression 기반의 Detection 방법입니다. Anchor를 정의하고 단어의 유무와 Bbox(Bounding Box)의 크기를 추정하여 단어를 찾아냅니다.
글자 단위의 방식은 Bbox regression을 사용하는 대신 글자 영역을 Segmentation하는 방법으로 접근합니다.
또한, 두 가지 방법을 모두 활용한 방법도 존재합니다.
이제 여러 가지 접근 방식을 대표적인 것들을 예를 들어 설명해보겠습니다.
1. Regression
[2]
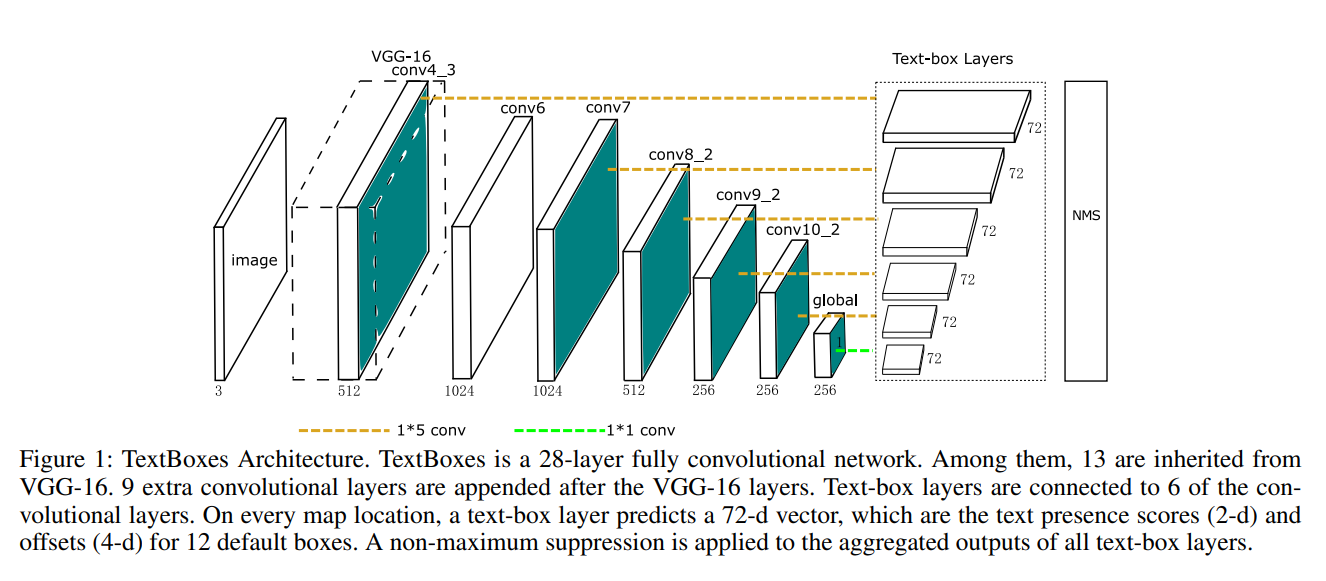
TextBoxes는 2017년 AAAI에 공개된 논문입니다.
TextBoxes 이전에는 글자 단위로 인식한 후 결합하는 방식을 선택했습니다. 위 논문은 딥러닝 기반의 Detection을 이용해 단어 단위로 인식합니다. 네트워크의 기본 구조는 SSD(Single Shot MultiBox Detector)를 이용했다고 합니다. 이를 통해 이전보다 더 빠르게 문자 영역을 탐지해냈습니다.
일반적으로 단어들은 가로로 길이가 더 깁니다. 그래서 Aspect ratio(종횡비)가 크기 때문에 몇 가지 변형을 주었습니다. 기존의 SSD는 Regression을 위한 Convolution layer에서 3x3 크기의 kernel을 갖습니다.
여기선 긴 단어의 Feature를 활용해야 해서 1x5 conv filter를 정의하여 사용합니다. Anchor box의 aspect ratio를 1, 2, 3, 5, 7로 만들고, vertical offset을 적용하여 세로 방향으로 촘촘한 단어의 배열에 대응할 수 있도록 했습니다.
종횡비(Aspect ratio)
- 가로, 세로 길이의 비. 가로세로비, 영상비, 화면비 등으로도 부름
- 일반적으로 16:9와 같이 '가로:세로'의 형태로 표현.
- 논문에서는 가로와 세로의 비를 계산하여 하나의 숫자로 표현하고 있음
offset
- Offset이란 특정한 값에서 차이가 나는 값 또는 차이를 의미
- 주의할 점은 offset과 오차가 다름
- offset은 차이가 목적에 의해 만들어진 것과 상황에 따라 자연스럽게 발생된 것을 모두 포함
[2]
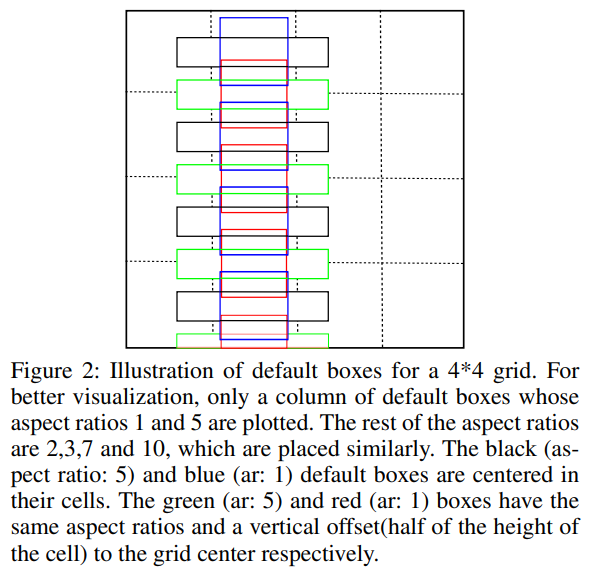
위에 설명한 1:5의 Aspect ratio를 가진 그림입니다. 나머지 2, 3, 7, 10은 비슷하게 배치됩니다.
- 검은색(aspect ritio:5)
- 파란색(aspect ratio:1)
- 초록색(aspect ratio:5)
- 빨간색(aspect ratio:1)
들은 동일한 aspect ratio 및 vertical offset을 각각 grid 중심에 맞게 이동합니다.
3x3 filter보다 1:5 conv filter가 더 큰 단어에 적합합니다. 정사각형 모양의 receptive filed는 noisy signal을 피합니다.
정리
Grid cell의 중앙을 기점으로 생성할 경우,
파란색(aspect ratio:1), 검은색(aspect ratio:5) 박스는 Grid cell의 중앙을 기점으로 생성되어 있습니다. 녹색(aspect ratio:5) 및 빨간색(aspect ratio:1) 상자는 가로 세로 비율이 동일하고, grid 중심에 대한 vertical offset이 각각 있습니다.
2. Segmentation
[3]
Semantic segmentation할 때 이미지 내의 영역을 class로 분리해내는 방법이었습니다. 이 방법을 문자 영역 찾기에 적용하면 배경과 글자인 영역으로 분리할 수 있습니다.
문자는 매우 작고 촘촘하 나열되어 있기 때문에 글자 영역으로 찾아낸 뒤, 이를 분리해내는 작업이나 연결하는 작업을 더해 원하는 최소 단위로 만들어줘야 합니다.
PixelLink는 Text 영역을 찾아내는 segmentation과 함께, 글자가 어느 방향으로 연결되는지를 같이 학습하여 Text 영역 간의 분리 및 연결을 할 수 있는 정보를 추가적으로 활용하고 있습니다.
[3]
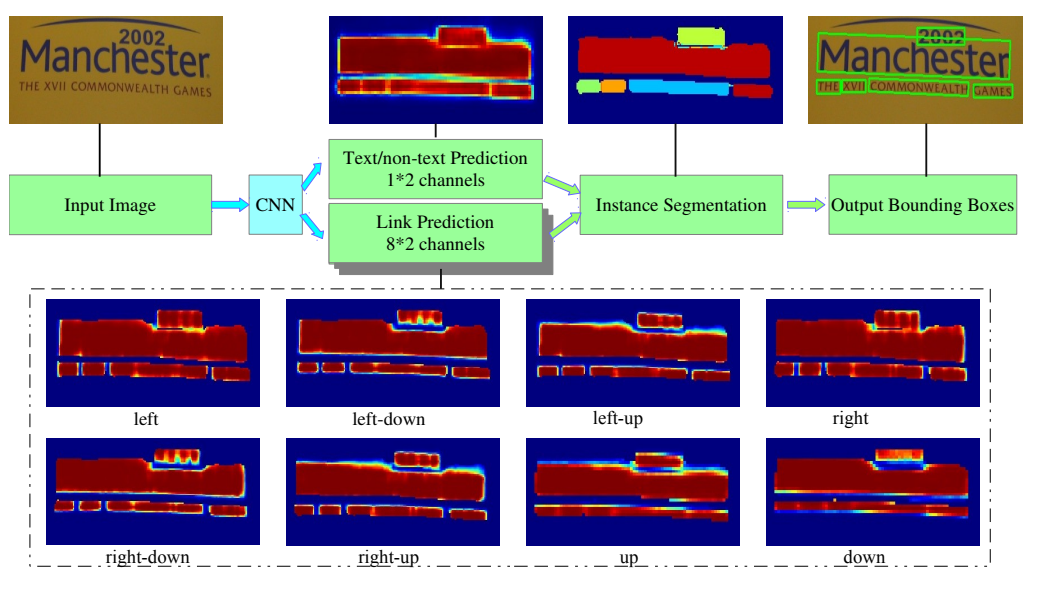
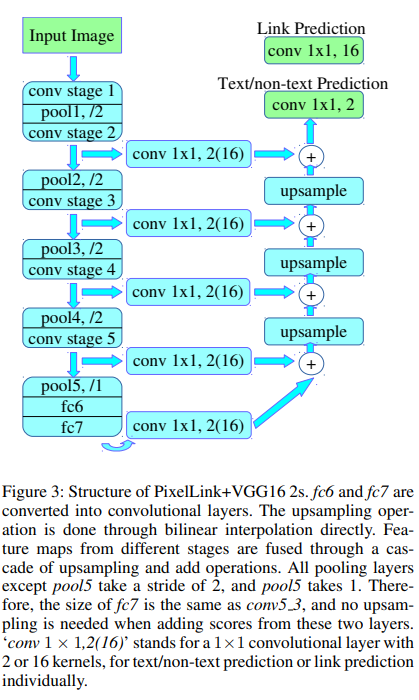
PixelLink의 전체적인 구조는 U-Net과 유사한데, output으로 총 9가지의 정보를 얻습니다.
녹색 박스가 input과 output을 의미하며, output으로 총 9개의 정보를 얻습니다.
output 중 하나는 Text/non-text prediction을 위한 class segmentation map으로 해당 영역이 Text인지 non-text인지 예측값을 의미하는 2개의 kernel을 가집니다.
나머지 8가지는 Link Predition map으로 글자의 Pixel을 중심으로 인접한 8개의 pixel에 대한 연결 여부를 의미하는 16개의 kernel로 이루어져 있습니다.
위 그림을 보면, conv 1x1, 2(16) layer가 U-Net 구조로 연결되어 인접한 pixel 간 연결 구조가 지속적으로 유지되도록 하는 모델 구조입니다.
이를 통해 인접해 있는 pixel이 중심 pixel과 단어 단위로 연결된 pixel인지, 아니면 분리된 pixel인지 알 수 있습니다. 그러므로 문자 영역이 단어 단위로 분리된 Instance segmentation이 가능해집니다!
3. 최근 방법
딥러닝이 빠르게 발전하는 만큼 새로운 방식이 계속해서 시도되고 있습니다.
위의 TextBoxes나 PixelLink는 2017년에 공개 된 논문이니 꽤 시간이 지났습니다. 요즘 문자 영역을 찾아내는 방식 몇 가지를 소개하겠습니다.
3.1. CRAFT
[4]
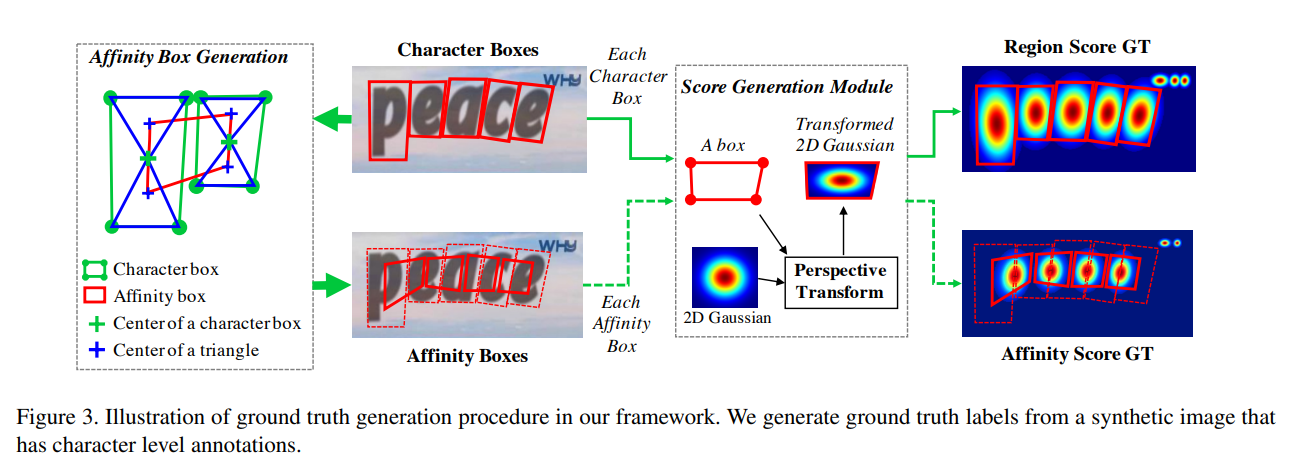
CRAFT는 문자(Character) 단위로 문자의 위치를 찾아낸냅니다. 찾아낸 뒤 이를 연결하는 방식을 Segmentation 기반으로 구현한 방법입니다.
문자의 영역을 boundary로 명확히 구분하지 않고, 가우시안 분포를 따르는 원형의 score map을 만들어서 배치시키는 방법으로 문자의 영역을 학습합니다.
문자 단위 라벨을 가진 데이터셋이 많지 않기 때문에, 단어 단위의 정보만 있는 데이터셋에 대해 단어의 영역에 Inference를 한 후, 얻어진 문자 단위의 위치를 다시 학습에 활용하는 Weakly supervised learning을 활용했습니다.
CRAFT는 기본적으로 CNN으로 디자인되어 있고, region score와 affinity score의 개념이 나옵니다.
region score는 이미지에 있는 각각의 글자들을 위치 시키는 데에 사용되며, affinity score는 각 글자들을 한 instance에 묶는데에 사용됩니다.
문자 수준의 annotation이 부족하기 때문에 CRAFT에서는 약한 정도의 supervised leargning frame work를 제안합니다.
일반적으로 사용하는 텍스트 이미지 데이터 셋에 글자 수준의 groud-truth 데이터가 없기 때문인데요. [4] 논문에서는 데이터 셋으로 ICDAR을 사용했고 그 외에 MSRATD500, CTW-1500 등을 통해 실험했습니다.
3.2. Pyramid Mask Text Detector

[5]
PMTD(Pyramid Mask Text Detector)는 Mask-RCNN의 구조를 활용하였습니다.
먼저 Text영역을 Region proposal network로 찾아냅니다. 그다음 Box head에서 더 정확하게 regression 및 classification을 하고, Mask head에서 Instance의 Segmentation을 하는 과정을 거칩니다.
PMTD는 Mask 정보가 부정확한 경우를 반영하기 위해서 Soft-segmentation을 활용합니다. 이전의 Mask-RCNN의 경우, 단어 영역이 Box head에 의해 빨간색으로 잡히면 위의 이미지의 baseline처럼 boundary를 모두 Text 영역으로 잡지만, PMTD는 단어의 사각형 배치 특성을 반영하여 피라미드 형태의 Score map을 활용합니다.
따라서 Pyramid 형상의 Mask를 갖게 되어 Pyramid Mask Text detector라는 이름이 붙었습니다.
Reference
1️⃣ EAST: An Efficient and Accurate Scene Text Detector
2️⃣ TextBoxes: A Fast Text Detector with a Single Deep Neural Network
3️⃣ PixelLink: Detecting Scene Text via Instance Segmentation
4️⃣ Character Region Awareness for Text Detection
5️⃣ Pyramid Mask Text Detector
