1. Unsegmented Data

[https://unsplash.com/photos/S20PlUJRviI]
글자 이미지들은 문자 순서대로 정보를 갖고 있습니다.
위의 이미지는 클립으로 'YOU'라 적혀 있는데요. 이미지에서 "Y", "O", "U"의 영역은 이미지상에서 분리가 가능합니다.
하지만 이와 다르게 분리에 드는 비용이 많이 들거나 어려워서 Segmentation이 되어있지 않은 데이터를 Unsegmented data라고 합니다.
이미지에서 문자를 읽어내는 OCR 분야뿐만 아니라 다른 분야들에서도 이런 데이터를 볼 수 있습니다.
예를 들어, 아래 그림과 같이 annotation이 제대로 안 된 음성데이터가 있다고 할 때, 이것도 Unsegmented data의 한 종류입니다.
Waveform 파일에 대한 라벨이 "the sound of"라고 달려 있다고 할 때, 해당 waveform 파일에서 어디까지가 각각 "the", "sound", "of"인지의 경계가 명확하게 분할되어 있지 않은 경우를 생각할 수 있습니다.
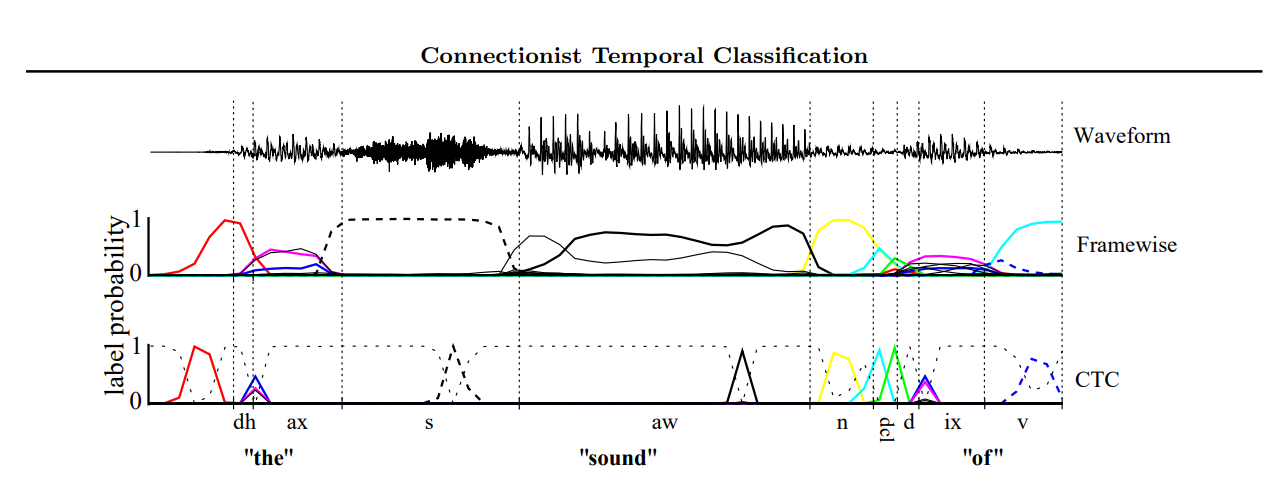
[1]
2. CNN과 RNN의 만남 CRNN
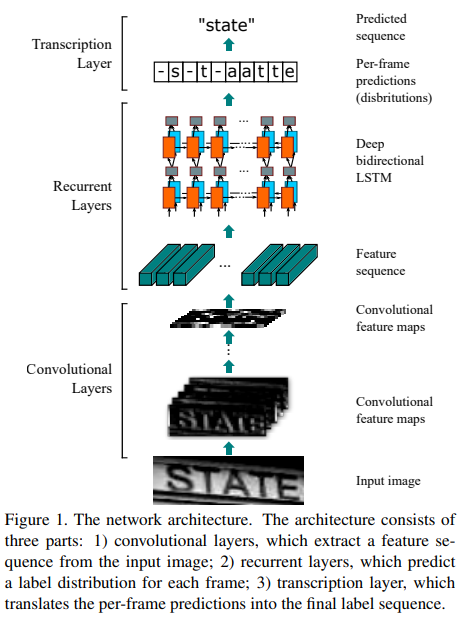
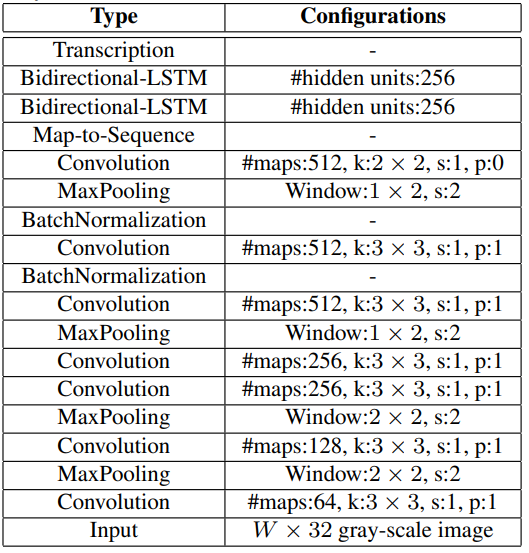
[2]
Unsegmented Data가 가진 주요 특징 중 하나는 segment 되어 있지 않은 하위 데이터들끼리 sequence를 이루고 있다는 점입니다.
그래서 연구자들이 생각해 낸 방법 중 하나로 CNN(Convolution neural network)와 RNN(Recurrent neural network)를 같이 쓰는 방법인데, 이런 모델을 CRNN이라고 합니다!
문자 이미지에서 정보를 추출하기 위해 Feature Extractor 기반의 Feature Extractor가 필요합니다. Feature Extractor 기반의 VGG 또는 ResNet과 같은 네트워크로부터 문자의 정보를 가진 Feature을 얻어낼 수 있습니다.
이렇게 추출된 Feature를 Map-to-Sequence를 통해 Sequence 형태의 feature로 변환합니다. 그 후 다양한 길이의 Input을 처리할 수 있는 RNN으로 넣습니다.
RNN이 Feature로부터 문자를 인식하기 위해 문자 영역처럼 넓은 정보가 필요해서 LSTM으로 구성합니다. 앞의 정보 뿐만 아니라 뒤의 정보도 필요하기 때문에 이를 Bidirectional로 구성해 Bidirectional LSTM을 사용했습니다. 각 step마다 나오는 결과는 Transcription Layer에서 문자로 변환됩니다.
3. CTC
CRNN은 Step마다 FC laye의 logit을 Softmax 함수에 넣어줌으로써 어떤 문자일 확률이 높은지를 알려줍니다.
하지만 결과 그대로 문자로 변환하면 기대한 것과 다른 결과가 나옵니다. 모델의 output은 24개의 글자로 이루어진 Sequence지만, 실제 결과는 이와 다르기 때문인데요.
예를 들어, "HELLO"라는 이미지가 들어오면 이것의 Output이 "HHHEEELLLOOOOO..."와 같이 24자의 sequence를 보게 됩니다.
이 24자의 Sequence를 실제 인식 결과로 바꾸기 위해서 CTC라는 개념이 나옵니다.
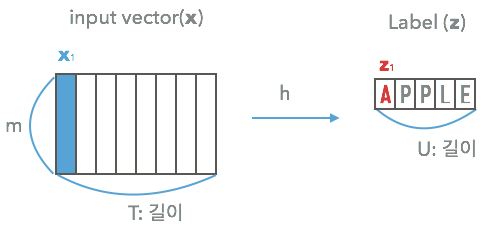
CRNN에서 Unsegmented Data를 위해 CTC(Connectionist Temporal Classification)를 활용합니다.
CTC는 Unsegmented data와 같이 Input과 Output이 서로 다른 Length의 Sequence를 가질 때, 이를 Align 없이 활용하는 방법입니다.
논문에서 언급하는 CTC의 핵심인 모델의 output에서 Label Sequence의 확률을 구할 수 있는 방법에 대해 알아보겠습니다.
아까 위에서 언급한 "HHHEEELLLOOOOO..."를 "HELLO"로 만들기 위해 중복되는 "H", "E", "L", "O"를 하나로 바꿔줘야 "HELO"가 될 것 같습니다.
그렇다면 "L"이 두 번 중복되는 경우를 구분해야 하는데요. 앞에서 봤던 Label Encode에서 이렇게 같은 문자를 구분하기 위한 Blank를 중복된 라벨 사이를 구분하기 위해 넣어줍니다.
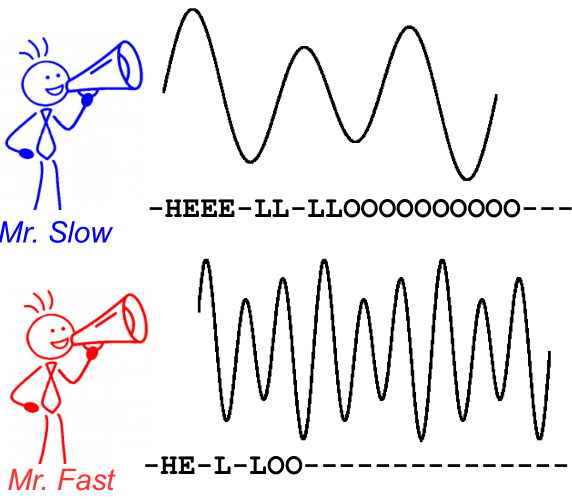
[https://stats.stackexchange.com/questions/320868/what-is-connectionist-temporal-classification-ctc]
위 그림을 통해 Blank를 위한 token을 '-'로 대신했음을 알 수 있습니다. 이 과정은 '-'이 Blank token을 대신해 output을 만드는 Decoder입니다. Decode 후에 중복을 제거하고, 인식할 문자가 아닌 값을 지워주면 "HELLO"라는 결과를 얻을 수 있습니다.
이렇게 인식된 Text의 정확도를 판별하기 위한 단위 중 실제 정답과 예측한 단어가 얼마나 가까운지 측정할 수 있는 방법으로는 Edit distance라는 방법이 있습니다.
한국어로는 편집 거리라고 하며 두 문자열 사이의 유사도를 판별하는 방법입니다. 예측된 단어에서 삽입, 삭제, 변경을 통해 얼마나 적은 횟수의 편집으로 정답에 도달할 수 있는지 최소 거리를 측정합니다.
4. TPS
TPS는 Thin Plate Spline Transformation을 적용하여 입력 이미지를 단어 영역에 맞게 변형 시켜 인식이 잘 되도록 해주는 기술입니다.
책이 아닌 거리의 글자를 읽을 때, 문자 영역을 찾아내는 것이 어려워지는 이유가 불규칙적인 방향 또는 휘어진 정도 때문인데요.
TPS는 control point를 정의하고 해당 point들이 특정 위치로 옮겨졌을 때, 축 방향의 변화를 interpolation하여 모든 위치의 변화를 추정해냅니다.
이를 통해서 전체 이미지 pixel의 변화를 control point로 만들어낼 수 있습니다.
논문에서는 Control point 20개를 미리 정의합니다.
Spatial Transformer Network를 통해서 Control point가 얼마나 움직여야 하는지, 예측하는 네트워크를 아래 그림과 같이 Recognition model 앞단에 붙여 입력 이미지를 정방향으로 맞춰줍니다.
TPS 연산은 미분 가능한 연산이기 때문에 이 모듈을 Recognition model 앞단에 붙여서 학습이 바로 가능합니다.
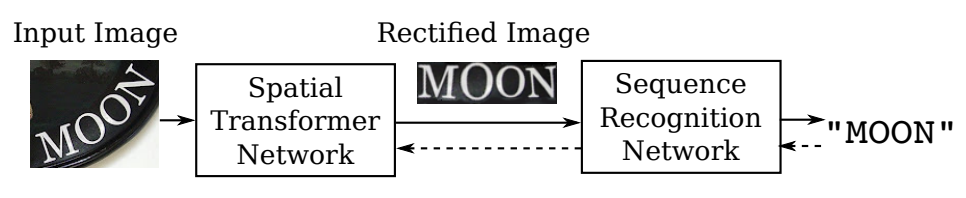
[3]
Spatial Transformer Networks이란 Input Image에 크기, 위치, 회전 등의 변환을 가해 추론을 더 용이하게 하는 transform matrix를 찾아 매핑해주는 네트워크를 말합니다.
References
1️⃣ Connectionist Temporal Classification: Labelling Unsegmented
Sequence Data with Recurrent Neural Networks
2️⃣ An End-to-End Trainable Neural Network for Image-based Sequence Recognition and Its Application to Scene Text Recognition
3️⃣ Robust Scene Text Recognition With Automatic Rectification
