Attention과 Transformer가 딥러닝 분야에 큰 변화를 가져왔습니다. OCR 분야에서도 적용이 되었습니다!
1. Attention sequence prediction
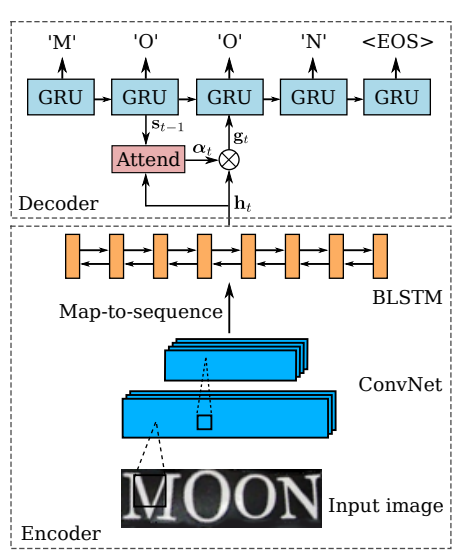
[1]
CTC를 활용하는 CRNN의 경우, column에 따라 prediction된 label의 중복된 것들을 제거해 줌으로써 원하는 형태의 label로 만들어주었습니다.
Attention 기반의 sequence prediction은 문장의 길이를 고정하고, 입력되는 Feature에 대한 Attention을 기반으로 해당 글자의 Label을 prediction합니다.
RNN으로 Character label을 뽑아낸다고 생각하면 됩니다. 첫 번째 글자에서 입력 feature에 대한 Attention을 기반으로 label을 추정하고, 추정된 label을 다시 input으로 사용하여 다음 글자를 추정해냅니다.
이때 20글자를 뽑겠다고 정하면 "YOU"같은 경우에는 3글자를 채우고 빈자리가 생깁니다.
빈자리를 위해 미리 정해둔 Token을 사용합니다. 이 Token에는 처음에 사용되는 "start" token과 끝에 사용되는 "end" token이 있습니다. 필요에 따라서 예외처리나 공백을 위한 token을 만들어서 사용합니다.
네이버 Clova의 논문 'What Is Wrong With Scene Text Recognition Model Comparisons? Dataset and Model Analysis'은 Attention 기반의 Recognition이 더욱 좋은 성능을 소개합니다. 이 논문에서는 CTC와 attention만이 아니라 TPS 등 Recognition에서 쓰이는 다양한 모듈들을 비교 평가를 하고 있습니다.
2. Transformer
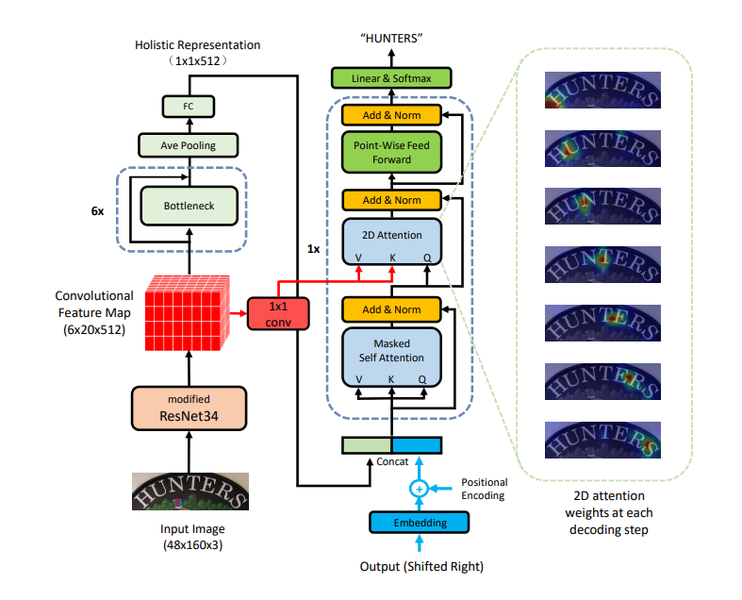
Transformer도 Recognition 모델에 활용되기 시작했습니다. 다양한 논문에서 시도되고 있지만 "A Simple and Robust Convolutional-Attention Network for Irregular Text Recognition"가 대표적인 논문입니다.
위 논문에서는 Irregular text를 잘 인식하기 위해서 2d space에 대한 attention을 활용하여 문자를 인식하기 위해 Transformer를 활용합니다.
Transformer는 Query, Key, Value라는 개념을 통해서 Self-Attention을 입력으로부터 만들어냅니다. 이를 통해서 입력에서 중요한 Feature에 대해 Weight를 줍니다.
Attention의 핵심은 Decoder의 현재 포지션에서 중요한 Encoder의 State에 가중치가 높게 매겨진다는 점입니다.
위에서 Attention이 시각화된 이미지를 눈으로 볼 수 있는데요, Decoder의 각 Step에 따라 입력에 대한 Visual Attention이 시각화된 모습입니다.
여기까지 OCR에 대해 공부를 해보았고,OCR을 직접 만들어보는 실습을 해보려고 합니다.
References
1️⃣ Robust Scene Text Recognition with Automatic Rectification
2️⃣ Focusing Attention: Towards Accurate Text Recognition in Natural Images
