Segmentation 시리즈
0️⃣ 딥러닝 Segmentation(1) - 개념, 용어, 종류(Semantic, Instance segmentation)
1️⃣ 딥러닝 Segmentation(2) - Semantic/Instance Segmentation
2️⃣ 딥러닝 Segmentation(3) - FCN(Fully Convolution Network)
3️⃣ 딥러닝 Segmentation(4) - U-Net
4️⃣ 딥러닝 Segmentation(5) - DeepLab 계열
5️⃣ 딥러닝 Segmentation(6) - segmentation 평가(Pixel Accuracy, Mask IOU)
6️⃣ 딥러닝 Segmentation(7) - Upsampling의 다양한 방법
Segmentation을 위한 대표적인 방법이 있다고 합니다.
이렇게 크게 세 가지가 있는 것 같은데 이번 게시글은 DeepLab의 내용을 다뤄볼 예정이며
주요 참고 자료
0️⃣ 해당 논문📃: Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation
1️⃣ 논문 리뷰📃: DeepLab V3+ 논문 리뷰 — DeepLab V3+: Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation
2️⃣ 논문 리뷰📃 : 2편: 두 접근의 접점, DeepLab V3+
을 참고할 예정입니다.
DeepLab
DeepLabv3+는 이름에서 알 수 있듯이 많은 버전을 거쳐 개선을 이뤄온 네트워크입니다. 처음 DeepLab이 제안된 뒤 개선하기 위해
- Atrous Convolution
- Spatial Pyramid Pooling
등 많은 방법들이 제안되어 왔습니다.
DeepLabV3+의 전체 구조를 본 뒤 Dilated Convolution이라고 불리는 Atrous Convolution과 Spatial Pyramid Pooling을 살펴보겠습니다.
모델의 구조
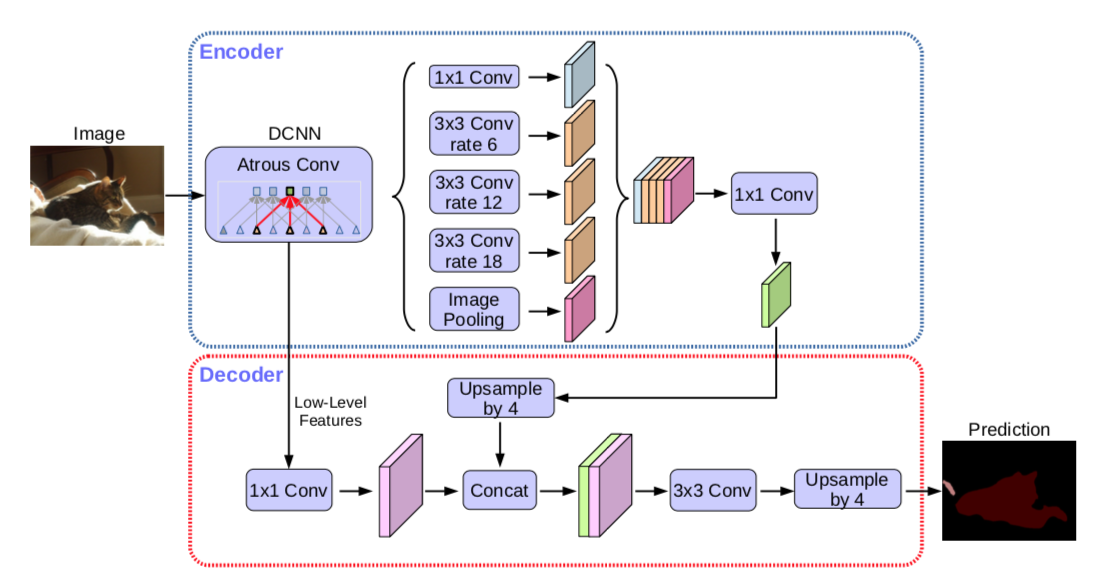
위 그림이 DeepLabV3+입니다. U-Net은 구조가 직관적으로 보였지만, DeepLabV3+는 그보다 조금 더 복잡해 보입니다. U-Net에서 Contracting path과 Expansive path의 역할을 하는 것이 위 그림의 인코더(Encoder), 디코더(Decoder)입니다.
Encoder는 이미지에서 필요한 정보를 feature로 추출해 내는 모듈
Decoder는 추출된 특성을 이용해 원하는 정보를 예측하는 모듈
입니다.
- Encoder를 통과해서 나온 feature map은 원본 사진보의 해상도보다 16배 작습니다.
- Decoding할 때 Low-Level Feature을 합쳐서 진행합니다.
- DeepLabV3+는 Atrous Convolution을 사용
- Atrous Convolution을 여러 크기에 다양하게 적용한 것이 ASPP(Atrous Spatial Pyramid Pooling) - DeepLab V3+는 ASPP가 있는 블록을 통해 feature를 추출하고 Decoder에서 Upsampling을 통해 segmentation mask를 얻고 있습니다.
Atrous Convolution
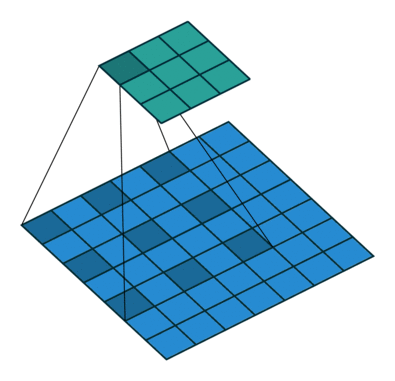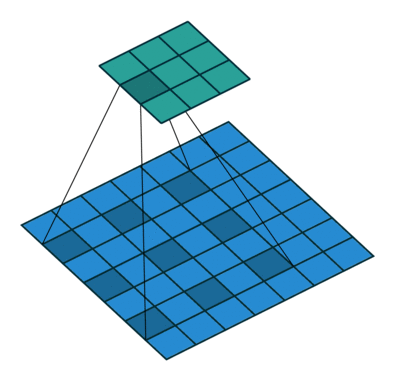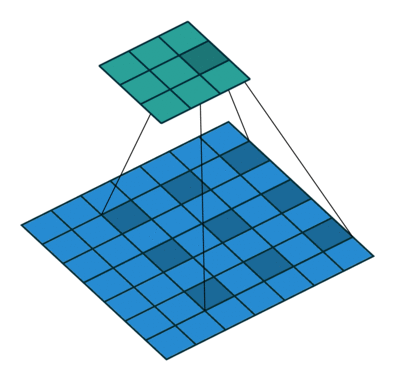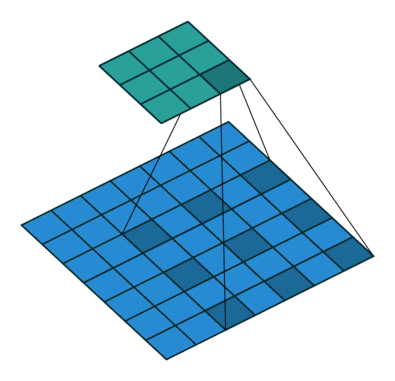
Atrous Convolution은 간단히 말하면 "띄엄띄엄 보는 컨볼루션"입니다. 위 그림에서 우측의 Atrous Convolution은 좌측의 일반적인 Convolution과 달리 더 넓은 영역을 보도록 해줍니다. kernel이 일정 간격으로 떨어져 있죠. 이를 통해 Convolution layer를 너무 깊게 쌓지 않아도 넓은 영역의 정보를 커버할 수 있게 됩니다.
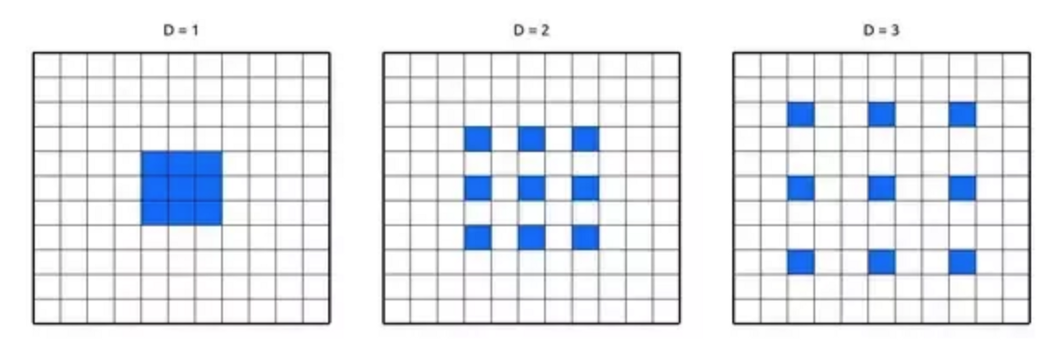
이는 같은 연산량으로 더 큰 feature을 잡아낼 수 있습니다. 다양한 확장 비율을 가진 Atrous Convolution을 병렬적으로 사용해서 더 많은 feature를 담아낼 수 있습니다. DeepLab V1~V3에서 쓰이는 방법입니다. Atrous Convolution을 Encoder에서 적절히 사용하고, 여기서 얻어진 feature map을 Decoder에 넣습니다.
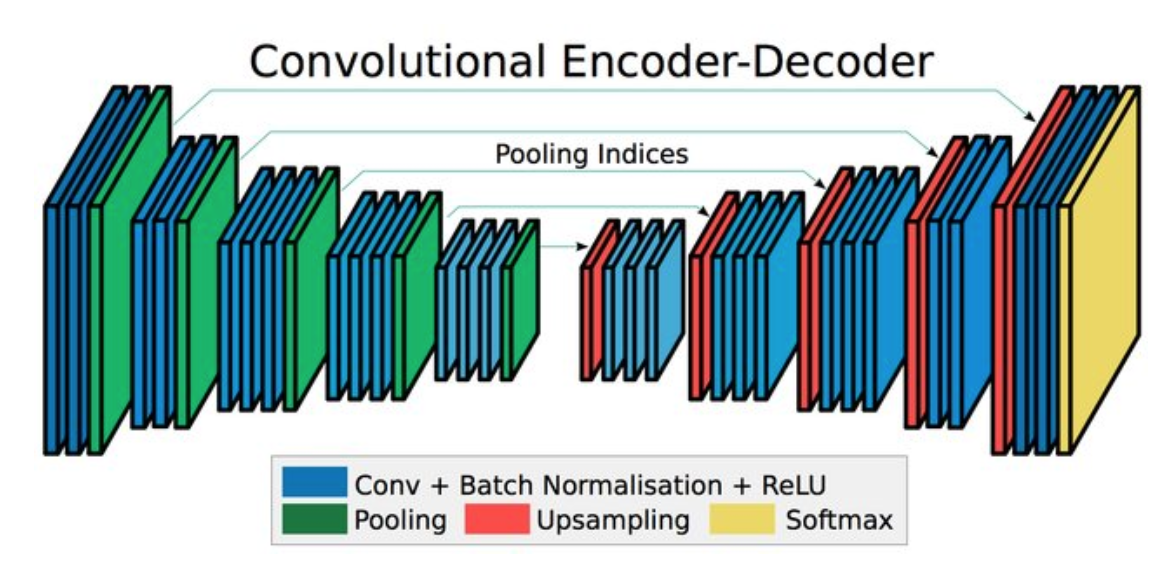
Spatial Pyramid Pooling
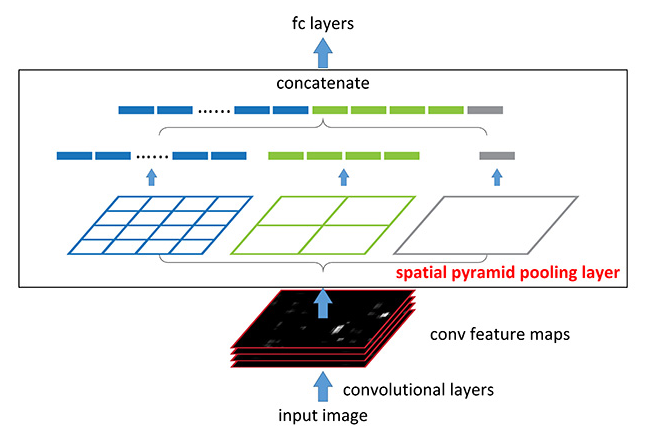
Spatial Pyramid Pooling은 여러 가지 scale로 convolution과 pooling 후 나온 feature를 concatenate합니다.
이를 통해서 multi-scale로 feature를 추출하는 것을 병렬로 수행하는 효과를 얻을 수 있습니다. 여기서 Convolution을 Atrous Convolution으로 바꾸어 적용한 것을 Atrous Spatial Pyramid Pooling이라고 합니다. 이러한 Architecture는 입력 이미지의 크기와 관계없이 동일한 구조를 활용할 수 있다는 장점이 있습니다. 그러므로 제각기 다양한 크기와 비율을 가진 RoI 영역에 대해 적용하기에 유리합니다.
여기까지 Segmentation의 주요 모델 3개(FCN, U-Net, DeepLab)을 살펴보았습니다. 이젠 세그멘테이션의 평가와 Upsampling 방법 등에 대해 포스팅하겠습니다.👏
