참고 자료 출처: 딥러닝을 이용한 자연어 처리 입문
멀티 헤드 어텐션(Multi-head Attention)
앞에서 배운 어텐션 d_model의 차원을 가진 벡터를 num_heads로 나누었고, 그 나눈 차원을 가지는 Q, K, V 벡터로 바꿔 어텐션을 수행했습니다!
논문 기준으로 512의 차원의 각 단어 벡터를 8로 나누어 64차원의 Q, K, V 벡터로 바꾸어서 어텐션을 수행한 셈인데, 이제 num_heads의 의미와 왜 d_model의 차원을 가진 벡터를 가지고 어텐션을 하지 않고 차원을 축소 시킨 벡터로 어텐션을 수행했는지를 보겠습니다.
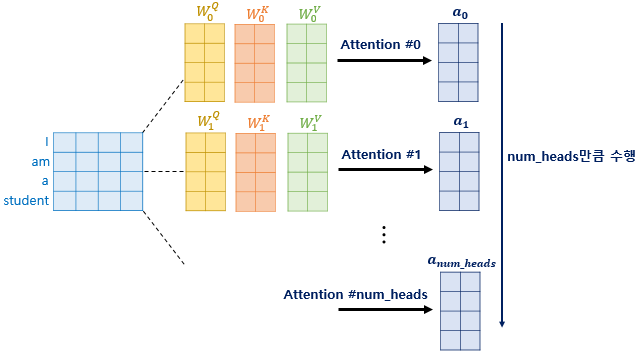
트랜스포머 연구진은 한 번의 어텐션을 하는 것보다 어텐션을 병렬로 여러번 사용하는 것이 더 효과적이라 판단했습니다. 그래서 d_model의 차원을 num_heads개로 나누어서 d_model/num_heads의 차원을 갖는 Q, K, V에 대해 num_heads개의 병렬 어텐션을 수행했습니다.
논문에서는 하이퍼파라미터인 num_heads를 8로 정했고, 8개의 병렬 어텐션이 이뤄집니다. 다시 말해 위에서 설명한 어텐션이 8개로 병렬로 이루어지는데, 이때 각각의 어텐션 값 행렬을 어텐션 헤드라고 부릅니다.
이때 가중치 행렬의 값은 8개의 어텐션 헤드마다 전부 다릅니다.
병렬 어텐션의 효과?
어텐션을 병렬로 수행하여 다른 시각으로 정보들을 수집하겠다는 의미입니다.
예문을 예를 들어 설명을 해본다면, '그 동물은 길을 건너지 않았다. 왜냐하면 그것은 너무 피곤하였기 때문이다.'를 생각해봅시다.
단어 '그것'이 쿼리였다고 하면, Q 벡터로부터 다른 단어와의 연고나도를 구하였을 때 첫 번째 어텐션 헤드는 '그것'과 '동물'의 연관도를 높게 본다면, 두 번째 어텐션 헤드는 '그것'과 '피곤하였기 때문이다'의 연관도를 더 높게 볼 수 있습니다.
각 어텐션 헤드는 전부 다른 시각에서 보고 있기 때문입니다.
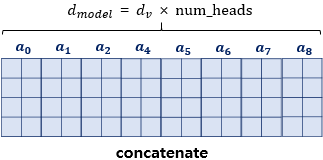
병렬 어텐션을 모두 수행하였다면 모든 어텐션 헤드를 연결(concatenate)합니다.
모두 연결된 어텐션 헤드의 크기는 (seq_len, d_model)이 됩니다.
멀티 헤드 어텐션(Multi-head Attention) 구현하기
멀티 헤드 어텐션에서는 크 게 두 종류의 가중치 행렬이 나왔습니다. 바로 Q, K, V 행렬을 만들기 위한 가중치 행렬인 WQ, WK, WV 행렬과 바로 어텐션 헤드들을 연결(concatenation) 후에 곱해주는 WO 행렬입니다. 가중치 행렬을 곱하는 것을 구현 상에서는 입력을 밀집층(Dense layer)를 지나게 하므로서 구현합니다. 케라스 코드 상으로 지금까지 줄기차게 사용해왔던 Dense()에 해당됩니다.
Dense(units)멀티 헤드 어텐션의 구현은 크게 다섯 가지 파트로 구성됩니다.
- WQ, WK, WV에 해당하는 d_model 크기의 밀집층(Dense layer)을 지나게한다.
- 지정된 헤드 수(num_heads)만큼 나눈다(split)
- 스케일드 닷 프로덕트 어텐션
- 나눠졌던 헤드들을 연결(concatenatetion)한다.
- WO에 해당하는 밀집층을 지나게 한다.
이론으로 설명할 때보다 심플하게 구성되었는데 결국 근본적으로 동일한 내용입니다.
import tensorflow as tf
import tensorflow_datasets as tfds
import os
import re
import numpy as np
import matplotlib.pyplot as plt
from tensorflow import keras
class MultiHeadAttention(tf.keras.layers.Layer):
def __init__(self, d_model, num_heads, name="multi_head_attentio "):
super(MultiHeadAttention, self).__init__(name=name)
self.num_heads = num_heads
self.d_model = d_model
assert d_model % self.num_heads == 0
# d_model을 num_heads로 나눈 값
# 논문 기존 : 64
self.depth = d_model // self.num_heads
# WQ, WK, WV에 해당하는 밀집층 정의
self.query_dense = tf.keras.layers.Dense(units=d_model)
self.key_dense = tf.keras.layers.Dense(units=d_model)
self.value_dense = tf.keras.layers.Dense(units=d_model)
# WO에 해당하는 밀집층 정의
self.dense = tf.keras.layers.Dense(units=d_model)
# num_heads 개수만큼 q, k, v를 split하는 함수
def split_heads(self, inputs, batch_size):
inputs = tf.reshape(
inputs, shape(batch_size, -1, self.num_heads, self.depth))
return tf.transpose(inputs, perm=[0,2,1,3])
def call(self, inputs):
query, key, value, mask = inputs['query'], inputs['key'], inputs['value'], inputs['mask']
batch_size = tf.shape(query)[0]
# 1. WQ, WK, WV에 해당하는 밀집층 지나기
# q : (batch_size, query의 문장 길이, d_model)
# k : (batch_size, key의 문장 길이, d_model)
# v : (batch_size, value의 문장 길이, d_model)
# 참고) 인코더(k, v)-디코더(q) 어텐션에서는 query 길이와 key, value의 길이는 다를 수 있다.
query = self.query_dense(query)
key = self.key_dense(key)
value = self.value_dense(value)
# 2. 헤드 나누기
# q : (batch_size, query의 문장 길이, d_model/num_heads)
# k : (batch_size, key의 문장 길이, d_model/num_heads)
# v : (batch_size, value의 문장 길이, d_model/num_heads)
query = self.split_heads(query, batch_size)
key = self.split_heads(key, batch_size)
value = self.split_heads(value, batch_size)
# 3. 스케일드 닷 프로덕트 어텐션. 앞서 구현한 함수 사용
# (batch_size, num_heads, query의 문장 길이, d_model/num_heads)
scaled_attention, _ = scaled_dot_product_attention(query, key, value, mask)
# (batch_size, query의 문장 길이, num_heads, d_model/num_heads)
scaled_attention = tf.transpose(scaled_attention, perm=[0,2,1,3])
# 4. 헤드 연결(concatenate)하기
# (batch_size, query의 문장 길이, d_model)
concat_attention = tf.reshape(scaled_attention, batch_size, -1, self.d_model)
# 5. WO에 해당하는 밀집층 지나기
# (batch_size, query의 문장 길이, d_model)
outputs = self.dense(concat_attention)
return outputs
멀티 헤드 어텐션을 구현하면 다음과 같습니다. 내부적으로는 스케일드 닷 프로덕트 어텐션 함수를 호출합니다.
스케일드 닷 프로덕트 어텐션 함수 구현 방법 보러 가기
