참고 자료 출처: 딥러닝을 이용한 자연어 처리 입문
목차
- 인코더 층 만들기
- 인코더 쌓기
인코더 층 만들기
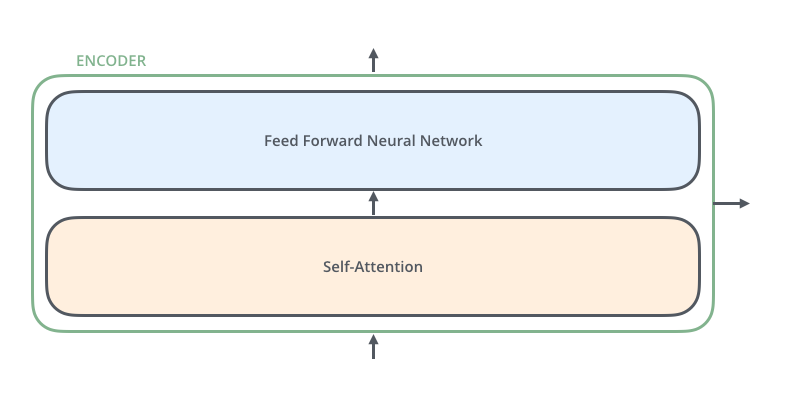
[출처 : http://jalammar.github.io/illustrated-transformer/]
하나의 인코더 층은 두 개의 서브 층(sublayer)으로 나누어집니다.
- 셀프 어텐션
- 피드 포워드 신경망
셀프 어텐션은 멀티 헤드 어텐션으로 병렬적으로 이루어집니다. 인코더 하나의 레이어를 함수로 표현해보겠습니다. 앞서 설명했듯이, 하나의 레이어 안에는 두 서브층이 구현됩니다.
def encoder_layer(dff, d_model, num_heads, dropout, name="encoder_layer"):
inputs = tf.keras.Input(shape=(None, d_model), name="inputs")
# 인코더는 패딩 마스크 사용
padding_mask = tf.keras.Input(shape=(1,1,None), name="padding_mask")
# 멀티-헤드 어텐션(첫 번째 서브층 / 셀프 어텐션)
attention = MultiHeadAttention(
d_model, num_heads, name="attention")({
'query': inputs,
'key' : inputs,
'value' : inputs, # Q = K = V
})
# 드롭아웃 + 잔차 연결과 층 정규화
attention = tf.keras.layers.Dropout(rate=dropout)(attention)
attention = tf.keras.layers.LayerNomalization(
epsilon=1e-6)(inputs+attention)
# 포지션 와이즈 피드 포워드 신경망 (두 번째 서브층)
outputs = tf.keras.layers.Dense(units=dff, activation='relu')(attention)
outputs = tf.keras.layers.Dense(units=d_model)(outputs)
# 드롭아웃 + 잔차 연결과 층 정규화
outputs = tf.keras.layers.Dropout(rate=dropout)(outputs)
outputs = tf.keras.layers.LayerNirmalization(
epsilon=1e-6)(attention+outputs)
return tf.keras.Model(
inputs=[inputs, padding_mask], outputs=outputs, name=name)인코더의 입력으로 들어가는 문장에 패딩이 있을 수 있습니다. 어텐션 할 때 패딩 토큰을 제외하도록 패딩 마스크를 사용합니다.
이는 MultiHeadAttention 함수의 mask 인자 값으로 padding_mask가 들어가는 이유입니다.
인코더는 두 개의 서브층으로 이루어져 있었죠. 각 서브 층 이후에는 드롭 아웃, 잔차 연결과 층 정규화가 수행됩니다.
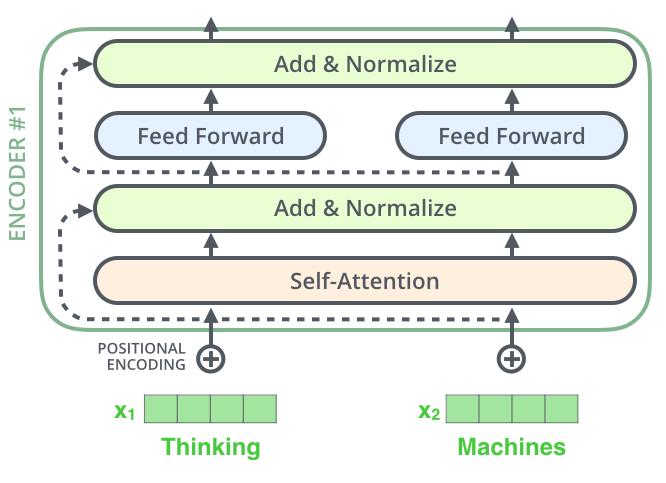
[출처 : http://jalammar.github.io/illustrated-transformer/]
위의 코드는 하나의 인코더 층을 구현하는 블록입니다. 실제 트랜스포머는 num_layers 개수만큼 인코더 층을 사용하기에 여러 번 쌓는 코드를 구현해줘야 합니다!
인코더 쌓기
지금까지 인코더 층의 내부 아키텍처에 대해서 이해해보았습니다. 이러한 인코더 층을 num_layers개만큼 쌓고, 마지막 인코더 층에서 얻는 (seq_len, d_model) 크기의 행렬을 디코더로 보내주면서 트랜스포머 인코더의 인코딩 연산이 끝나게 됩니다.
아래의 코드는 인코더 층을 num_layers개만큼 쌓는 코드입니다.
def encoder(vocab_size num_layers, dff, d_model, num_heads, dropout,name='encoder'):
inputs = tf.keras.Input(shape=(None,), name="inputs")
# 인코더는 패딩 마스크 사용
padding_mask = tf.keras.Input(shape=(1,1,None), name="padding_mask")
# 포지셔널 인코딩 + 드롭아웃
embeddings = tf.keras.layers.Embedding(vocab_size,, d_model)(inputs)
embeddings = tf.keras.sqrt(tf.cast(d_model, tf.float32))
embeddings = PositionalEncoding(vocab_size, d_model)(embeddings)
# 인코더를 num_layers개 쌓기
for i in range(num_layers):
outputs = encoder_layer(dff=dff, d_model=d_model, num_heads=num_heads,
dropout=dropout, name="encoder_layer_{}".format(i),
)([outputs, padding_mask])
return tf.keras.Model(
inputs=[inputs, padding_mask], outputs=outputs, name=name)
AI/ML Engineer