
참고 자료 출처: 딥러닝을 이용한 자연어 처리 입문
목차
- 디코더 층
- 디코더 구현하기
- 디코더 쌓기
디코더 층
디코더는 인코더와 비슷하지만, 인코더보다 조금 더 복잡합니다. 인코더는 두 개의 서브 층으로 구성되지만, 디코더는 세 개의 서브 층으로 구성됩니다.
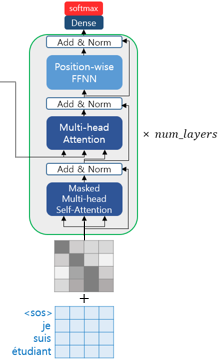
- 셀프 어텐션
- 인코더-디코더 어텐션
- 피드 포워드 신경망
디코더의 두번째 서브층은 멀티 헤드 어텐션을 수행한다는 점에서는 이전의 어텐션들(인코더와 디코더의 첫번째 서브층)과 같지만, 셀프 어텐션은 아닙니다.
셀프 어텐션은 Query, Key, Value가 같은 경우를 말하는데, 인코더-디코더 어텐션은 Query가 디코더의 벡터인 반면에, key와 value 인코더의 벡터라는 특징이 있습니다.
다시 한 번 각 서브층에서의 Q, K, V의 관계를 정리해봅시다.
- 인코더의 첫번째 서브층 : Query = Key = Value
- 디코더의 첫번째 서브층 : Query = Key = Value
- 디코더의 두번째 서브층 : Query : 디코더 행렬 / Key = Value : 인코더 행렬
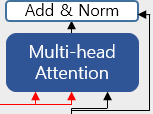
디코더의 두 번째 서브층을 자세히 보면 인코더로부터 두 개의 화살표가 있습니다.
두 개의 화살표는 각각 Key와 Value를 의미하며, 이는 인코더의 마지막 층에서 온 행렬로부터 얻습니다.
반면, Query는 디코더의 첫 번째 서브층의 결과 행렬로부터 얻는다는 점이 다릅니다.
Query가 디코더 행렬, key가 인코더 행렬일 때, 어텐션 스코어 행렬을 구하는 과정은
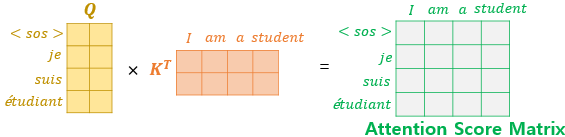
이와 같습니다.
디코더 구현하기
인코더의 셀프 어텐션처럼 디코더의 셀프 어텐션, 인코더-디코더 어텐션은 모두 스케일드 닷 프로덕트 어텐션을 멀티 헤드 어텐션으로 병렬적으로 수행합니다.
def decoder_layer(dff, d_model, num_heads, dropout, name="decoder_layer"):
inputs = tf.keras.Input(shape=(Nome, d_model), name="inputs")
enc_outputs = tf.keras.Input(shape=(None, d_model), name="encoder_outputs")
# 룩어헤드 마스크(첫 번째 서브층)
look_ahead_mask = tf.keras.Input(
shape=(1, None, None), name="look_ahead_mask")
# 패딩 마스크(두 번째 서브층)
padding_mask = tf.keras.Input(shape=(1,1,None), name="padding_mask")
# 멀티- 헤드 어텐션(첫 번째 서브층 / 마스크드 셀프 어텐션)
attention1 = MultiAttention(d_model, num_heads, name="attention_1")(
inputs={
'query': inputs,
'key' : inputs,
'value' : inputs, # Q = K = V
'mask' : look_ahead_mask
})
# 잔차 연결과 층 정규화
attention1 = tf.keras.layers.LayerNormalization(epsilon=1e-6)(attention1 + inputs)
# 멀티-헤드 어텐션 (두 번째 서브층/ 디코더-인코더 어텐션)
attention2 = MultiAttention(d_model, num_heads, name="attention_2")(
inputs={
'query': attention1,
'key' : enc_outputs,
'value' : enc_outputs, # Q != K = V
'mask' : padding_mask # 패딩 마스크
})
# 드롭아웃 + 잔차 연결과 층 정규화
attention2 = tf.keras.layers.Dropout(rate=dropout)(attention2)
attention2 = tf.keras.layers.LayerNormalization(epsilon=1e-6)(attention2 + attention1)
# 포지션 와이즈 피드 포워드 신경망 (세번째 서브층)
outputs = tf.keras.layers.Dense(units=dff, activation='relu')(attention2)
outputs = tf.keras.layers.Dense(units=d_model)(outputs)
# 드롭아웃 + 잔차 연결과 층 정규화
outputs = tf.keras.layers.Dropout(rate=dropout)(outputs)
outputs = tf.keras.layers.LayerNormalization(epsilon=1e-6)(outputs + attention2)
return tf.keras.Model(
inputs=[inputs, enc_outputs, look_ahead_mask, padding_mask],
outputs=outputs, name=name)❗ 정리
디코더는 총 세 개의 서브층으로 구성됩니다. 첫 번째와 두 번째 모두 멀티 헤드 어텐션이지만, 첫 번째 서브층은 mask의 인자값으로 look_ahead_mask가 들어가는 반면, 두 번째 서브층은 mask의 인자값으로 padding_mask가 들어갑니다.
이는 첫 번째 서브층은 마스크드 셀프 어텐션을 수행하기 때문입니다. 세 개의 서브층 모두 서브층 연선 후에는 드롭 아웃, 잔차 연결, 층 정규화가 수행됩니다.
인코더와 마찬가지로 디코더도 num_layers개 만큼 쌓는 코드가 필요합니다.
디코더 쌓기
def decoder(vocab_size, num_layers, dff,
d_model, num_heads, dropout,
name='decoder'):
inputs = tf.keras.Input(shape=(None,), name='inputs')
enc_outputs = tf.keras.Input(shape=(None, d_model), name='encoder_outputs')
# 디코더는 룩어헤드 마스크(첫번째 서브층)와 패딩 마스크(두번째 서브층) 둘 다 사용.
look_ahead_mask = tf.keras.Input(
shape=(1, None, None), name='look_ahead_mask')
padding_mask = tf.keras.Input(shape=(1, 1, None), name='padding_mask')
# 포지셔널 인코딩 + 드롭아웃
embeddings = tf.keras.layers.Embedding(vocab_size, d_model)(inputs)
embeddings *= tf.math.sqrt(tf.cast(d_model, tf.float32))
embeddings = PositionalEncoding(vocab_size, d_model)(embeddings)
outputs = tf.keras.layers.Dropout(rate=dropout)(embeddings)
# 디코더를 num_layers개 쌓기
for i in range(num_layers):
outputs = decoder_layer(dff=dff, d_model=d_model, num_heads=num_heads,
dropout=dropout, name='decoder_layer_{}'.format(i),
)(inputs=[outputs, enc_outputs, look_ahead_mask, padding_mask])
return tf.keras.Model(
inputs=[inputs, enc_outputs, look_ahead_mask, padding_mask],
outputs=outputs,
name=name) 지금까지 인코더 층 쌓기(보러가기)와 디코더 층 쌓는 것을 함수로 구현했습니다.
이를 하나로 조합하여 트랜스포머 모델을 만들 수 있습니다.
