Word Embedding
🔗 One-hot encoding
- Pre-existing word representation method
- 어떤 word쌍이든 inner-product similarity는 항상 0이고 euclidean distance는 항상 2^(1/2)
🔗 Neural word embedding
- Motivation : word vector를 one hot vector로 나타내지 않고 continuous representation으로 나타내어 'cat'과 'kitty'가 'cat'과 'hamburger'에 비교하여 가깝게 있도록 한다.
🔗 Two Models of Word2Vec
-
Continuous Bag-Of-Words (CBOW)
-
Skip-gram
-
Limitation : Word embedding을 train하고 나면 fixed된다. Single word가 multiple meanings를 가지고 있어도 Word2vec은 이를 포착할 수 없고 context에 따라 바뀌지 않는다.
Contextualized Word Embedding
이제 더이상 word embedding을 훈련하고 load하는 것이 아니라, word embedding을 generate하는 model을 훈련한다. 그리고 downstream task에서, 이 model을 load하고 sentence를 model에 feed in하여 contextualize word embeddings를 회수한다.
ELMo
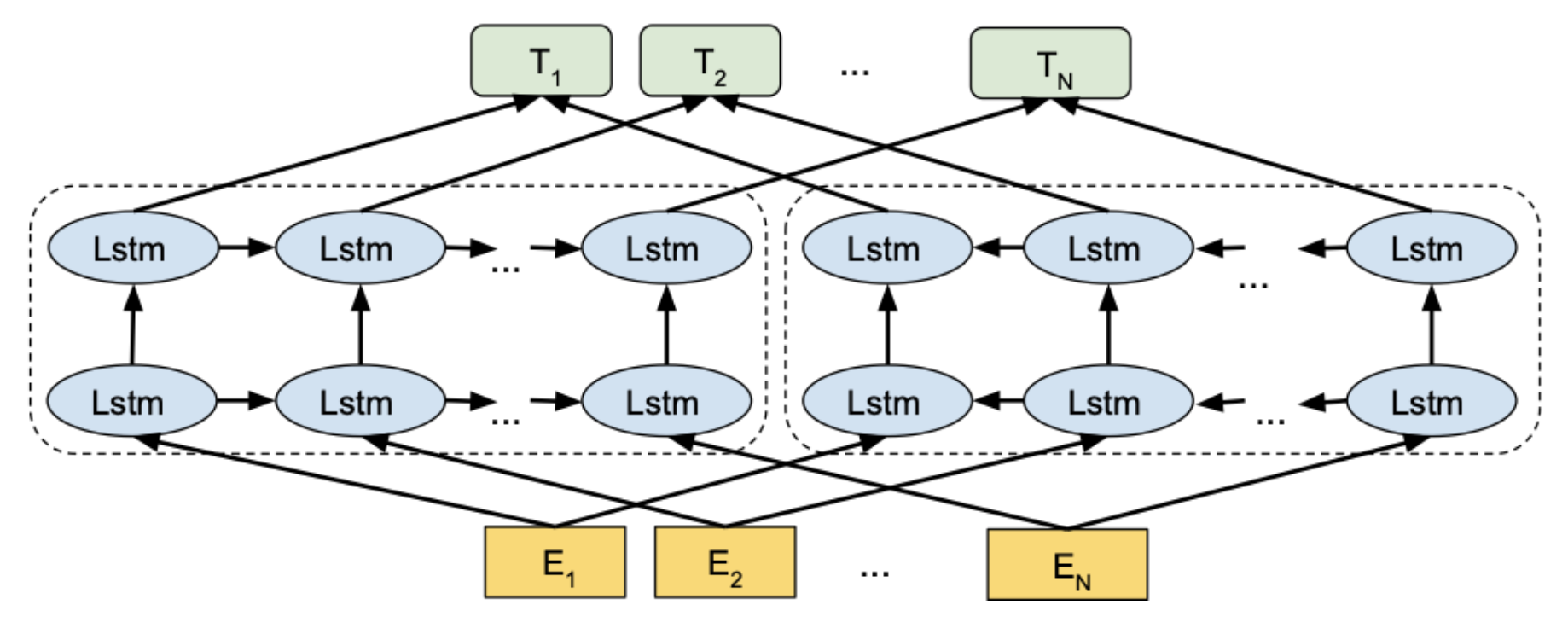
-
Very first contextualized word embedding generator
-
A simple bi-directional multi-layer LSTM
- Residual connections between layers
-
각 , , ... , 은 token embedding이며, 이 token embedding을 forward로 한번, backward로 한번 총 두 번 RNN에 feed한다. 그리고 top layer에 있는 hidden layer들을 concatenate해서 final contextualize word embedding을 얻는다.
-
Trained via bidirection language modeling
-
Final Ts는 dynamically하게 변한다. 그래서 같은 word가 context에 따라서 다른 word embedding을 가질 수 있다.
-
Performance
- Forward-LM perplexity : 39.7
- perplexity: context가 주어졌을 때, 많은 다른 english word중에서 next word를 40개 이내의 후보 words로 좁힐 수 있다.
- Forward-LM perplexity : 39.7
Sentiment Classification
🔗 Sentiment classification with one-hot embedding
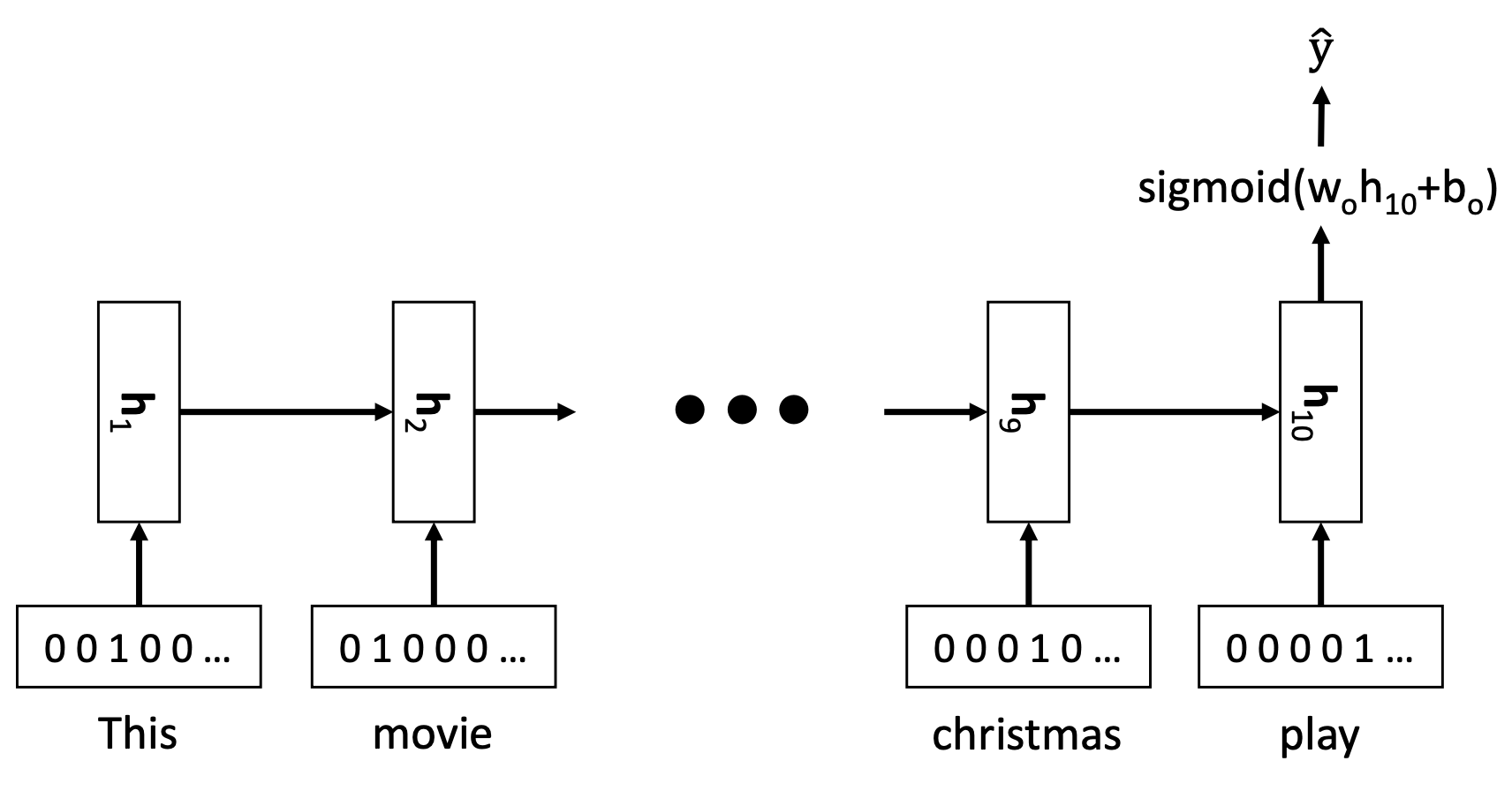
- 단어를 간단히 one-hot embedding으로 표현하여 RNN에 feed in
🔗 Sentiment classification with word2vec embedding
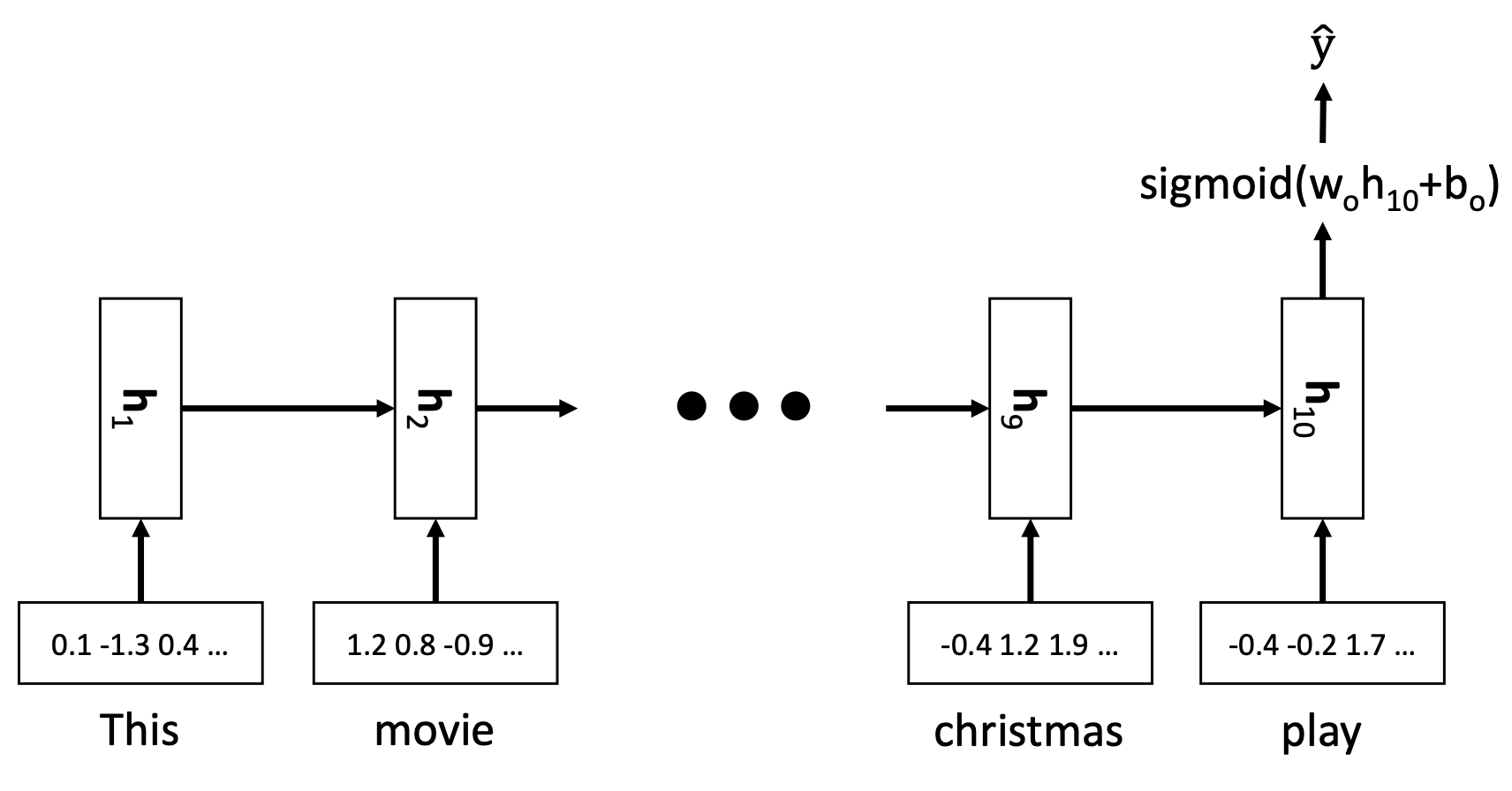
- One-hot vector 대신 word2vec vector를 사용
- Look-up table과 같은 dictionary가 있어서, 각 column은 single word를 represent한다. Downstream task에서는 이 matrix에서 word embedding column을 load하여 각 word의 initial point로 사용
🔗 Sentiment classification with ELMo
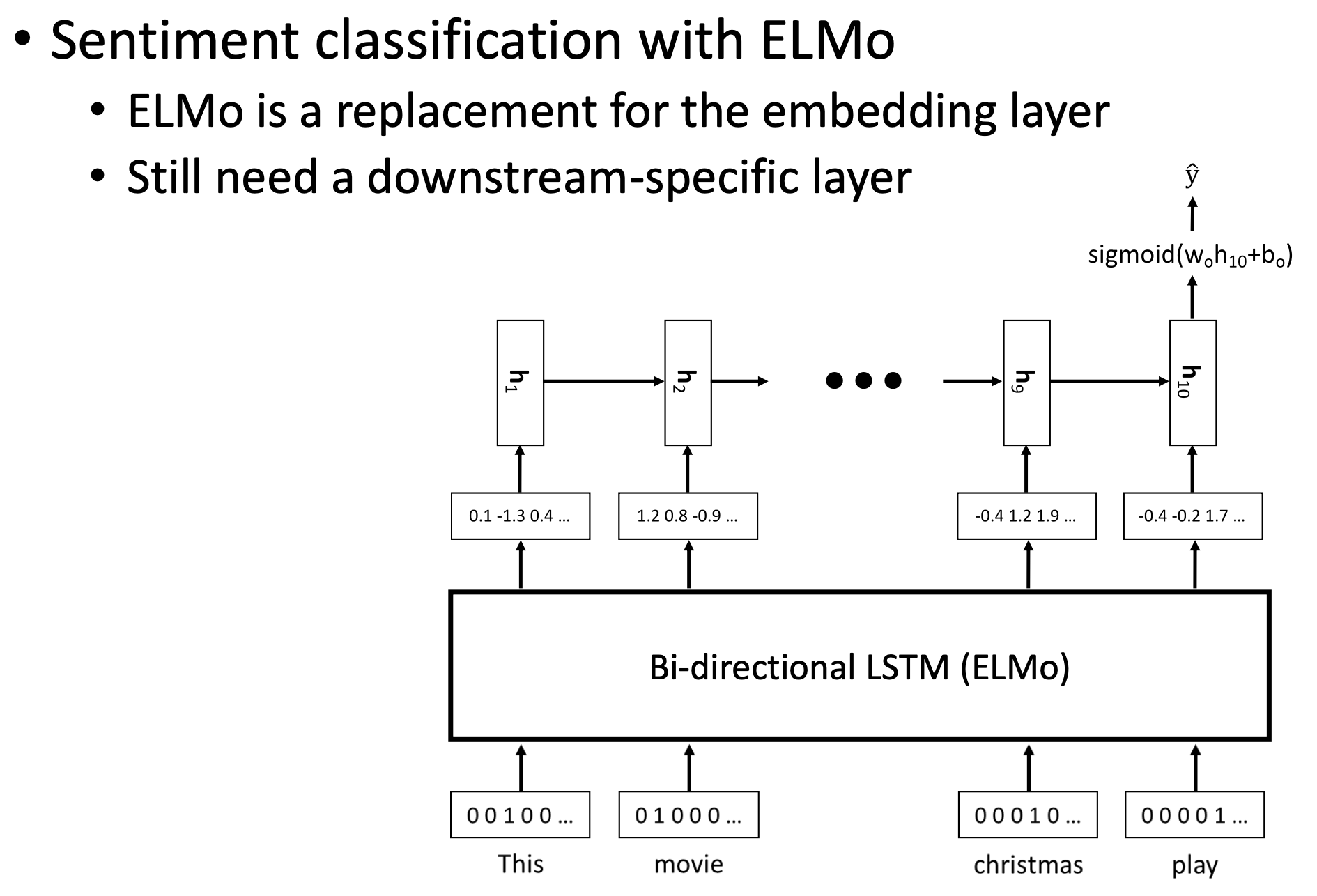
- Pretrained word embedding들을 load하는 대신에 ELMo model을 plug in 한다.
- , , ... , : input toekns
- , , ... , : contextualize word embeddings from ELMo
- 그리고 이 contextualize word embedding(ELMo's output)이 downstream task model의 input이 된다.
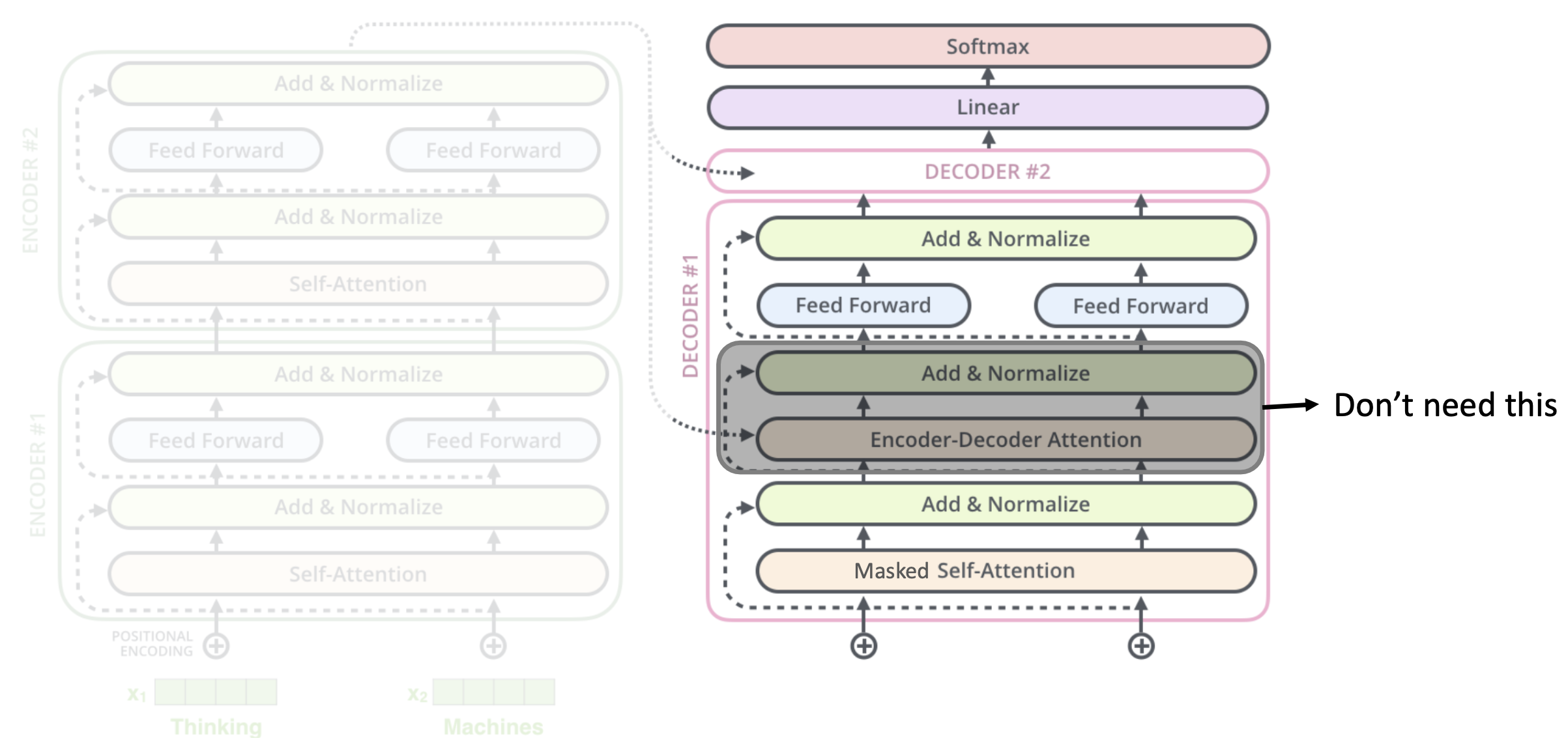
GPT-1
- Transformer decoder without Enc-Dec attention
- Trained via only forward language modeling
🔗 Architecture
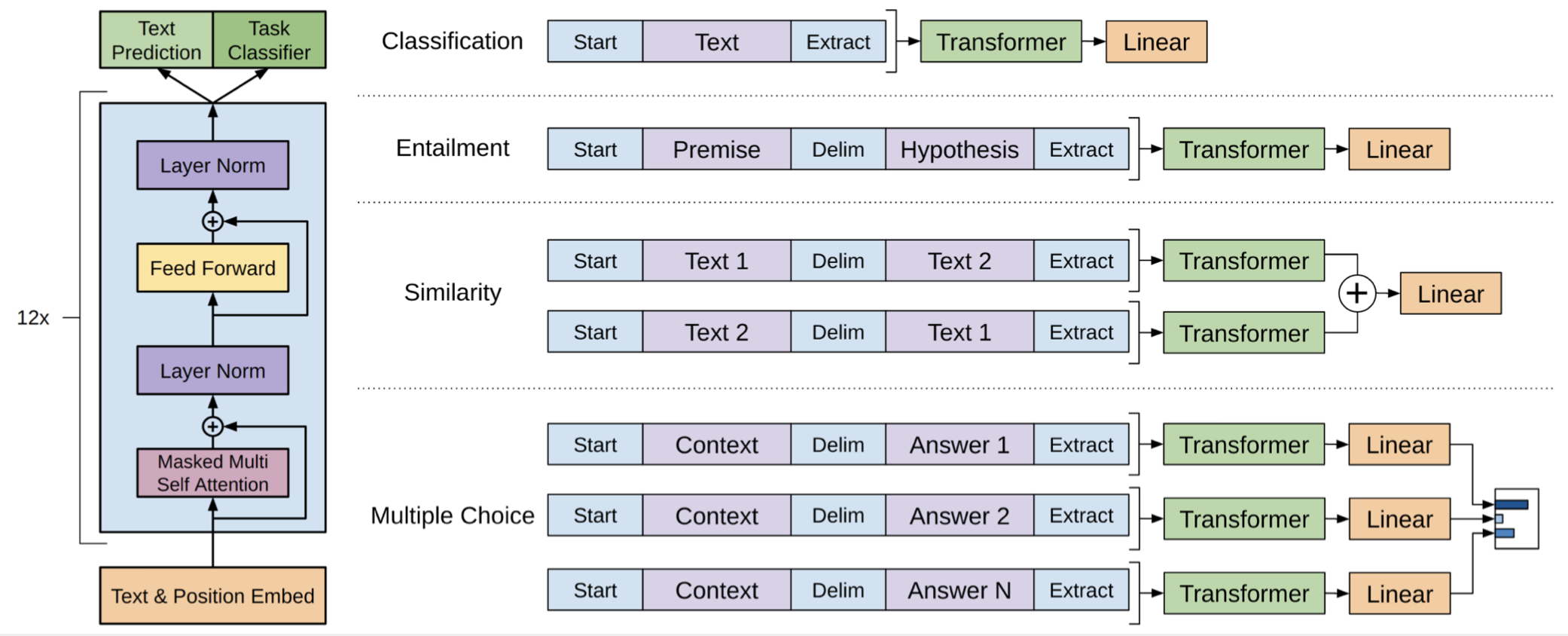
🔗 GPT-1 on Downstream Tasks
- Pre-train on BooksCorpus (perplexity 18.4)
- Downstream specific architecture로는 오직 one linear layer가 필요
- Fine-tuning the entire GPT with the supervised labels.
BERT
- Bidirectional Encoder Representations from Transformers
- GPT, BERT 둘다 word embedding generator가 되는 것이 motivation이었다.
- ELMo의 bi-directionality와 GPT의 powerful transformer 두 개를 동시에 취한다.
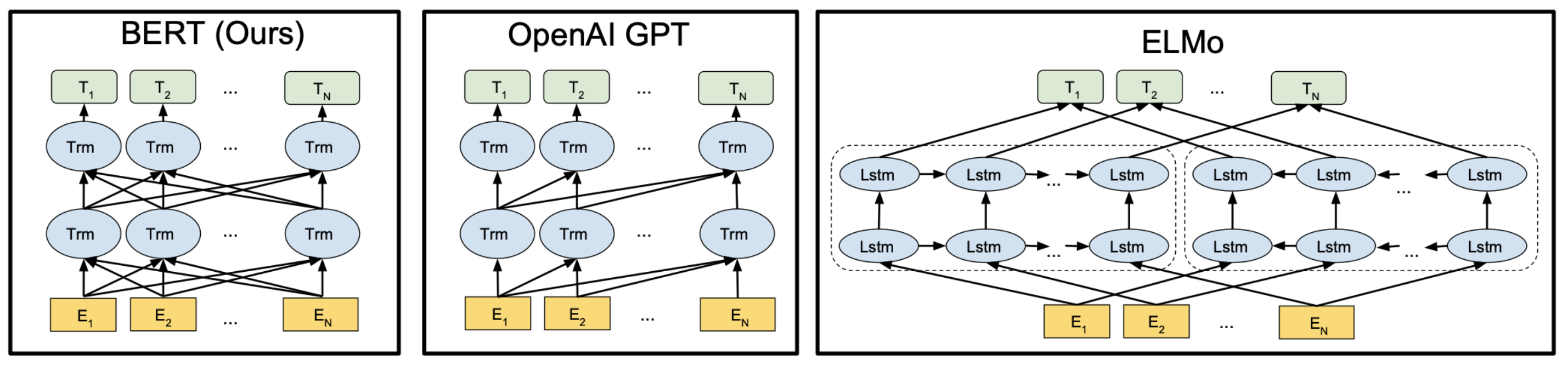
🔗 BERT Architecture
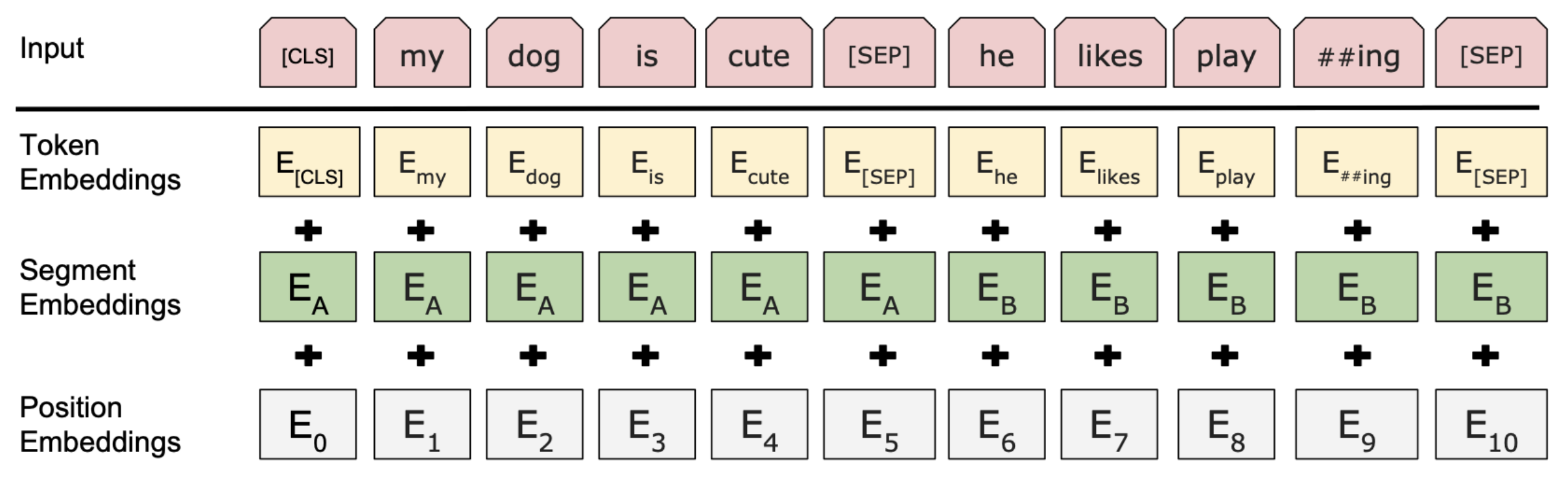
- BERT는 label없이 train한다.
- Input이 original Transformer와 조금 다르다. BERT는 pretraining stage에서 항상 2개의 sentence로 train된다.
- Segment Embeddings : two trainable embeddings , 를 가진다.
- Token Embeddings : subword embedding, look-up table search
- [CLS] : Special tokens representing all input
🔗 BERT Pre-training
- BERT의 목적은 generate well representative contextualize word embedding이다.
- BERT Pre-training에 두 가지 task가 있다.
- Maked Language Modeling
- Next sentence prediction
⭐️ Masked Language Modeling
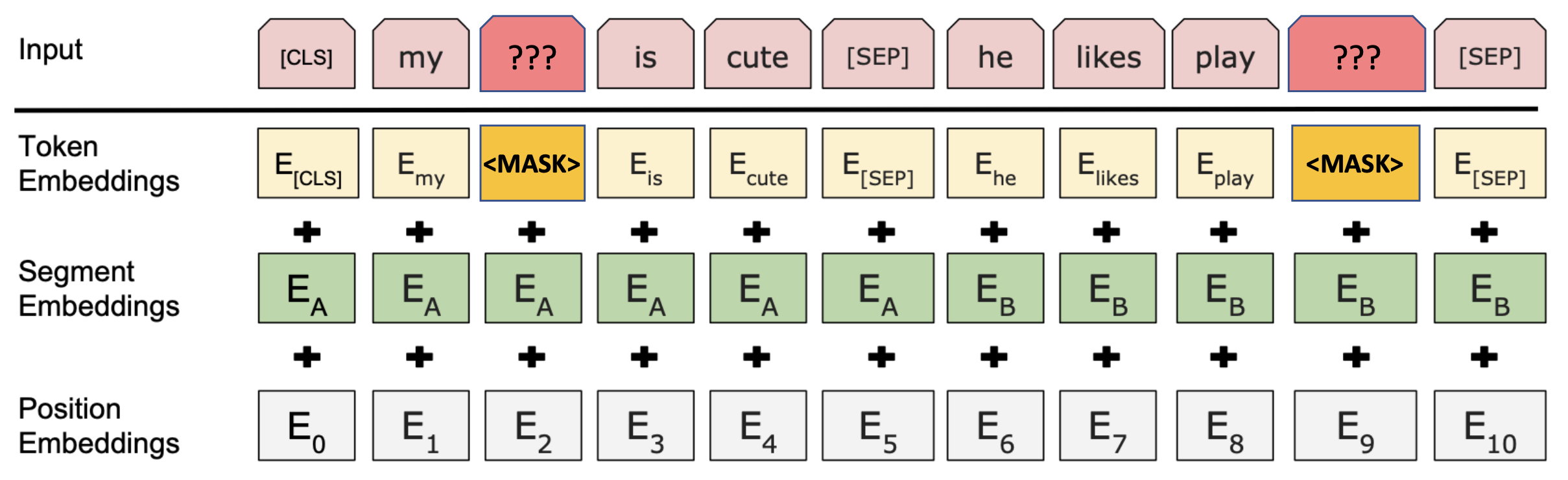
- Input의 15%를 random하게 masked tokens로 바뀐다.
- MASK token : special token
- Segment embedding과 position embedding은 그대로 놔두고, token이 MASK token으로 바뀐다.
- position embedding이 있어 여러 MASK token이 구별된다.
- Cheap operation - human annotation이 필요하지 않다.
- BERT의 핵심
✔️ Next sentence prediction
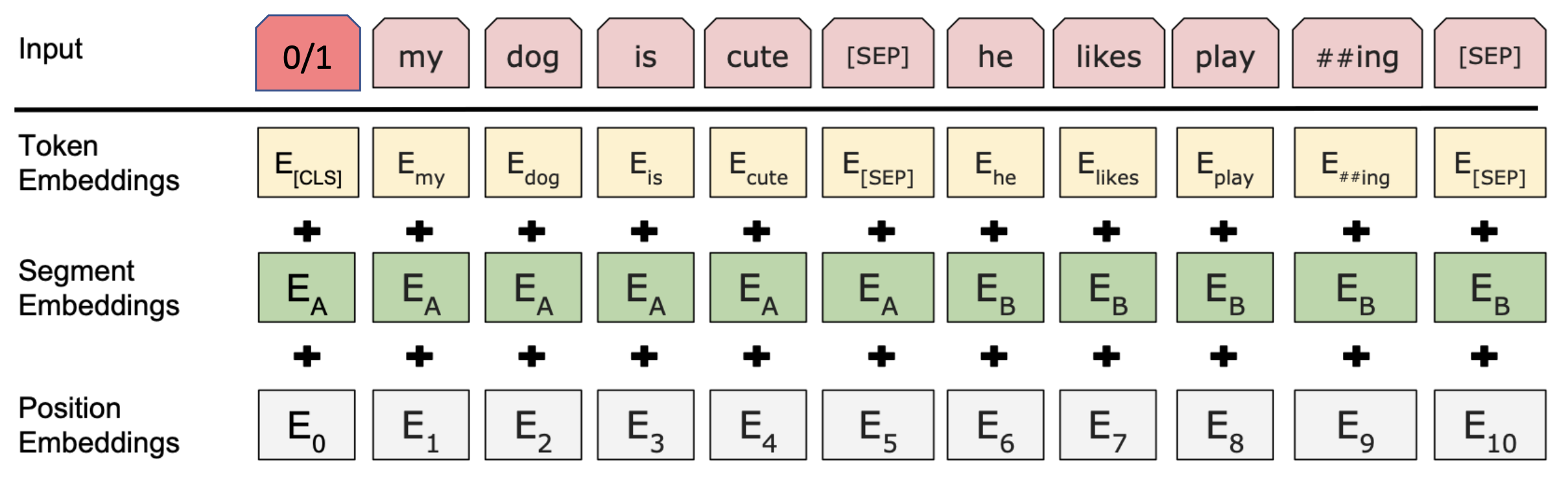
- CLS를 사용하여 binary classification을 한다. 두 sentence가 실제 neighbor이면 1, 아니면 0이다.
- 몇몇 downstream task에는 도움이 되지만 요즘에는 NSP를 사용하지 않는다.
🔗 BERT on Downstream Tasks
- Masked LM perplexity of BERT-Base : ~4
- Different input/output for different downstream task (all fine-tuned). BERT format에 호환되도록 input을 조금 변형해야한다.
-
Paraphrase detection
- Input: Sentence A and sentence B
- Output: CLS + Linear classifier
전체 input의 representation인 CLS token을 가져와 linear classifier를 통해 1 또는 0을 predict한다.
-
Sequence tagging
- Input: Text and PAD
- Output: Token embeddings + Linear classifier
2개의 문장이 필요하지 않으므로 PAD를 사용하여 input을 변형한다.
-
Text classification
-
Input: Text and PAD
-
Output: CLS + Linear classifier
전체 input의 representation인 CLS token을 가져와 linear classifier를 통해 predict한다.
-
-
- BERT는 ELMo처럼 task specific layer를 가지지 않고 단지 12개의 Transformer layer와 1개의 linear layer(task specific logit generation)만 가진다.
SQuAD Dataset
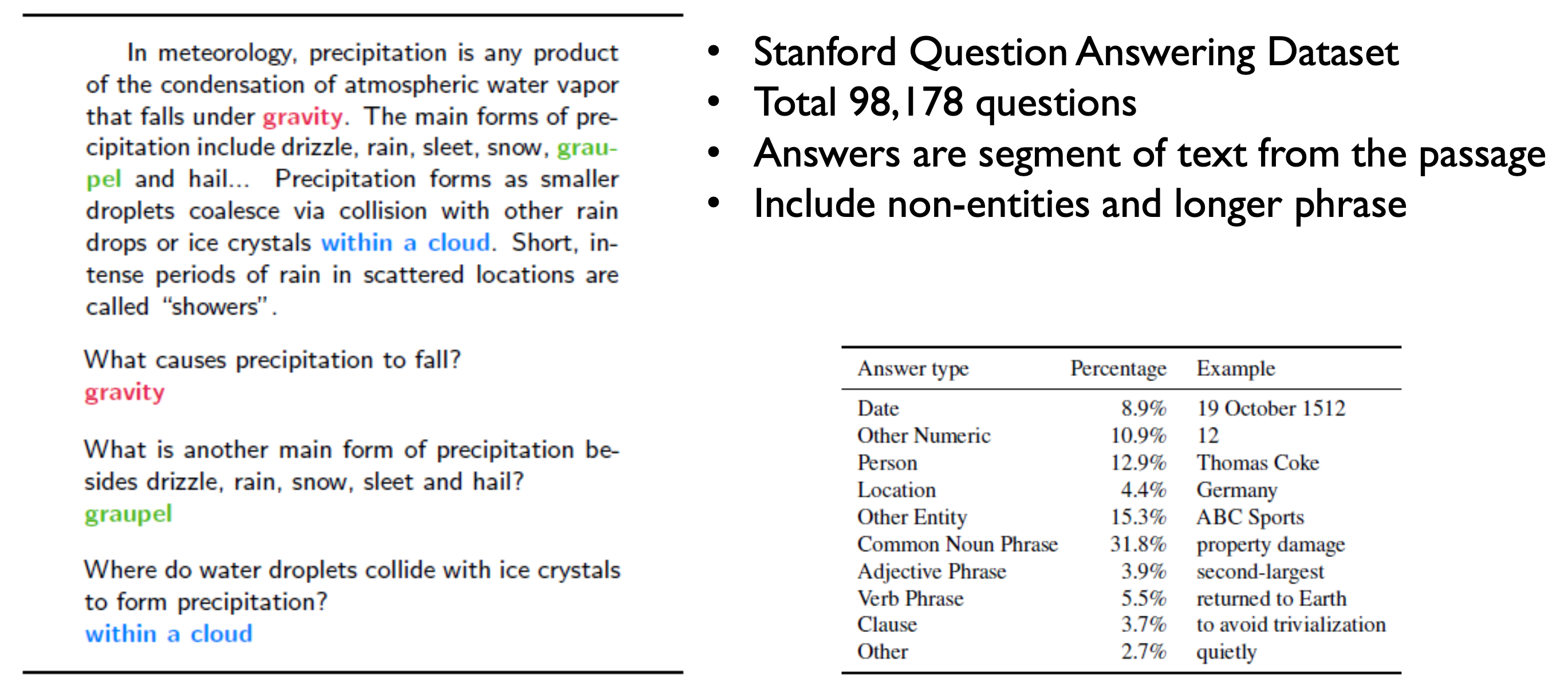
- Version 2.0에는 50,000개의 unanswerable questions가 추가되었다.
🔗 Evaluation method
- Exact match(EM) : percentage of correct answers
- F1-measure : Harmonic mean between precision and recall
- give partial scores to partial span.
🔗 Fine-Tuning for SQuAD
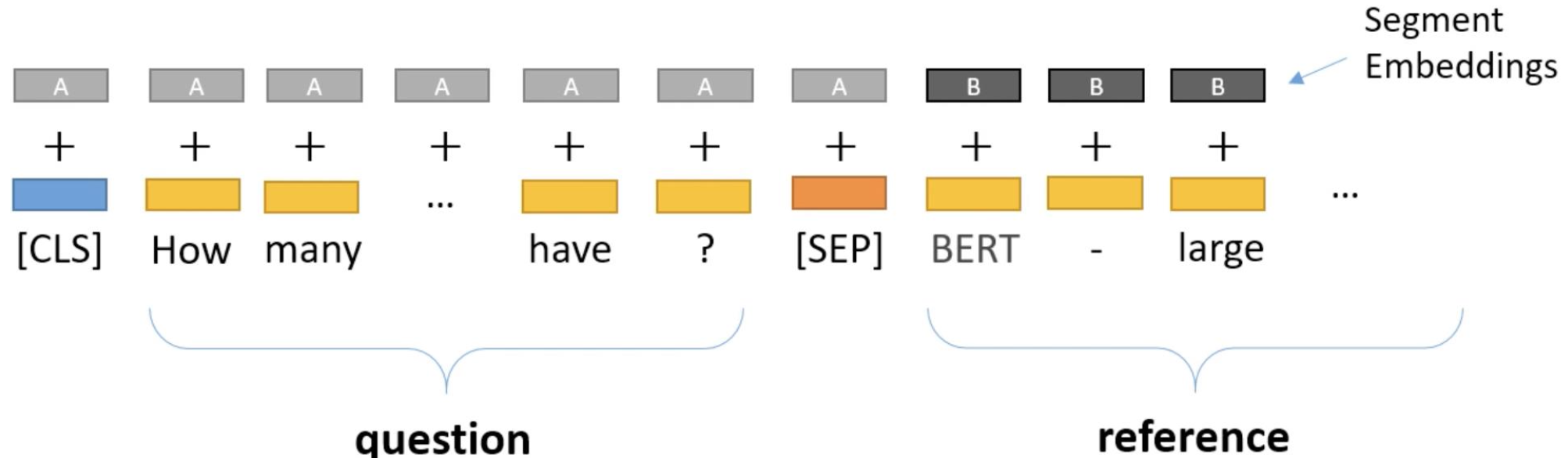
-
SQuAD type의 dataset에 대해 BERT를 finetune할때는 두 개의 prediction heads가 필요하다. Reference내에서 answer의 범위을 찾는다.
-
Predicting the Start Span
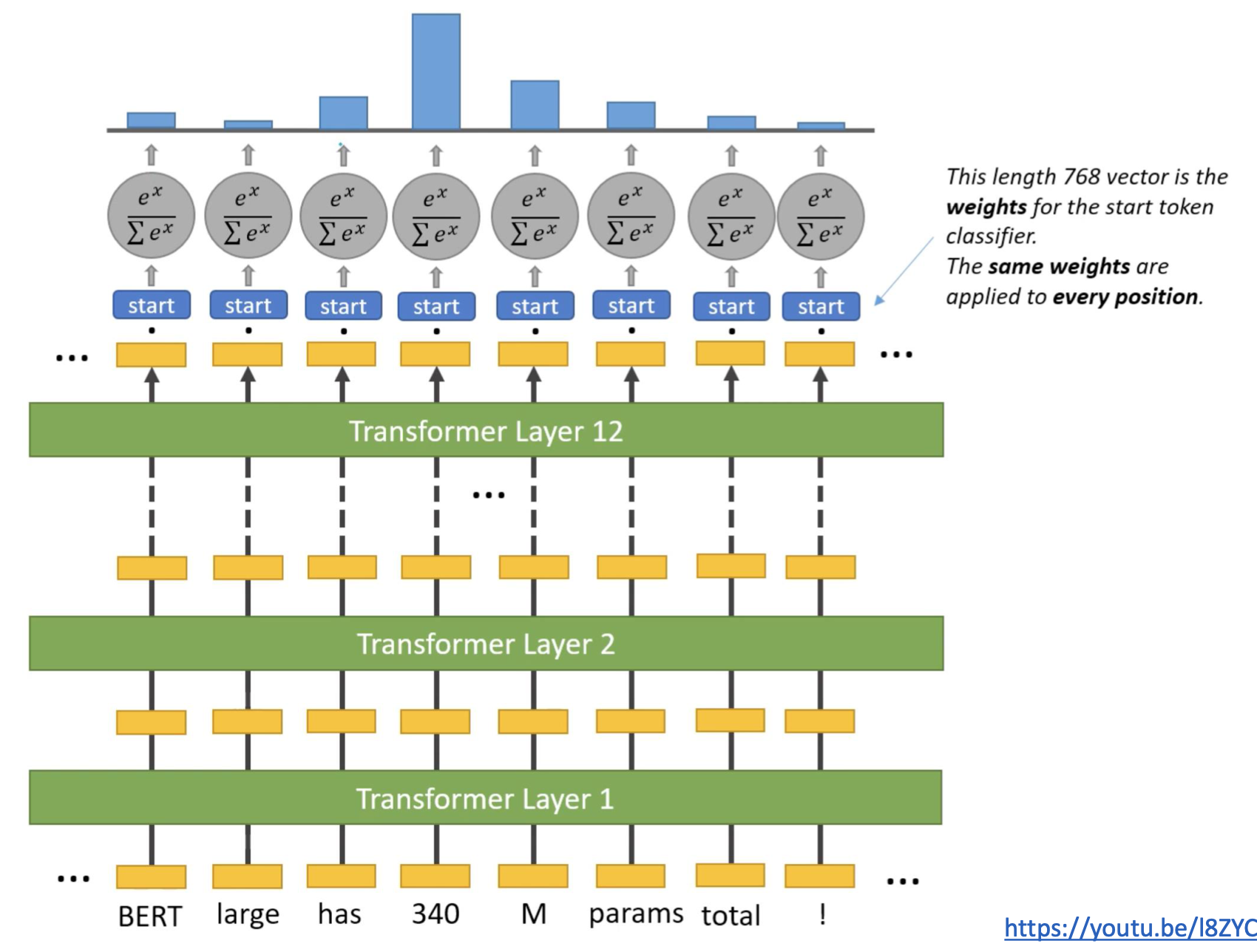
- 340에 해당하는 output token만 1을 predict하고 나머지는 0을 predict해야한다.
-
Predicting the End Span
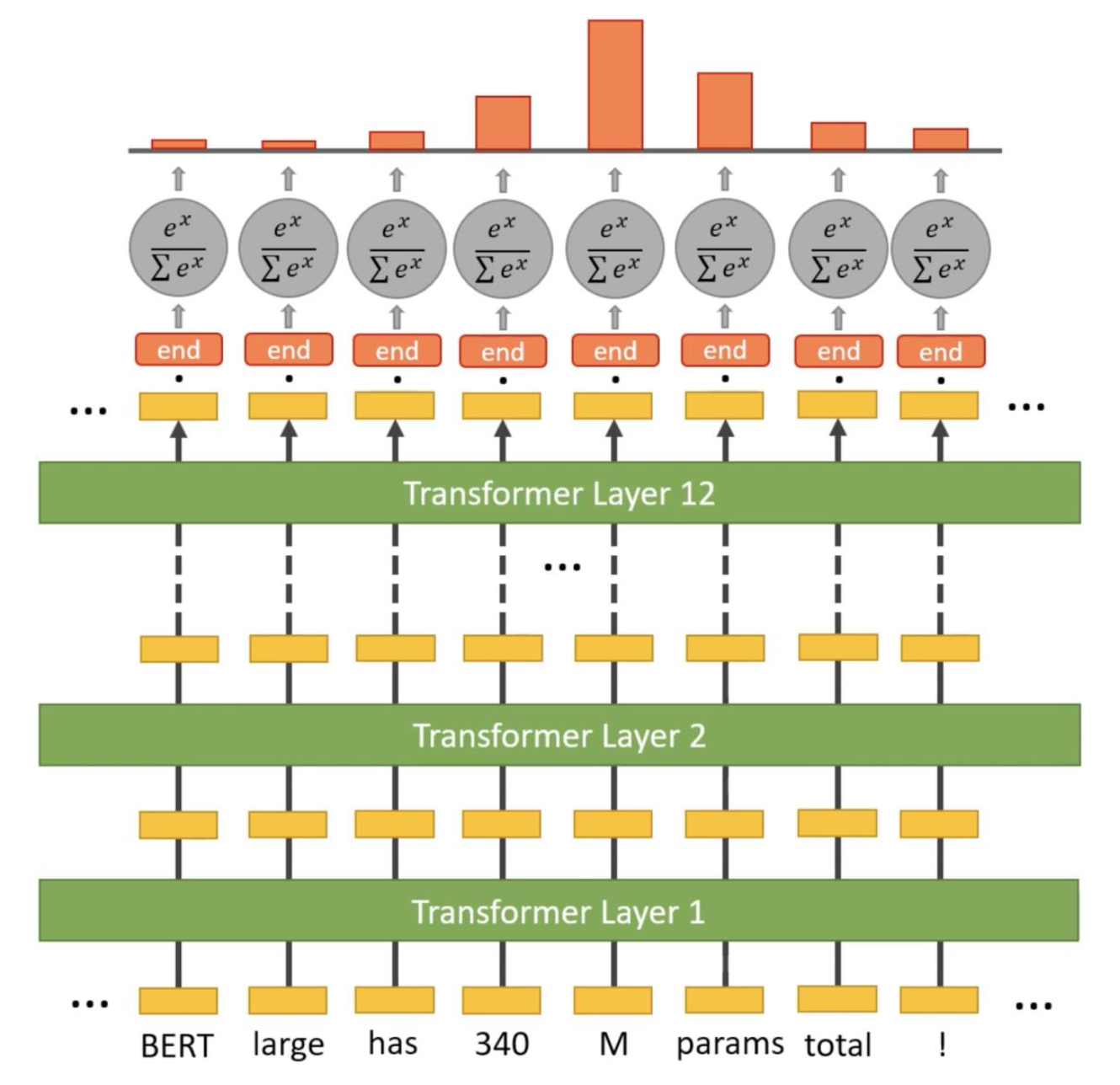
- M에 해당하는 output token만 1을 predict하고 나머지는 0을 predict해야한다.
-
GPT-2
- GPT-1보다 parameter가 10배 많다.
- Trained on WebText(perplexity 10~11)
Zero-shot tasks만 수행한다.- No-finetuning at all.
🔗 GPT-2 on Zero-shot Tasks
-
Prompt(textual input)을 사용하여 specific task에 대해 GPT-2를 condition한다.
- A few examples를 주고나면 model이 autoregressively sampling한다.
-
Languae modeling에 대해서는 매우 우수한 성능을 보이지만 다른 NLP tasks에서는 supervised model(SOTA)보다 우수하진 않은 경우도 있다.
GPT-3
- GPT-2보다 parameter가 100배 많다.
Zero-shot tasks만 수행한다.- No-finetuning at all.
- Gradient updates가 수행되지 않는다.
- GPT-2보다 전체적으로 성능이 좋다. Fine-tuned SOTA보다 성능이 좋은 경우가 있다.
🔗 GPT-3 Downstream Task Mode
- Zero-shot
- example을 하나도 보여주지 않는다.
- One-shot
- 하나의 example을 보여준다.
- Few-shot
- 여러 example을 보여준다.
🔗 The bigger, the better
- Average performance across 42 benchmark datasets
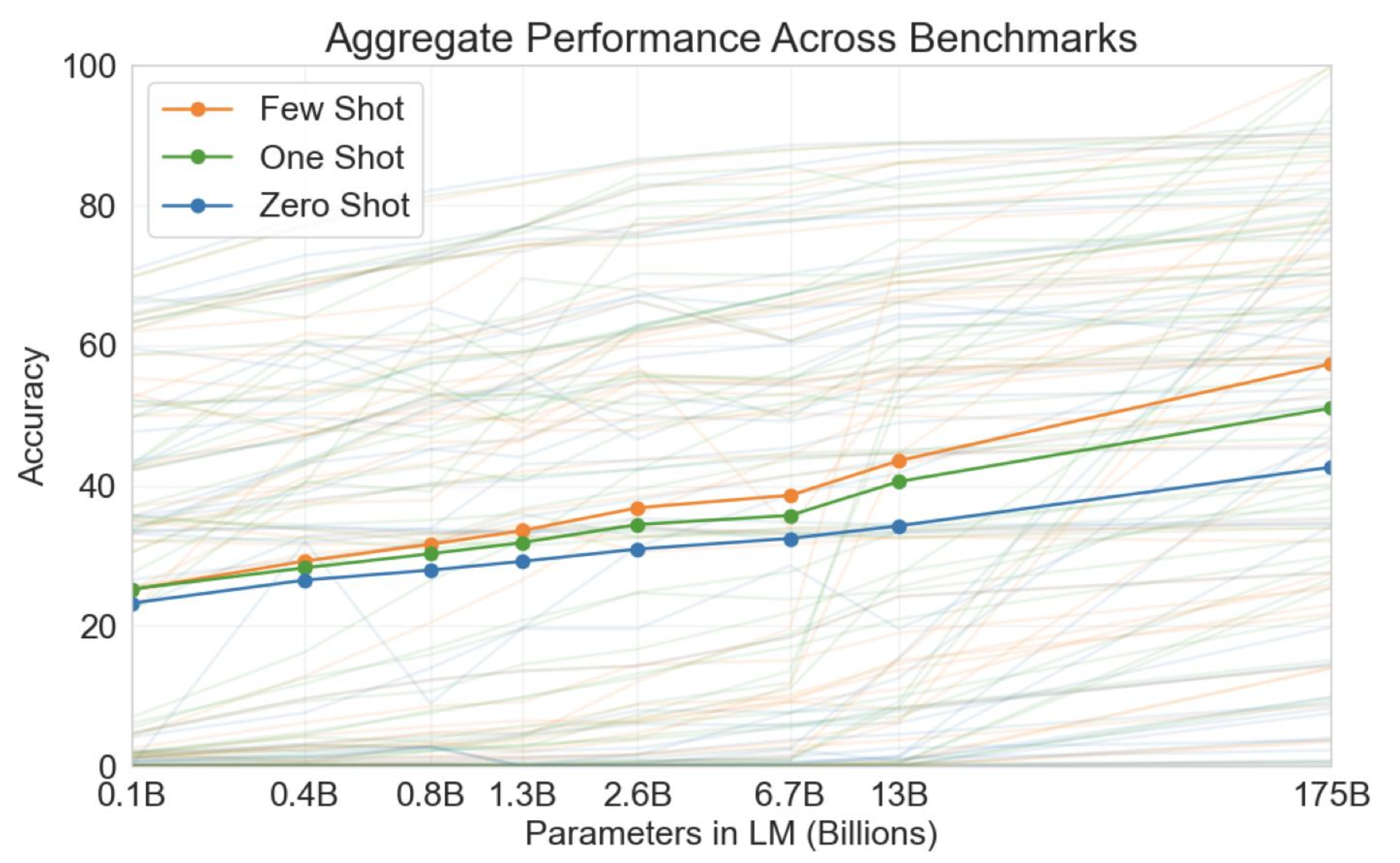
BLOOM
- 모두에게 opensource free Large Language Model을 제공하기 위해서 만들어졌다.
Reference
- AI504: Programming for AI Lecture at KAIST AI
