[AI 504] Programming for AI, Fall 2021
Practice 10: Transformers
[Notifications]
- If you have any questions, feel free to ask
- For additional questions, send emails: pacesun@kaist.ac.kr
Table of contents
Prepare essential packages
%matplotlib inline
!pip install torchtext==0.10.0
!git clone https://github.com/sjpark9503/attentionviz.git
!python -m spacy download de
!python -m spacy download enLooking in indexes: https://pypi.org/simple, https://us-python.pkg.dev/colab-wheels/public/simple/
Collecting torchtext==0.10.0
Downloading torchtext-0.10.0-cp39-cp39-manylinux1_x86_64.whl (7.6 MB)
[2K [90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━[0m [32m7.6/7.6 MB[0m [31m48.9 MB/s[0m eta [36m0:00:00[0m
[?25hCollecting torch==1.9.0
Downloading torch-1.9.0-cp39-cp39-manylinux1_x86_64.whl (831.4 MB)
[2K [90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━[0m [32m831.4/831.4 MB[0m [31m1.3 MB/s[0m eta [36m0:00:00[0m
[?25hRequirement already satisfied: requests in /usr/local/lib/python3.9/dist-packages (from torchtext==0.10.0) (2.27.1)
Requirement already satisfied: numpy in /usr/local/lib/python3.9/dist-packages (from torchtext==0.10.0) (1.22.4)
Requirement already satisfied: tqdm in /usr/local/lib/python3.9/dist-packages (from torchtext==0.10.0) (4.65.0)
Requirement already satisfied: typing-extensions in /usr/local/lib/python3.9/dist-packages (from torch==1.9.0->torchtext==0.10.0) (4.5.0)
Requirement already satisfied: charset-normalizer~=2.0.0 in /usr/local/lib/python3.9/dist-packages (from requests->torchtext==0.10.0) (2.0.12)
Requirement already satisfied: idna<4,>=2.5 in /usr/local/lib/python3.9/dist-packages (from requests->torchtext==0.10.0) (3.4)
Requirement already satisfied: certifi>=2017.4.17 in /usr/local/lib/python3.9/dist-packages (from requests->torchtext==0.10.0) (2022.12.7)
Requirement already satisfied: urllib3<1.27,>=1.21.1 in /usr/local/lib/python3.9/dist-packages (from requests->torchtext==0.10.0) (1.26.15)
Installing collected packages: torch, torchtext
Attempting uninstall: torch
Found existing installation: torch 1.13.1+cu116
Uninstalling torch-1.13.1+cu116:
Successfully uninstalled torch-1.13.1+cu116
Attempting uninstall: torchtext
Found existing installation: torchtext 0.14.1
Uninstalling torchtext-0.14.1:
Successfully uninstalled torchtext-0.14.1
[31mERROR: pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts.
torchvision 0.14.1+cu116 requires torch==1.13.1, but you have torch 1.9.0 which is incompatible.
torchaudio 0.13.1+cu116 requires torch==1.13.1, but you have torch 1.9.0 which is incompatible.[0m[31m
[0mSuccessfully installed torch-1.9.0 torchtext-0.10.0
Cloning into 'attentionviz'...
remote: Enumerating objects: 30, done.[K
remote: Counting objects: 100% (30/30), done.[K
remote: Compressing objects: 100% (24/24), done.[K
remote: Total 30 (delta 10), reused 19 (delta 4), pack-reused 0[K
Unpacking objects: 100% (30/30), 19.52 KiB | 2.44 MiB/s, done.
2023-03-25 03:27:35.622094: I tensorflow/core/platform/cpu_feature_guard.cc:193] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: AVX2 FMA
To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.
2023-03-25 03:27:39.190157: W tensorflow/compiler/xla/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libnvinfer.so.7'; dlerror: libnvinfer.so.7: cannot open shared object file: No such file or directory; LD_LIBRARY_PATH: /usr/lib64-nvidia
2023-03-25 03:27:39.190483: W tensorflow/compiler/xla/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libnvinfer_plugin.so.7'; dlerror: libnvinfer_plugin.so.7: cannot open shared object file: No such file or directory; LD_LIBRARY_PATH: /usr/lib64-nvidia
2023-03-25 03:27:39.190507: W tensorflow/compiler/tf2tensorrt/utils/py_utils.cc:38] TF-TRT Warning: Cannot dlopen some TensorRT libraries. If you would like to use Nvidia GPU with TensorRT, please make sure the missing libraries mentioned above are installed properly.
[38;5;3m⚠ As of spaCy v3.0, shortcuts like 'de' are deprecated. Please use the
full pipeline package name 'de_core_news_sm' instead.[0m
Looking in indexes: https://pypi.org/simple, https://us-python.pkg.dev/colab-wheels/public/simple/
Collecting de-core-news-sm==3.5.0
Downloading https://github.com/explosion/spacy-models/releases/download/de_core_news_sm-3.5.0/de_core_news_sm-3.5.0-py3-none-any.whl (14.6 MB)
[2K [90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━[0m [32m14.6/14.6 MB[0m [31m88.6 MB/s[0m eta [36m0:00:00[0m
[?25hRequirement already satisfied: spacy<3.6.0,>=3.5.0 in /usr/local/lib/python3.9/dist-packages (from de-core-news-sm==3.5.0) (3.5.1)
Requirement already satisfied: thinc<8.2.0,>=8.1.8 in /usr/local/lib/python3.9/dist-packages (from spacy<3.6.0,>=3.5.0->de-core-news-sm==3.5.0) (8.1.9)
Requirement already satisfied: spacy-loggers<2.0.0,>=1.0.0 in /usr/local/lib/python3.9/dist-packages (from spacy<3.6.0,>=3.5.0->de-core-news-sm==3.5.0) (1.0.4)
Requirement already satisfied: murmurhash<1.1.0,>=0.28.0 in /usr/local/lib/python3.9/dist-packages (from spacy<3.6.0,>=3.5.0->de-core-news-sm==3.5.0) (1.0.9)
Requirement already satisfied: numpy>=1.15.0 in /usr/local/lib/python3.9/dist-packages (from spacy<3.6.0,>=3.5.0->de-core-news-sm==3.5.0) (1.22.4)
Requirement already satisfied: cymem<2.1.0,>=2.0.2 in /usr/local/lib/python3.9/dist-packages (from spacy<3.6.0,>=3.5.0->de-core-news-sm==3.5.0) (2.0.7)
Requirement already satisfied: pathy>=0.10.0 in /usr/local/lib/python3.9/dist-packages (from spacy<3.6.0,>=3.5.0->de-core-news-sm==3.5.0) (0.10.1)
Requirement already satisfied: jinja2 in /usr/local/lib/python3.9/dist-packages (from spacy<3.6.0,>=3.5.0->de-core-news-sm==3.5.0) (3.1.2)
Requirement already satisfied: packaging>=20.0 in /usr/local/lib/python3.9/dist-packages (from spacy<3.6.0,>=3.5.0->de-core-news-sm==3.5.0) (23.0)
Requirement already satisfied: pydantic!=1.8,!=1.8.1,<1.11.0,>=1.7.4 in /usr/local/lib/python3.9/dist-packages (from spacy<3.6.0,>=3.5.0->de-core-news-sm==3.5.0) (1.10.7)
Requirement already satisfied: requests<3.0.0,>=2.13.0 in /usr/local/lib/python3.9/dist-packages (from spacy<3.6.0,>=3.5.0->de-core-news-sm==3.5.0) (2.27.1)
Requirement already satisfied: srsly<3.0.0,>=2.4.3 in /usr/local/lib/python3.9/dist-packages (from spacy<3.6.0,>=3.5.0->de-core-news-sm==3.5.0) (2.4.6)
Requirement already satisfied: langcodes<4.0.0,>=3.2.0 in /usr/local/lib/python3.9/dist-packages (from spacy<3.6.0,>=3.5.0->de-core-news-sm==3.5.0) (3.3.0)
Requirement already satisfied: preshed<3.1.0,>=3.0.2 in /usr/local/lib/python3.9/dist-packages (from spacy<3.6.0,>=3.5.0->de-core-news-sm==3.5.0) (3.0.8)
Requirement already satisfied: tqdm<5.0.0,>=4.38.0 in /usr/local/lib/python3.9/dist-packages (from spacy<3.6.0,>=3.5.0->de-core-news-sm==3.5.0) (4.65.0)
Requirement already satisfied: catalogue<2.1.0,>=2.0.6 in /usr/local/lib/python3.9/dist-packages (from spacy<3.6.0,>=3.5.0->de-core-news-sm==3.5.0) (2.0.8)
Requirement already satisfied: smart-open<7.0.0,>=5.2.1 in /usr/local/lib/python3.9/dist-packages (from spacy<3.6.0,>=3.5.0->de-core-news-sm==3.5.0) (6.3.0)
Requirement already satisfied: spacy-legacy<3.1.0,>=3.0.11 in /usr/local/lib/python3.9/dist-packages (from spacy<3.6.0,>=3.5.0->de-core-news-sm==3.5.0) (3.0.12)
Requirement already satisfied: setuptools in /usr/local/lib/python3.9/dist-packages (from spacy<3.6.0,>=3.5.0->de-core-news-sm==3.5.0) (67.6.0)
Requirement already satisfied: typer<0.8.0,>=0.3.0 in /usr/local/lib/python3.9/dist-packages (from spacy<3.6.0,>=3.5.0->de-core-news-sm==3.5.0) (0.7.0)
Requirement already satisfied: wasabi<1.2.0,>=0.9.1 in /usr/local/lib/python3.9/dist-packages (from spacy<3.6.0,>=3.5.0->de-core-news-sm==3.5.0) (1.1.1)
Requirement already satisfied: typing-extensions>=4.2.0 in /usr/local/lib/python3.9/dist-packages (from pydantic!=1.8,!=1.8.1,<1.11.0,>=1.7.4->spacy<3.6.0,>=3.5.0->de-core-news-sm==3.5.0) (4.5.0)
Requirement already satisfied: idna<4,>=2.5 in /usr/local/lib/python3.9/dist-packages (from requests<3.0.0,>=2.13.0->spacy<3.6.0,>=3.5.0->de-core-news-sm==3.5.0) (3.4)
Requirement already satisfied: certifi>=2017.4.17 in /usr/local/lib/python3.9/dist-packages (from requests<3.0.0,>=2.13.0->spacy<3.6.0,>=3.5.0->de-core-news-sm==3.5.0) (2022.12.7)
Requirement already satisfied: urllib3<1.27,>=1.21.1 in /usr/local/lib/python3.9/dist-packages (from requests<3.0.0,>=2.13.0->spacy<3.6.0,>=3.5.0->de-core-news-sm==3.5.0) (1.26.15)
Requirement already satisfied: charset-normalizer~=2.0.0 in /usr/local/lib/python3.9/dist-packages (from requests<3.0.0,>=2.13.0->spacy<3.6.0,>=3.5.0->de-core-news-sm==3.5.0) (2.0.12)
Requirement already satisfied: confection<1.0.0,>=0.0.1 in /usr/local/lib/python3.9/dist-packages (from thinc<8.2.0,>=8.1.8->spacy<3.6.0,>=3.5.0->de-core-news-sm==3.5.0) (0.0.4)
Requirement already satisfied: blis<0.8.0,>=0.7.8 in /usr/local/lib/python3.9/dist-packages (from thinc<8.2.0,>=8.1.8->spacy<3.6.0,>=3.5.0->de-core-news-sm==3.5.0) (0.7.9)
Requirement already satisfied: click<9.0.0,>=7.1.1 in /usr/local/lib/python3.9/dist-packages (from typer<0.8.0,>=0.3.0->spacy<3.6.0,>=3.5.0->de-core-news-sm==3.5.0) (8.1.3)
Requirement already satisfied: MarkupSafe>=2.0 in /usr/local/lib/python3.9/dist-packages (from jinja2->spacy<3.6.0,>=3.5.0->de-core-news-sm==3.5.0) (2.1.2)
Installing collected packages: de-core-news-sm
Successfully installed de-core-news-sm-3.5.0
[38;5;2m✔ Download and installation successful[0m
You can now load the package via spacy.load('de_core_news_sm')
2023-03-25 03:27:54.800492: I tensorflow/core/platform/cpu_feature_guard.cc:193] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: AVX2 FMA
To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.
2023-03-25 03:27:55.731377: W tensorflow/compiler/xla/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libnvinfer.so.7'; dlerror: libnvinfer.so.7: cannot open shared object file: No such file or directory; LD_LIBRARY_PATH: /usr/lib64-nvidia
2023-03-25 03:27:55.731494: W tensorflow/compiler/xla/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libnvinfer_plugin.so.7'; dlerror: libnvinfer_plugin.so.7: cannot open shared object file: No such file or directory; LD_LIBRARY_PATH: /usr/lib64-nvidia
2023-03-25 03:27:55.731513: W tensorflow/compiler/tf2tensorrt/utils/py_utils.cc:38] TF-TRT Warning: Cannot dlopen some TensorRT libraries. If you would like to use Nvidia GPU with TensorRT, please make sure the missing libraries mentioned above are installed properly.
[38;5;3m⚠ As of spaCy v3.0, shortcuts like 'en' are deprecated. Please use the
full pipeline package name 'en_core_web_sm' instead.[0m
Looking in indexes: https://pypi.org/simple, https://us-python.pkg.dev/colab-wheels/public/simple/
Collecting en-core-web-sm==3.5.0
Downloading https://github.com/explosion/spacy-models/releases/download/en_core_web_sm-3.5.0/en_core_web_sm-3.5.0-py3-none-any.whl (12.8 MB)
[2K [90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━[0m [32m12.8/12.8 MB[0m [31m92.2 MB/s[0m eta [36m0:00:00[0m
[?25hRequirement already satisfied: spacy<3.6.0,>=3.5.0 in /usr/local/lib/python3.9/dist-packages (from en-core-web-sm==3.5.0) (3.5.1)
Requirement already satisfied: catalogue<2.1.0,>=2.0.6 in /usr/local/lib/python3.9/dist-packages (from spacy<3.6.0,>=3.5.0->en-core-web-sm==3.5.0) (2.0.8)
Requirement already satisfied: setuptools in /usr/local/lib/python3.9/dist-packages (from spacy<3.6.0,>=3.5.0->en-core-web-sm==3.5.0) (67.6.0)
Requirement already satisfied: jinja2 in /usr/local/lib/python3.9/dist-packages (from spacy<3.6.0,>=3.5.0->en-core-web-sm==3.5.0) (3.1.2)
Requirement already satisfied: thinc<8.2.0,>=8.1.8 in /usr/local/lib/python3.9/dist-packages (from spacy<3.6.0,>=3.5.0->en-core-web-sm==3.5.0) (8.1.9)
Requirement already satisfied: numpy>=1.15.0 in /usr/local/lib/python3.9/dist-packages (from spacy<3.6.0,>=3.5.0->en-core-web-sm==3.5.0) (1.22.4)
Requirement already satisfied: murmurhash<1.1.0,>=0.28.0 in /usr/local/lib/python3.9/dist-packages (from spacy<3.6.0,>=3.5.0->en-core-web-sm==3.5.0) (1.0.9)
Requirement already satisfied: preshed<3.1.0,>=3.0.2 in /usr/local/lib/python3.9/dist-packages (from spacy<3.6.0,>=3.5.0->en-core-web-sm==3.5.0) (3.0.8)
Requirement already satisfied: spacy-legacy<3.1.0,>=3.0.11 in /usr/local/lib/python3.9/dist-packages (from spacy<3.6.0,>=3.5.0->en-core-web-sm==3.5.0) (3.0.12)
Requirement already satisfied: wasabi<1.2.0,>=0.9.1 in /usr/local/lib/python3.9/dist-packages (from spacy<3.6.0,>=3.5.0->en-core-web-sm==3.5.0) (1.1.1)
Requirement already satisfied: srsly<3.0.0,>=2.4.3 in /usr/local/lib/python3.9/dist-packages (from spacy<3.6.0,>=3.5.0->en-core-web-sm==3.5.0) (2.4.6)
Requirement already satisfied: requests<3.0.0,>=2.13.0 in /usr/local/lib/python3.9/dist-packages (from spacy<3.6.0,>=3.5.0->en-core-web-sm==3.5.0) (2.27.1)
Requirement already satisfied: spacy-loggers<2.0.0,>=1.0.0 in /usr/local/lib/python3.9/dist-packages (from spacy<3.6.0,>=3.5.0->en-core-web-sm==3.5.0) (1.0.4)
Requirement already satisfied: pydantic!=1.8,!=1.8.1,<1.11.0,>=1.7.4 in /usr/local/lib/python3.9/dist-packages (from spacy<3.6.0,>=3.5.0->en-core-web-sm==3.5.0) (1.10.7)
Requirement already satisfied: packaging>=20.0 in /usr/local/lib/python3.9/dist-packages (from spacy<3.6.0,>=3.5.0->en-core-web-sm==3.5.0) (23.0)
Requirement already satisfied: cymem<2.1.0,>=2.0.2 in /usr/local/lib/python3.9/dist-packages (from spacy<3.6.0,>=3.5.0->en-core-web-sm==3.5.0) (2.0.7)
Requirement already satisfied: smart-open<7.0.0,>=5.2.1 in /usr/local/lib/python3.9/dist-packages (from spacy<3.6.0,>=3.5.0->en-core-web-sm==3.5.0) (6.3.0)
Requirement already satisfied: typer<0.8.0,>=0.3.0 in /usr/local/lib/python3.9/dist-packages (from spacy<3.6.0,>=3.5.0->en-core-web-sm==3.5.0) (0.7.0)
Requirement already satisfied: pathy>=0.10.0 in /usr/local/lib/python3.9/dist-packages (from spacy<3.6.0,>=3.5.0->en-core-web-sm==3.5.0) (0.10.1)
Requirement already satisfied: tqdm<5.0.0,>=4.38.0 in /usr/local/lib/python3.9/dist-packages (from spacy<3.6.0,>=3.5.0->en-core-web-sm==3.5.0) (4.65.0)
Requirement already satisfied: langcodes<4.0.0,>=3.2.0 in /usr/local/lib/python3.9/dist-packages (from spacy<3.6.0,>=3.5.0->en-core-web-sm==3.5.0) (3.3.0)
Requirement already satisfied: typing-extensions>=4.2.0 in /usr/local/lib/python3.9/dist-packages (from pydantic!=1.8,!=1.8.1,<1.11.0,>=1.7.4->spacy<3.6.0,>=3.5.0->en-core-web-sm==3.5.0) (4.5.0)
Requirement already satisfied: certifi>=2017.4.17 in /usr/local/lib/python3.9/dist-packages (from requests<3.0.0,>=2.13.0->spacy<3.6.0,>=3.5.0->en-core-web-sm==3.5.0) (2022.12.7)
Requirement already satisfied: urllib3<1.27,>=1.21.1 in /usr/local/lib/python3.9/dist-packages (from requests<3.0.0,>=2.13.0->spacy<3.6.0,>=3.5.0->en-core-web-sm==3.5.0) (1.26.15)
Requirement already satisfied: idna<4,>=2.5 in /usr/local/lib/python3.9/dist-packages (from requests<3.0.0,>=2.13.0->spacy<3.6.0,>=3.5.0->en-core-web-sm==3.5.0) (3.4)
Requirement already satisfied: charset-normalizer~=2.0.0 in /usr/local/lib/python3.9/dist-packages (from requests<3.0.0,>=2.13.0->spacy<3.6.0,>=3.5.0->en-core-web-sm==3.5.0) (2.0.12)
Requirement already satisfied: confection<1.0.0,>=0.0.1 in /usr/local/lib/python3.9/dist-packages (from thinc<8.2.0,>=8.1.8->spacy<3.6.0,>=3.5.0->en-core-web-sm==3.5.0) (0.0.4)
Requirement already satisfied: blis<0.8.0,>=0.7.8 in /usr/local/lib/python3.9/dist-packages (from thinc<8.2.0,>=8.1.8->spacy<3.6.0,>=3.5.0->en-core-web-sm==3.5.0) (0.7.9)
Requirement already satisfied: click<9.0.0,>=7.1.1 in /usr/local/lib/python3.9/dist-packages (from typer<0.8.0,>=0.3.0->spacy<3.6.0,>=3.5.0->en-core-web-sm==3.5.0) (8.1.3)
Requirement already satisfied: MarkupSafe>=2.0 in /usr/local/lib/python3.9/dist-packages (from jinja2->spacy<3.6.0,>=3.5.0->en-core-web-sm==3.5.0) (2.1.2)
[38;5;2m✔ Download and installation successful[0m
You can now load the package via spacy.load('en_core_web_sm')I. Prepare input
We've already learned how to preprocess the text data in previous lectures.
You can see some detailed explanation about translation datasets in torchtext, practice session,week 9 and PyTorch NMT tutorial
import torch
from torchtext.legacy.datasets import Multi30k
from torchtext.legacy.data import Field, BucketIterator
## Multi30K is a dataset to stimulate multilingual multimodal research
## for English-German translation. In the class, We only consider text dataset
## for translation by using transformer German to English translation.
## Define Field class for source sentence
## In the translation, moses-tokenizer and spacy can be used.
## In the class, we use spacy tokenizer
SRC = Field(tokenize = "spacy",
tokenizer_language="de", # German
init_token = '<sos>', # start stoken
eos_token = '<eos>', # end token
batch_first=True, # (batch_size, seq_len, features)
lower = True)
TRG = Field(tokenize = "spacy",
tokenizer_language="en", # English
init_token = '<sos>',
eos_token = '<eos>',
batch_first=True,
lower = True)
train_data, valid_data, test_data = Multi30k.splits(exts = ('.de', '.en'),
fields = (SRC, TRG))
## Get vocabulary when word frequency >= 2
SRC.build_vocab(train_data, min_freq = 2)
TRG.build_vocab(train_data, min_freq = 2)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
BATCH_SIZE = 128
## Dataloader
train_iterator, valid_iterator, test_iterator = BucketIterator.splits(
(train_data, valid_data, test_data),
batch_size = BATCH_SIZE,
device = device,
shuffle=True)/usr/local/lib/python3.9/dist-packages/torchtext/data/utils.py:123: UserWarning: Spacy model "de" could not be loaded, trying "de_core_news_sm" instead
warnings.warn(f'Spacy model "{language}" could not be loaded, trying "{OLD_MODEL_SHORTCUTS[language]}" instead')
/usr/local/lib/python3.9/dist-packages/torchtext/data/utils.py:123: UserWarning: Spacy model "en" could not be loaded, trying "en_core_web_sm" instead
warnings.warn(f'Spacy model "{language}" could not be loaded, trying "{OLD_MODEL_SHORTCUTS[language]}" instead')
downloading training.tar.gz
training.tar.gz: 100%|██████████| 1.21M/1.21M [00:01<00:00, 813kB/s]
downloading validation.tar.gz
validation.tar.gz: 100%|██████████| 46.3k/46.3k [00:00<00:00, 234kB/s]
downloading mmt_task1_test2016.tar.gz
mmt_task1_test2016.tar.gz: 100%|██████████| 66.2k/66.2k [00:00<00:00, 225kB/s]II. Implement Transformer
In practice 10, we will learn how to implement the Attention is all you need (Vaswani et al., 2017)
The overall architecutre is as follows:
1. Basic building blocks
In this sections, we will build blocks of the transformer: Multi-head attention, Position wise feedforward network and Positional encoding
a. Attention
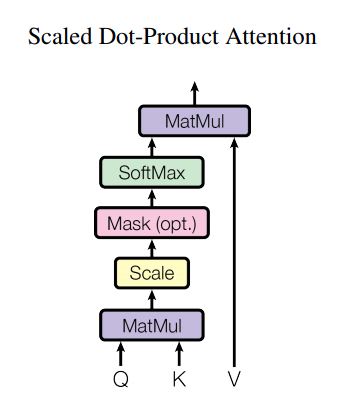
In this section, you will implement scaled dot-product attention and multi-head attention.
Scaled dot product:
Multi-head attention:
![]()
- Equation:\begin{align} \text{MultiHead}(Q, K, V) &= \text{Concat}(head_1, ...., head_h) W^O \\ \text{where head}_i &= \text{Attention} \left( QW^Q_i, K W^K_i, VW^v_i \right) \end{align}
Query, Key and Value projection:

import torch
import torch.nn as nn
import torch.nn.functional as F
import time
class MultiHeadAttention(nn.Module):
"""Multi-headed attention from 'Attention Is All You Need' paper"""
def __init__(
self,
emb_dim,
num_heads,
dropout=0.0,
bias=False,
encoder_decoder_attention=False, # otherwise self_attention
causal = False
):
super().__init__()
self.emb_dim = emb_dim
self.num_heads = num_heads
self.dropout = dropout
self.head_dim = emb_dim // num_heads
assert self.head_dim * num_heads == self.emb_dim, "emb_dim must be divisible by num_heads"
self.encoder_decoder_attention = encoder_decoder_attention
self.causal = causal
self.q_proj = nn.Linear(emb_dim, emb_dim, bias=bias)
self.k_proj = nn.Linear(emb_dim, emb_dim, bias=bias)
self.v_proj = nn.Linear(emb_dim, emb_dim, bias=bias)
self.out_proj = nn.Linear(emb_dim, emb_dim, bias=bias)
def transpose_for_scores(self, x):
new_x_shape = x.size()[:-1] + (
self.num_heads,
self.head_dim,
)
x = x.view(*new_x_shape)
return x.permute(0, 2, 1, 3)
# This is equivalent to
# return x.transpose(1,2)
def scaled_dot_product(self,
query: torch.Tensor,
key: torch.Tensor,
value: torch.Tensor,
attention_mask: torch.BoolTensor):
attn_weights = torch.matmul(query, key.transpose(-1, -2)) / math.sqrt(self.emb_dim) # QK^T/sqrt(d)
if attention_mask is not None:
attn_weights = attn_weights.masked_fill(attention_mask.unsqueeze(1), float("-inf"))
attn_weights = F.softmax(attn_weights, dim=-1) # softmax(QK^T/sqrt(d))
attn_probs = F.dropout(attn_weights, p=self.dropout, training=self.training)
attn_output = torch.matmul(attn_probs, value) # softmax(QK^T/sqrt(d))V
return attn_output, attn_probs
def MultiHead_scaled_dot_product(self,
query: torch.Tensor,
key: torch.Tensor,
value: torch.Tensor,
attention_mask: torch.BoolTensor):
attn_weights = torch.matmul(query, key.transpose(-1, -2)) / math.sqrt(self.head_dim) # QK^T/sqrt(d)
# Attention mask
if attention_mask is not None:
if self.causal:
# (seq_len x seq_len)
attn_weights = attn_weights.masked_fill(attention_mask.unsqueeze(0).unsqueeze(1), float("-inf"))
else:
# (batch_size x seq_len)
attn_weights = attn_weights.masked_fill(attention_mask.unsqueeze(1).unsqueeze(2), float("-inf"))
attn_weights = F.softmax(attn_weights, dim=-1) # softmax(QK^T/sqrt(d))
attn_probs = F.dropout(attn_weights, p=self.dropout, training=self.training)
attn_output = torch.matmul(attn_probs, value) # softmax(QK^T/sqrt(d))V
attn_output = attn_output.permute(0, 2, 1, 3).contiguous()
concat_attn_output_shape = attn_output.size()[:-2] + (self.emb_dim,)
attn_output = attn_output.view(*concat_attn_output_shape)
attn_output = self.out_proj(attn_output)
return attn_output, attn_weights
def forward(
self,
query: torch.Tensor,
key: torch.Tensor,
attention_mask: torch.Tensor = None,
):
q = self.q_proj(query)
# Enc-Dec attention
if self.encoder_decoder_attention:
k = self.k_proj(key)
v = self.v_proj(key)
# Self attention
else:
k = self.k_proj(query)
v = self.v_proj(query)
q = self.transpose_for_scores(q)
k = self.transpose_for_scores(k)
v = self.transpose_for_scores(v)
attn_output, attn_weights = self.MultiHead_scaled_dot_product(q,k,v,attention_mask)
return attn_output, attn_weights
b. Position-wise feed-forward network
In this section, we will implement position-wise feed forward network
class PositionWiseFeedForward(nn.Module):
def __init__(self, emb_dim: int, d_ff: int, dropout: float = 0.1):
super(PositionWiseFeedForward, self).__init__()
self.activation = nn.ReLU()
self.w_1 = nn.Linear(emb_dim, d_ff)
self.w_2 = nn.Linear(d_ff, emb_dim)
self.dropout = dropout
def forward(self, x):
residual = x
x = self.activation(self.w_1(x))
x = F.dropout(x, p=self.dropout, training=self.training)
x = self.w_2(x)
x = F.dropout(x, p=self.dropout, training=self.training)
return x + residual # residual connection for preventing gradient vanishingc. Sinusoidal Positional Encoding
In this section, we will implement sinusoidal positional encoding
import numpy as np
# Since Transformer contains no recurrence and no convolution,
# in order for the model to make use of the order of the sequence,
# we must inject some information about the relative or absolute position of the tokens in the sequence.
# To this end, we add “positional encodings” to the input embeddings at the bottoms of the encoder and decoder stacks.
# There are many choices of positional encodings, learned and fixed
class SinusoidalPositionalEmbedding(nn.Embedding):
def __init__(self, num_positions, embedding_dim, padding_idx=None):
super().__init__(num_positions, embedding_dim) # torch.nn.Embedding(num_embeddings, embedding_dim)
self.weight = self._init_weight(self.weight) # self.weight => nn.Embedding(num_positions, embedding_dim).weight
@staticmethod
def _init_weight(out: nn.Parameter):
n_pos, embed_dim = out.shape
pe = nn.Parameter(torch.zeros(out.shape))
for pos in range(n_pos):
for i in range(0, embed_dim, 2):
pe[pos, i].data.copy_( torch.tensor( np.sin(pos / (10000 ** ( i / embed_dim)))) )
pe[pos, i + 1].data.copy_( torch.tensor( np.cos(pos / (10000 ** ((i + 1) / embed_dim)))) )
pe.detach_()
return pe
@torch.no_grad()
def forward(self, input_ids):
bsz, seq_len = input_ids.shape[:2]
positions = torch.arange(seq_len, dtype=torch.long, device=self.weight.device)
return super().forward(positions)
2. Transformer Encoder
Now we have all basic building blocks which are essential to build Transformer.
Let's implement Transformer step-by-step
a. Encoder layer
In this section, we will implement single layer of Transformer encoder.
class EncoderLayer(nn.Module):
def __init__(self, config):
super().__init__()
self.emb_dim = config.emb_dim
self.ffn_dim = config.ffn_dim
self.self_attn = MultiHeadAttention(
emb_dim=self.emb_dim,
num_heads=config.attention_heads,
dropout=config.attention_dropout)
self.self_attn_layer_norm = nn.LayerNorm(self.emb_dim)
self.dropout = config.dropout
self.activation_fn = nn.ReLU()
self.PositionWiseFeedForward = PositionWiseFeedForward(self.emb_dim, self.ffn_dim, config.dropout)
self.final_layer_norm = nn.LayerNorm(self.emb_dim)
def forward(self, x, encoder_padding_mask):
residual = x
x, attn_weights = self.self_attn(query=x, key=x, attention_mask=encoder_padding_mask)
x = F.dropout(x, p=self.dropout, training=self.training)
x = residual + x
x = self.self_attn_layer_norm(x)
x = self.PositionWiseFeedForward(x)
x = self.final_layer_norm(x)
if torch.isinf(x).any() or torch.isnan(x).any():
clamp_value = torch.finfo(x.dtype).max - 1000
x = torch.clamp(x, min=-clamp_value, max=clamp_value)
return x, attn_weights
b. Encoder
Stack encoder layers and build full Transformer encoder
class Encoder(nn.Module):
def __init__(self, config, embed_tokens):
super().__init__()
self.dropout = config.dropout
emb_dim = embed_tokens.embedding_dim
self.padding_idx = embed_tokens.padding_idx
self.max_source_positions = config.max_position_embeddings
self.embed_tokens = embed_tokens
self.embed_positions = SinusoidalPositionalEmbedding(
config.max_position_embeddings, config.emb_dim, self.padding_idx
)
self.layers = nn.ModuleList([EncoderLayer(config) for _ in range(config.encoder_layers)])
def forward(self, input_ids, attention_mask=None):
inputs_embeds = self.embed_tokens(input_ids)
embed_pos = self.embed_positions(input_ids)
x = inputs_embeds + embed_pos
x = F.dropout(x, p=self.dropout, training=self.training)
self_attn_scores = []
for encoder_layer in self.layers:
x, attn = encoder_layer(x, attention_mask)
self_attn_scores.append(attn.detach())
return x, self_attn_scores
3. Transformer Decoder
a.Decoder layer
In this section, we will implement single layer of Transformer decoder.
class DecoderLayer(nn.Module):
def __init__(self, config):
super().__init__()
self.emb_dim = config.emb_dim
self.ffn_dim = config.ffn_dim
self.self_attn = MultiHeadAttention(
emb_dim=self.emb_dim,
num_heads=config.attention_heads,
dropout=config.attention_dropout,
causal=True,
)
self.dropout = config.dropout
self.self_attn_layer_norm = nn.LayerNorm(self.emb_dim)
self.encoder_attn = MultiHeadAttention(
emb_dim=self.emb_dim,
num_heads=config.attention_heads,
dropout=config.attention_dropout,
encoder_decoder_attention=True,
)
self.encoder_attn_layer_norm = nn.LayerNorm(self.emb_dim)
self.PositionWiseFeedForward = PositionWiseFeedForward(self.emb_dim, self.ffn_dim, config.dropout)
self.final_layer_norm = nn.LayerNorm(self.emb_dim)
def forward(
self,
x,
encoder_hidden_states,
encoder_attention_mask=None,
causal_mask=None,
):
residual = x
# Self Attention
x, self_attn_weights = self.self_attn(
query=x,
key=x, # adds keys to layer state
attention_mask=causal_mask,
)
x = F.dropout(x, p=self.dropout, training=self.training)
x = residual + x
x = self.self_attn_layer_norm(x)
# Cross-Attention Block
residual = x
x, cross_attn_weights = self.encoder_attn(
query=x,
key=encoder_hidden_states,
attention_mask=encoder_attention_mask,
)
x = F.dropout(x, p=self.dropout, training=self.training)
x = residual + x
x = self.encoder_attn_layer_norm(x)
# Fully Connected
x = self.PositionWiseFeedForward(x)
x = self.final_layer_norm(x)
return (
x,
self_attn_weights,
cross_attn_weights,
) b. Decoder
Stack decoder layers and build full Transformer decoder.
Unlike the encoder, you need to do one more job: pass the causal(unidirectional) mask to the decoder self attention layer
class Decoder(nn.Module):
def __init__(self, config, embed_tokens: nn.Embedding):
super().__init__()
self.dropout = config.dropout
self.padding_idx = embed_tokens.padding_idx
self.max_target_positions = config.max_position_embeddings
self.embed_tokens = embed_tokens
self.embed_positions = SinusoidalPositionalEmbedding(
config.max_position_embeddings, config.emb_dim, self.padding_idx
)
self.layers = nn.ModuleList([DecoderLayer(config) for _ in range(config.decoder_layers)]) # type: List[DecoderLayer]
def forward(
self,
input_ids,
encoder_hidden_states,
encoder_attention_mask,
decoder_causal_mask,
):
# embed positions
positions = self.embed_positions(input_ids)
x = self.embed_tokens(input_ids)
x += positions
x = F.dropout(x, p=self.dropout, training=self.training)
# decoder layers
cross_attention_scores = []
for idx, decoder_layer in enumerate(self.layers):
x, layer_self_attn, layer_cross_attn = decoder_layer(
x,
encoder_hidden_states,
encoder_attention_mask=encoder_attention_mask,
causal_mask=decoder_causal_mask,
)
cross_attention_scores.append(layer_cross_attn.detach())
return x, cross_attention_scores4. Transformer
Let's combine encoder and decoder in one place!
class Transformer(nn.Module):
def __init__(self, SRC,TRG,config):
super().__init__()
self.SRC = SRC
self.TRG = TRG
self.enc_embedding = nn.Embedding(len(SRC.vocab), config.emb_dim, padding_idx=SRC.vocab.stoi['<pad>'])
self.dec_embedding = nn.Embedding(len(TRG.vocab), config.emb_dim, padding_idx=TRG.vocab.stoi['<pad>'])
self.encoder = Encoder(config, self.enc_embedding)
self.decoder = Decoder(config, self.dec_embedding)
self.prediction_head = nn.Linear(config.emb_dim,len(TRG.vocab))
self.init_weights()
def generate_mask(self, src, trg):
# Mask encoder attention to ignore padding
enc_attention_mask = src.eq(SRC.vocab.stoi['<pad>']).to(device) # torch.Size([128, 25])
# Mask decoder attention for causality
tmp = torch.ones(trg.size(1), trg.size(1), dtype=torch.bool) # torch.Size([28, 28])
mask = torch.arange(tmp.size(-1)) # torch.Size([28])
dec_attention_mask = tmp.masked_fill_(mask < (mask + 1).view(tmp.size(-1), 1), False).to(device) # torch.Size([28, 28])
return enc_attention_mask, dec_attention_mask
def init_weights(self):
for name, param in self.named_parameters():
if param.requires_grad:
if 'weight' in name:
nn.init.normal_(param.data, mean=0, std=0.01) # weight initialization by normal dist
else:
nn.init.constant_(param.data, 0)
def forward(
self,
src,
trg,
):
enc_attention_mask, dec_causal_mask = self.generate_mask(src, trg)
encoder_output, encoder_attention_scores = self.encoder(
input_ids=src,
attention_mask=enc_attention_mask
)
# decoder outputs consists of (dec_features, layer_state, dec_hidden, dec_attn)
decoder_output, decoder_attention_scores = self.decoder(
trg,
encoder_output,
encoder_attention_mask=enc_attention_mask,
decoder_causal_mask=dec_causal_mask,
)
decoder_output = self.prediction_head(decoder_output)
return decoder_output, encoder_attention_scores, decoder_attention_scoresIII. Train & Evaluate
This section is very similar to week 9, so please refer to it for detailed description.
1. Configuration
import easydict
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
config = easydict.EasyDict({
"emb_dim":64,
"ffn_dim":256,
"attention_heads":4,
"attention_dropout":0.0,
"dropout":0.2,
"max_position_embeddings":512,
"encoder_layers":3,
"decoder_layers":3,
})
N_EPOCHS = 100
learning_rate = 5e-4
CLIP = 1
PAD_IDX = TRG.vocab.stoi['<pad>']
model = Transformer(SRC,TRG,config)
model.to(device)
optimizer = optim.Adam(model.parameters(),lr=learning_rate)
criterion = nn.CrossEntropyLoss(ignore_index=PAD_IDX)
best_valid_loss = float('inf')2. Train & Eval
import math
import time
from tqdm import tqdm
def train(model: nn.Module,
iterator: BucketIterator,
optimizer: optim.Optimizer,
criterion: nn.Module,
clip: float):
model.train()
epoch_loss = 0
for idx, batch in enumerate(iterator):
src = batch.src
trg = batch.trg
optimizer.zero_grad()
output, enc_attention_scores, _ = model(src, trg)
output = output[:,:-1,:].reshape(-1, output.shape[-1])
trg = trg[:,1:].reshape(-1)
loss = criterion(output, trg)
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), clip)
optimizer.step()
epoch_loss += loss.item()
return epoch_loss / len(iterator)
def evaluate(model: nn.Module,
iterator: BucketIterator,
criterion: nn.Module):
model.eval()
epoch_loss = 0
with torch.no_grad():
for _, batch in enumerate(iterator):
src = batch.src
trg = batch.trg
output, attention_score, _ = model(src, trg) #turn off teacher forcing
output = output[:,:-1,:].reshape(-1, output.shape[-1])
trg = trg[:,1:].reshape(-1)
loss = criterion(output, trg)
epoch_loss += loss.item()
return epoch_loss / len(iterator)
for epoch in tqdm(range(N_EPOCHS), total=N_EPOCHS):
train_loss = train(model, train_iterator, optimizer, criterion, CLIP)
valid_loss = evaluate(model, valid_iterator, criterion)
if best_valid_loss < valid_loss: # early stopping
break
else:
best_valid_loss = valid_loss
print(f'\tTrain Loss: {train_loss:.3f} | Train PPL: {math.exp(train_loss):7.3f}')
print(f'\t Val. Loss: {valid_loss:.3f} | Val. PPL: {math.exp(valid_loss):7.3f}')
test_loss = evaluate(model, test_iterator, criterion)
print(f'| Test Loss: {test_loss:.3f} | Test PPL: {math.exp(test_loss):7.3f} |') 1%| | 1/100 [00:11<19:31, 11.84s/it]
Train Loss: 7.467 | Train PPL: 1749.993
Val. Loss: 5.708 | Val. PPL: 301.393
2%|▏ | 2/100 [00:20<16:29, 10.10s/it]
Train Loss: 5.400 | Train PPL: 221.449
Val. Loss: 5.170 | Val. PPL: 175.872
3%|▎ | 3/100 [00:30<15:46, 9.76s/it]
Train Loss: 5.136 | Train PPL: 169.996
Val. Loss: 4.893 | Val. PPL: 133.411
4%|▍ | 4/100 [00:39<15:23, 9.62s/it]
Train Loss: 4.820 | Train PPL: 123.958
Val. Loss: 4.552 | Val. PPL: 94.835
5%|▌ | 5/100 [00:48<14:47, 9.34s/it]
Train Loss: 4.524 | Train PPL: 92.222
Val. Loss: 4.302 | Val. PPL: 73.822
6%|▌ | 6/100 [00:57<14:41, 9.38s/it]
Train Loss: 4.318 | Train PPL: 75.029
Val. Loss: 4.126 | Val. PPL: 61.904
7%|▋ | 7/100 [01:07<14:54, 9.62s/it]
Train Loss: 4.178 | Train PPL: 65.251
Val. Loss: 4.013 | Val. PPL: 55.295
8%|▊ | 8/100 [01:17<14:32, 9.49s/it]
Train Loss: 4.077 | Train PPL: 58.952
Val. Loss: 3.913 | Val. PPL: 50.042
9%|▉ | 9/100 [01:26<14:12, 9.36s/it]
Train Loss: 3.990 | Train PPL: 54.079
Val. Loss: 3.859 | Val. PPL: 47.428
10%|█ | 10/100 [01:35<14:06, 9.40s/it]
Train Loss: 3.919 | Train PPL: 50.341
Val. Loss: 3.771 | Val. PPL: 43.432
11%|█ | 11/100 [01:45<13:58, 9.42s/it]
Train Loss: 3.852 | Train PPL: 47.073
Val. Loss: 3.702 | Val. PPL: 40.534
12%|█▏ | 12/100 [01:53<13:33, 9.25s/it]
Train Loss: 3.785 | Train PPL: 44.031
Val. Loss: 3.635 | Val. PPL: 37.920
13%|█▎ | 13/100 [02:03<13:30, 9.31s/it]
Train Loss: 3.727 | Train PPL: 41.536
Val. Loss: 3.586 | Val. PPL: 36.078
14%|█▍ | 14/100 [02:12<13:24, 9.36s/it]
Train Loss: 3.677 | Train PPL: 39.544
Val. Loss: 3.541 | Val. PPL: 34.500
15%|█▌ | 15/100 [02:21<13:07, 9.27s/it]
Train Loss: 3.633 | Train PPL: 37.842
Val. Loss: 3.507 | Val. PPL: 33.352
16%|█▌ | 16/100 [02:31<13:15, 9.48s/it]
Train Loss: 3.592 | Train PPL: 36.321
Val. Loss: 3.464 | Val. PPL: 31.939
17%|█▋ | 17/100 [02:41<13:05, 9.46s/it]
Train Loss: 3.556 | Train PPL: 35.018
Val. Loss: 3.451 | Val. PPL: 31.520
18%|█▊ | 18/100 [02:50<12:54, 9.45s/it]
Train Loss: 3.522 | Train PPL: 33.857
Val. Loss: 3.406 | Val. PPL: 30.154
18%|█▊ | 18/100 [02:59<13:38, 9.98s/it]
| Test Loss: 3.407 | Test PPL: 30.166 |IV. Visualization
1. Positional embedding visualization
import matplotlib.pyplot as plt
# Visualization
fig, ax = plt.subplots(figsize=(15, 9))
cax = ax.matshow(model.encoder.embed_positions.weight.data.cpu().numpy(), aspect='auto',cmap=plt.cm.YlOrRd)
fig.colorbar(cax)
ax.set_title('Positional Embedding Matrix', fontsize=18)
ax.set_xlabel('Embedding Dimension', fontsize=14)
ax.set_ylabel('Sequence Length', fontsize=14)Text(0, 0.5, 'Sequence Length')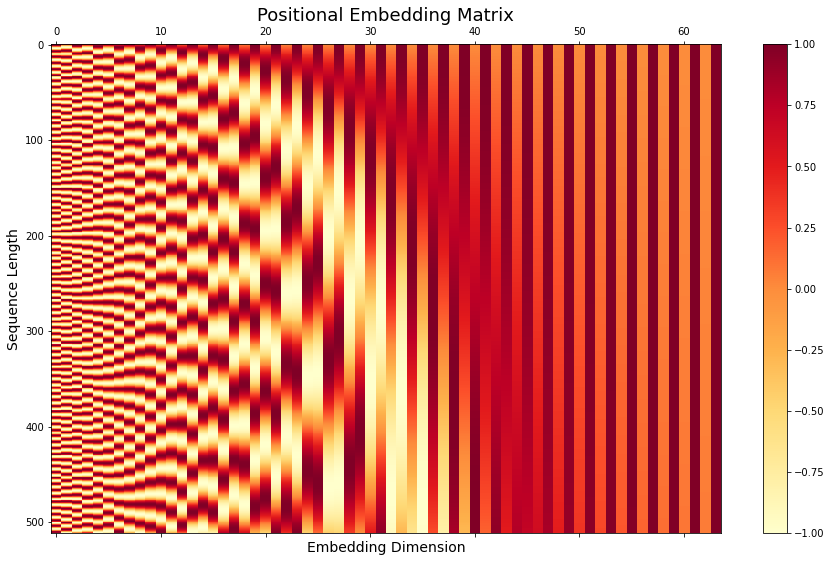
2. Attention visualization
from attentionviz import head_view
BATCH_SIZE = 1
train_iterator, _, test_iterator = BucketIterator.splits(
(train_data, valid_data, test_data),
batch_size = BATCH_SIZE,
device = device)
model.eval()Transformer(
(enc_embedding): Embedding(7853, 64, padding_idx=1)
(dec_embedding): Embedding(5893, 64, padding_idx=1)
(encoder): Encoder(
(embed_tokens): Embedding(7853, 64, padding_idx=1)
(embed_positions): SinusoidalPositionalEmbedding(512, 64)
(layers): ModuleList(
(0): EncoderLayer(
(self_attn): MultiHeadAttention(
(q_proj): Linear(in_features=64, out_features=64, bias=False)
(k_proj): Linear(in_features=64, out_features=64, bias=False)
(v_proj): Linear(in_features=64, out_features=64, bias=False)
(out_proj): Linear(in_features=64, out_features=64, bias=False)
)
(self_attn_layer_norm): LayerNorm((64,), eps=1e-05, elementwise_affine=True)
(activation_fn): ReLU()
(PositionWiseFeedForward): PositionWiseFeedForward(
(activation): ReLU()
(w_1): Linear(in_features=64, out_features=256, bias=True)
(w_2): Linear(in_features=256, out_features=64, bias=True)
)
(final_layer_norm): LayerNorm((64,), eps=1e-05, elementwise_affine=True)
)
(1): EncoderLayer(
(self_attn): MultiHeadAttention(
(q_proj): Linear(in_features=64, out_features=64, bias=False)
(k_proj): Linear(in_features=64, out_features=64, bias=False)
(v_proj): Linear(in_features=64, out_features=64, bias=False)
(out_proj): Linear(in_features=64, out_features=64, bias=False)
)
(self_attn_layer_norm): LayerNorm((64,), eps=1e-05, elementwise_affine=True)
(activation_fn): ReLU()
(PositionWiseFeedForward): PositionWiseFeedForward(
(activation): ReLU()
(w_1): Linear(in_features=64, out_features=256, bias=True)
(w_2): Linear(in_features=256, out_features=64, bias=True)
)
(final_layer_norm): LayerNorm((64,), eps=1e-05, elementwise_affine=True)
)
(2): EncoderLayer(
(self_attn): MultiHeadAttention(
(q_proj): Linear(in_features=64, out_features=64, bias=False)
(k_proj): Linear(in_features=64, out_features=64, bias=False)
(v_proj): Linear(in_features=64, out_features=64, bias=False)
(out_proj): Linear(in_features=64, out_features=64, bias=False)
)
(self_attn_layer_norm): LayerNorm((64,), eps=1e-05, elementwise_affine=True)
(activation_fn): ReLU()
(PositionWiseFeedForward): PositionWiseFeedForward(
(activation): ReLU()
(w_1): Linear(in_features=64, out_features=256, bias=True)
(w_2): Linear(in_features=256, out_features=64, bias=True)
)
(final_layer_norm): LayerNorm((64,), eps=1e-05, elementwise_affine=True)
)
)
)
(decoder): Decoder(
(embed_tokens): Embedding(5893, 64, padding_idx=1)
(embed_positions): SinusoidalPositionalEmbedding(512, 64)
(layers): ModuleList(
(0): DecoderLayer(
(self_attn): MultiHeadAttention(
(q_proj): Linear(in_features=64, out_features=64, bias=False)
(k_proj): Linear(in_features=64, out_features=64, bias=False)
(v_proj): Linear(in_features=64, out_features=64, bias=False)
(out_proj): Linear(in_features=64, out_features=64, bias=False)
)
(self_attn_layer_norm): LayerNorm((64,), eps=1e-05, elementwise_affine=True)
(encoder_attn): MultiHeadAttention(
(q_proj): Linear(in_features=64, out_features=64, bias=False)
(k_proj): Linear(in_features=64, out_features=64, bias=False)
(v_proj): Linear(in_features=64, out_features=64, bias=False)
(out_proj): Linear(in_features=64, out_features=64, bias=False)
)
(encoder_attn_layer_norm): LayerNorm((64,), eps=1e-05, elementwise_affine=True)
(PositionWiseFeedForward): PositionWiseFeedForward(
(activation): ReLU()
(w_1): Linear(in_features=64, out_features=256, bias=True)
(w_2): Linear(in_features=256, out_features=64, bias=True)
)
(final_layer_norm): LayerNorm((64,), eps=1e-05, elementwise_affine=True)
)
(1): DecoderLayer(
(self_attn): MultiHeadAttention(
(q_proj): Linear(in_features=64, out_features=64, bias=False)
(k_proj): Linear(in_features=64, out_features=64, bias=False)
(v_proj): Linear(in_features=64, out_features=64, bias=False)
(out_proj): Linear(in_features=64, out_features=64, bias=False)
)
(self_attn_layer_norm): LayerNorm((64,), eps=1e-05, elementwise_affine=True)
(encoder_attn): MultiHeadAttention(
(q_proj): Linear(in_features=64, out_features=64, bias=False)
(k_proj): Linear(in_features=64, out_features=64, bias=False)
(v_proj): Linear(in_features=64, out_features=64, bias=False)
(out_proj): Linear(in_features=64, out_features=64, bias=False)
)
(encoder_attn_layer_norm): LayerNorm((64,), eps=1e-05, elementwise_affine=True)
(PositionWiseFeedForward): PositionWiseFeedForward(
(activation): ReLU()
(w_1): Linear(in_features=64, out_features=256, bias=True)
(w_2): Linear(in_features=256, out_features=64, bias=True)
)
(final_layer_norm): LayerNorm((64,), eps=1e-05, elementwise_affine=True)
)
(2): DecoderLayer(
(self_attn): MultiHeadAttention(
(q_proj): Linear(in_features=64, out_features=64, bias=False)
(k_proj): Linear(in_features=64, out_features=64, bias=False)
(v_proj): Linear(in_features=64, out_features=64, bias=False)
(out_proj): Linear(in_features=64, out_features=64, bias=False)
)
(self_attn_layer_norm): LayerNorm((64,), eps=1e-05, elementwise_affine=True)
(encoder_attn): MultiHeadAttention(
(q_proj): Linear(in_features=64, out_features=64, bias=False)
(k_proj): Linear(in_features=64, out_features=64, bias=False)
(v_proj): Linear(in_features=64, out_features=64, bias=False)
(out_proj): Linear(in_features=64, out_features=64, bias=False)
)
(encoder_attn_layer_norm): LayerNorm((64,), eps=1e-05, elementwise_affine=True)
(PositionWiseFeedForward): PositionWiseFeedForward(
(activation): ReLU()
(w_1): Linear(in_features=64, out_features=256, bias=True)
(w_2): Linear(in_features=256, out_features=64, bias=True)
)
(final_layer_norm): LayerNorm((64,), eps=1e-05, elementwise_affine=True)
)
)
)
(prediction_head): Linear(in_features=64, out_features=5893, bias=True)
)import sys
if not 'attentionviz' in sys.path:
sys.path += ['attentionviz']
import locale
locale.getpreferredencoding = lambda: "UTF-8"
!pip install regex
def call_html():
import IPython
display(IPython.core.display.HTML('''
<script src="/static/components/requirejs/require.js"></script>
<script>
requirejs.config({
paths: {
base: '/static/base',
"d3": "https://cdnjs.cloudflare.com/ajax/libs/d3/3.5.8/d3.min",
jquery: '//ajax.googleapis.com/ajax/libs/jquery/2.0.0/jquery.min',
},
});
</script>
'''))Looking in indexes: https://pypi.org/simple, https://us-python.pkg.dev/colab-wheels/public/simple/
Requirement already satisfied: regex in /usr/local/lib/python3.9/dist-packages (2022.10.31)SAMPLE_IDX = 131
with torch.no_grad():
for idx,example in enumerate(test_iterator):
if idx == SAMPLE_IDX:
sample = example
src = sample.src
trg = sample.trg
output, enc_attention_score, dec_attention_score = model(src, trg) #turn off teacher forcing
attention_score = {'self':enc_attention_score, 'cross':dec_attention_score}
src_tok = [SRC.vocab.itos[x] for x in src.squeeze()]
trg_tok = [TRG.vocab.itos[x] for x in trg.squeeze()]
call_html()
head_view(attention_score, src_tok, trg_tok)<IPython.core.display.Javascript object>
<IPython.core.display.Javascript object>Reference
- AI504: Programming for AI Lecture at KAIST AI
