Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation REVIEW
paper review
Abstract
RNN Encoder-Decoder을 제안: RNN의 encoder는 source sequence(sentence)를 고정된 길이의 vector로 encodes 하고, decoder은 고정된 길이의 vector을 target sequence로 decode
입력 문장(source sentence)이 주어졌을 때 조건부 확률을 최대화하는 출력 문장(target sentence)을 찾도록 훈련
기존 SMT 시스템보다 성능이 향상되었으며, 모델이 언어 구문의 의미적, 문법적인 표현을 배울 수 있음
1 Introduction
NLP 분야에 신경망을 접목시키는 연구는 꽤 많이 진행되어 왔고, Statistical Machine Translation(SMT)분야에서 deep neural network는 promising한 결과를 보여주고 있음
기존 phrase-based SMT system의 일부로 사용할 수 있는 새로운 neural network인 RNN Encoder-Decoder을 제안: encoder는 variable-length source sequence를 fixed-length vector에 매핑하고 decoder는 이 vector representation을 다시 variable-length target sequence에 매핑
→ 두 개의 네트워크는 source sequence가 주어진 target sequence의 조건부 확률을 최대화하기 위해 함께 훈련되고, 개선된 hidden state를 사용함
새로운 hidden state가 있는 RNN Encoder-Decoder은 영어 → 프랑스어 phrase의 번역 확률을 학습하고, phrase table에 각 phrase pair에 점수를 매겨 standard phrase-based SMT 시스템의 일부로 사용
2 RNN Encoder-Decoder
2.1 Preliminary: Recurrent Neural Networks
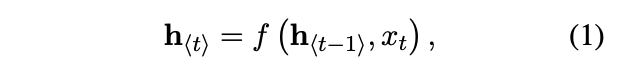
RNN은 hidden state h와 variable length sequence x, output y로 구성되어 있음
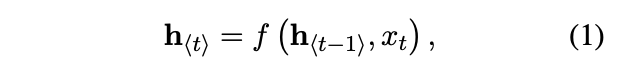
각 time step t에서의 값을 조건부 분포로 구함(softmax 함수 사용)

이렇게 학습된 분포로 각 time step에서 symbol을 샘플링해서 새로운 sequence를 반복적으로 얻을 수 있음
2.2 RNN Encoder-Decoder
확률적인 관점에서 variable-length sequence의 조건부 확률: T 길이를 갖는 x sequence로, T’ 길이를 갖는 y sequence의 조건부 확률을 학습 (T와 T’의 길이는 다를 수 있음)
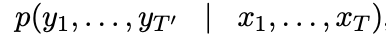
encoder: x sequence의 각 symbol을 차례대로 읽는대로 hidden state가 바뀌는데, 시퀀스가 end of sequence symbol로 끝이 나면 총 인풋 시퀀스의 hidden state에 대해 c로 정리
decoder: h_t로 다음 symbol인 y_t을 예측
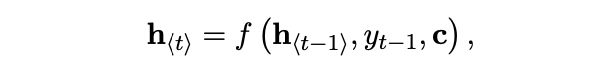
다음 symbol의 조건부 분포
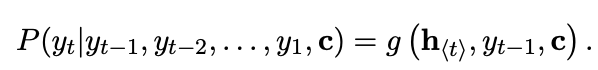

encoder에서 각 타임스텝 T의 hidden state가 모여 c로 정리되고, c가 decoder로 흘러가서 T'개의 output y sequence를 출력
encoder와 decoder는 conditional log-likelihood를 최대화하기 위해 함께 훈련(θ 는 모델 파라미터의 개수)
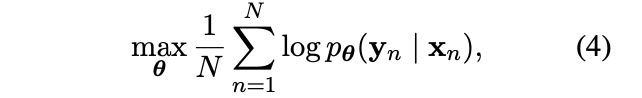
훈련된 모델은 두가지 방향으로 사용 가능
- input sequence가 target sequence를 생성
- input과 output sequence의 주어진 쌍에 score을 매김 → pθ(y | x) (ex - y: I | x: 나는)
2.3 Hidden Unit that Adaptively Remembers and Forgets
새로운 hidden gate에 대해 설명
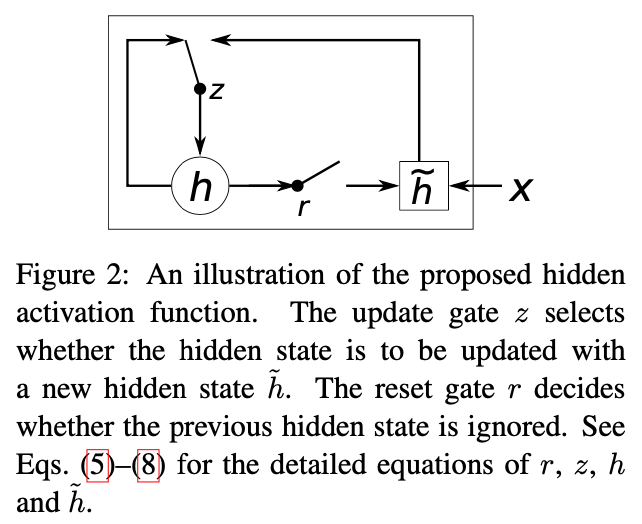
- reset gate: 이전 hidden state의 값을 얼마나 무시할 지 결정하는 gate (0이면 다 무시)
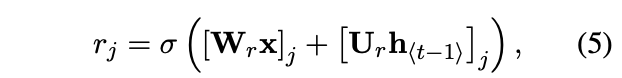
- σ 는 로지스틱 시그모이드 함수이고, j는 j번째 벡터, x와 ht−1은 이전 단계의 인풋과 hidden state, 그리고 Wr, Ur은 학습된 가중치 행렬
- update gate: 이전 hidden state의 값을 현재 hidden state에 얼마나 반영할 지 조절하는 gate
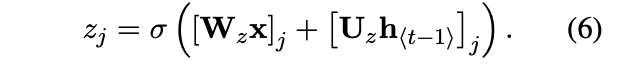
최종 hidden state

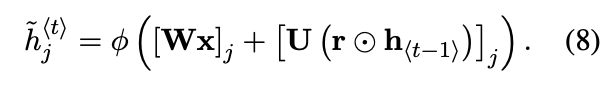
- h_j의 후보 = c
단기 의존성을 포착하도록 학습한 유닛은 reset gate가 활발하고, 장기 의존성을 포착하도록 학습한 유닛은 update gate가 활발한 경향이 있음
3 Statistical Machine Translation
SMT: 통계적 방법론을 활용하여 번역하는 방법
- source data를 feature 기준으로 자름
- source data: 나는 먹는 것을 좋아합니다
- 나는 / 먹는 / 것을 / 좋아 (단어단위)
- feature 종류는 여러가지: 단어 단위, bi-gram 단위등
- 번역
- I / eat / to / like
- 번역된 문장의 확률을 도출
- p(I|나는)p(eat|먹는)p(to|것을)p(like|좋아)
→ 다양한 feature의 확률을 선형조합하여 제일 높은 확률을 갖는 문장으로 번역
argmax log_p(영어|한글) = ∑(n=1 ~ N) w_n*f_n(영어|한글)
- f_1 : 단어단위로 자른 확률
- f_2: bi-gram 단위로 자른 확률 . . .

최적의 p(f|e)를 찾기 위해 학습: source sentence e로 번역 문장인 f를 찾음
- p(e|f) = translation model
- p(f) = language model
주로 logp(f∣e) 의 선형 로그 모델을 더 많이 사용함: BLEU 스코어를 최대화하기 위해 최적화
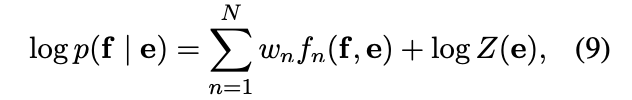
f_n과 w_n은 은 n번째 feature와 가중치이고, Z(e)는 정규화 상수
3.1 Scoring Phrase Pairs with RNN Encoder-Decoder
RNN Encoder-Decoder을 phrase 쌍 테이블에 학습시키고 선형로그 모델의 피쳐로 점수를 도출
각 phrase 쌍의 정규화된 빈도는 무시
- 정규화된 빈도에 따라 큰 phrase table에서 랜덤으로 phrase pair을 선택하는 계산 비용을 줄임
- RNN Encoder-Decoder가 단순히 phrase pair의 순위를 매기는 것을 학습하지 않기 위함
→ 이렇게 할 수 있는 이유는 phrase table의 번역 확률이 이미 빈도를 가지고 있기 때문
따라서 RNN Encoder-Decoder는 언어적 규칙성을 학습하는 데에 초점을 맞춤
RNN Encoder-Decoder가 훈련되면 기존 구문 테이블에 각 구문 쌍에 대한 새 점수를 추가: 새 점수가 비용을 최소화하면서 알고리즘에 포함될 수 있도록 함
3.2 Related Approaches: Neural Networks in Machine Translation
- scoring phrase pair: fixed size input
- feedforward neural network: monolingual
- encoder와 decoder로 구성된 유사한 모델: n-gram모델
4 Experiments
English / French translation task
4.1 Data and Baseline System
712M words crawling newpaper data의 유사한 하위집합에서 language modeling을 위한 418M 단어, Encoder-Decoder 학습을 위한 348M 단어를 선택
Encoder-Decoder source와 target 단어를 15000개의 가장 빈도수가 높은 영어, 불어 단어로 제한
baseline phrase-based SMT system은 Moses를 사용
4.1.1 RNN Encoder-Decoder
- Encoder와 decoder에 1000개의 hidden units를 갖음
- 인풋과 hidden unit 사이에 들어가는 행렬을 100차원으로 설정해서 100차원의 임베딩 학습할 수 있도록 함
- 모든 가중치는 표준편차가 0.01로 고정된 zero-mean 가우시안 분포에서 샘플링하여 초기화
- 3일동안 training
4.1.2 Natural Language Model
- 전통적인 접근법인 CSLM 언어모델을 학습
- 출력은 softmax
- 모든 가중치는 -0.01과 0.01사이에서 균일하게 초기화
4.2 Quantitative Analysis
- Baseline configuration: Moses 오픈 소스 번역 모델
- Baseline + RNN: RNN Encoder-Decoder 모델
- Baseline + CSLM + RNN
- Baseline + CSLM + RNN + Word penalty: Word penalty는 unknown word에 대한 penalty 부여
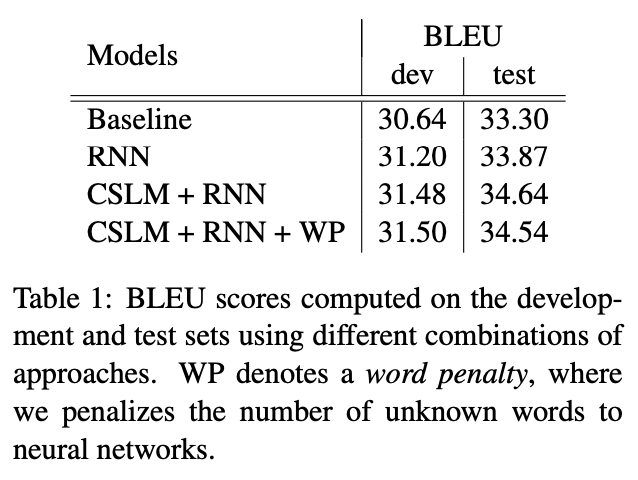
→ development set에서의 성능은 4번째(CSLM+RNN+WP)가 가장 높음: CSLM과 RNN이 크게 상관관계가 있지는 않으며 독립적으로 개선시키는 것으로도 성능을 높일 수 있음
→ 하지만 test set에서는 CSLM+RNN이 가장 높음
4.3 Qualitative Analysis
성능 향상이 어디서 비롯되는지 이해하기 위해, RNN Encoder-Decoder에 의해 계산된 phrase pair 점수를 translation model에 해당되는 p(f | e)와 비교하여 분석
- 기존 번역 모델은 말뭉치의 phrase pair 통계에만 의존하기 때문에, 빈도수가 높은 구문에는 잘 추정되지만 희귀한 구문에는 더 나쁘게 추정될 것으로 예상함
- 빈도수의 정보 없이 훈련된 RNN Encoder-Decoder가 통계보다는 언어적 규칙성을 기반으로 구문 쌍을 채점할 것으로 예상함
시퀀스가 길고(한 source phrase에 단어 3개 이상) 빈도수가 높은 phrase와 길고 빈도수가 낮은 phrase를 비교
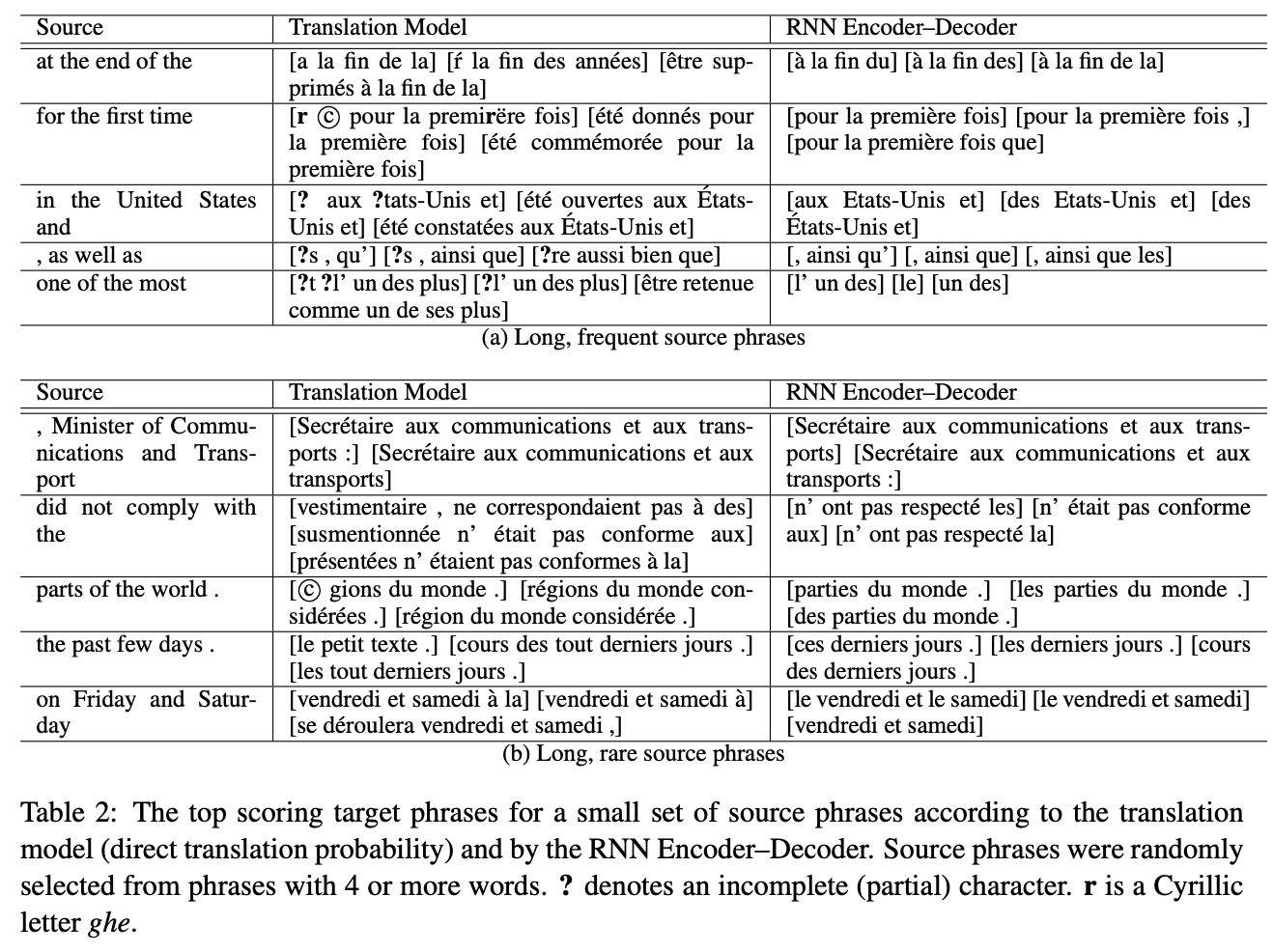
→ 번역 모델 또는 RNN Encoder-Decoder가 선호하는 source phrase 당 상위 3개의 대상 구문
→ 대부분의 경우에서 target phrase는 실제로 또는 단어 그대로 번역인 것들과 가까웠고, RNN Encoder-Decoder가 짧은 문구를 선호함
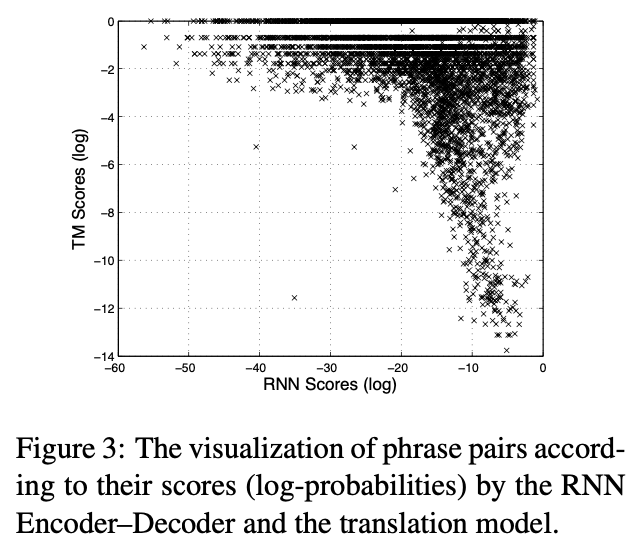
→ 많은 구문 쌍들이 번역 모델과 RNN Encoder-Decoder 모두에서 유사하게 점수를 받았지만, 근본적으로 다르게 점수를 매긴 다른 구문 쌍들이 많았음
→ 번역 모델과 RNN Encoder-Decoder가 점수 낸 쌍이 다른 것들도 있었는데, 이는 RNN Encoder-Decoder가 유니크한 쌍에 학습되어서 빈도수가 높은 pair만 학습하는 것을 막았기 때문

→ table 2의 각 source phrase에 대해 RNN Encoder-Decoder에서 생성된 샘플
→ RNN Encoder-Decoder가 실제 phrase table을 보지 않고도 잘 형성된 target phrase를 제안할 수 있음
→ RNN Encoder-Decoder로 phrase table 전체 또는 일부를 대체할 가능성이 있음
4.4 Word and Phrase Representations
RNN Encoder-Decoder도 단어 시퀀스를 연속적인 공간 벡터로 매핑하기 때문에, semantically embedding을 잘 할 것으로 예상
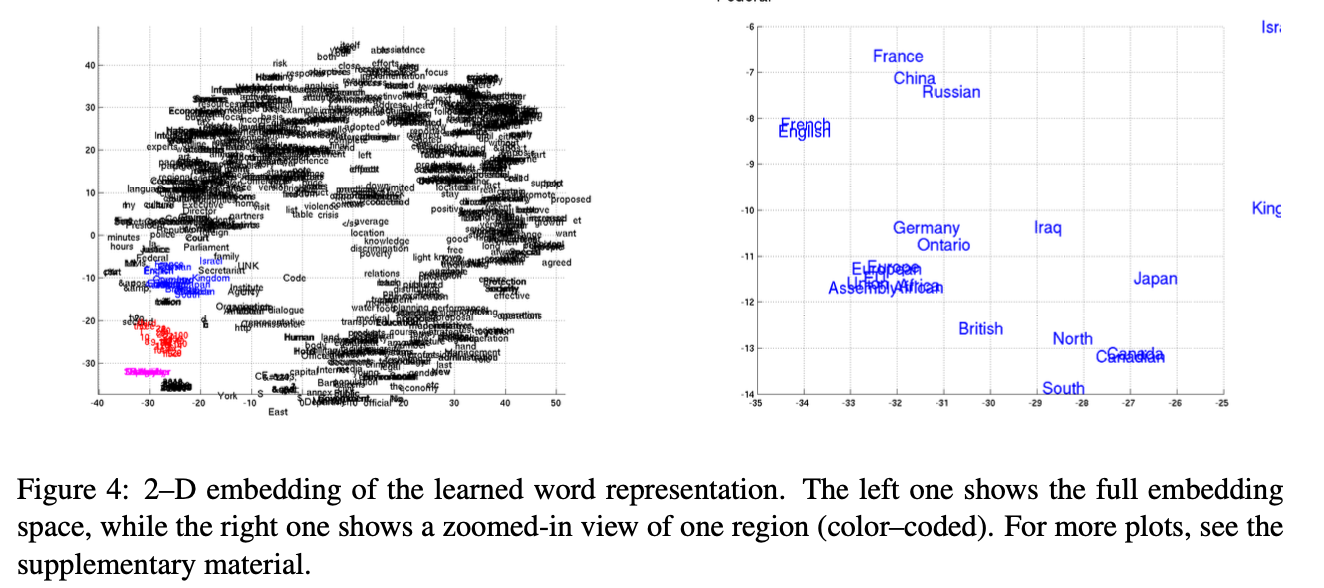

→ 4개 이상의 단어로 구성된 문구의 표현을 시각화
→ RNN Encoder-Decoder은 phrase의 의미론적 구조와 구문적 구조를 모두 capture
5 Conclusion
- 가변적인 입력 문장에 대해 가변적인 타겟 문장을 매핑할 수 있는 RNN Encoder-Decoder라는 새로운 모델을 제시
- sequeunce 쌍의 조건부 확률을 계산하거나, source sequence 로부터 target sequences를 생성
- reset gate와 update gate를 포함하는 hidden unit을 제시
- SMT 시스템의 전체적인 성능을 향상시킬 수 있었음
- 추가로, LSTM보다 가볍고 빠르게 학습할 수 있는 GRU 제시
- 다양한 레벨 (syntactic, semantic 등) 에서 언어적 규칙성 포착
- 번역 시스템 전체(End-to-End)로 대체할 수 있으며, 더 나아가 글쓰기나 음성 번역에도 활용할 수 있을 것
