Abstract
CNN(Convolutional Neural Network)정확도를 향상시키는 수많은 기능이 있고, batch normalization과 residual connection은 대부분의 model, task, dataset에 적용할 수 있음
본 논문에서는 WRC, CSP, CmBN, SAT, Mish activation, Mosiac data augmentation, DropBlock, CIoU loss등의 기법을 적용하였고, 이 중 일부를 결합하여 MS COCO dataset에 대해 AP : 43.5% (AP50 : 65.7%), 65 FPS(Tesla V100 그래픽카드 , 거의 실시간에 가까운 높은 FPS)를 달성
1. Introduction
가장 정확한 현대의 neural network는 실시간으로 작동하지 않으며, 큰 mini-batch-size의 훈련을 위해 많은 수의 GPU가 필요함 → 우리는 기존 GPU에서 실시간으로 작동하고 훈련에 하나의 기존 GPU만 필요한 CNN을 생성하여 이러한 문제를 해결
본 연구의 주요 목표는 object detector의 빠른 작동을 설계하고 병렬계산을 위한 최적화
- efficient and powerful object detection을 개발하고, 모든 사람이 1080Ti 또는 2080Ti GPU를 사용하여 매우 빠르고 정확한 물체 탐지기를 훈련시킬 수 있게 함
- detector 훈련 중에 BOF와 BOS 기법의 영향을 검증
- CBN, PAN, SAM을 포함한 기법을 활용하여 single GPU training에 효과적
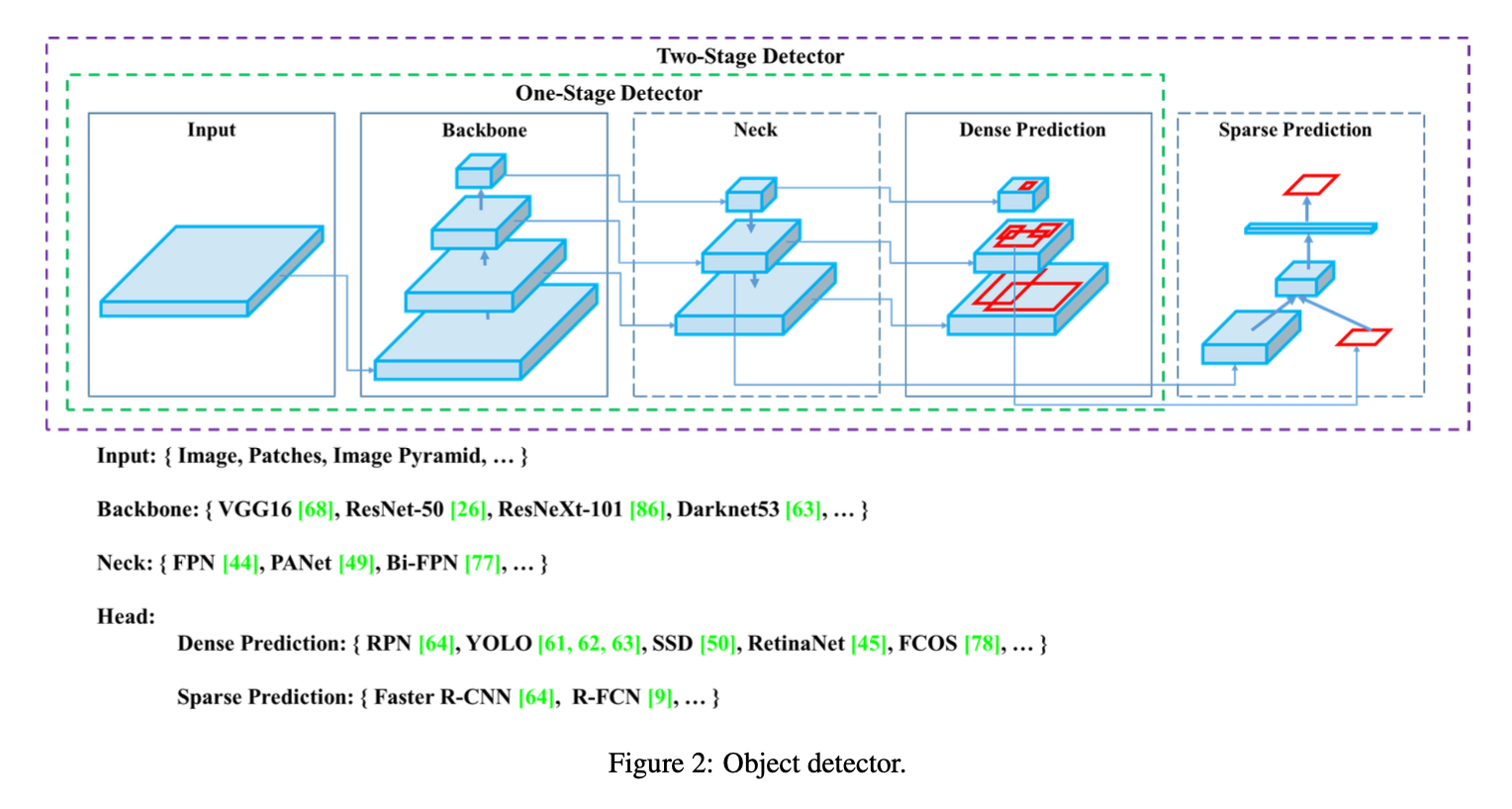
2. Related work
2.1. Object detection models
object detection = backbone(pretrained on ImageNet) + head(predict bounding boxes and classes)
최근에는 backbone과 head 사이의 neck layer를 삽입: feature map을 refinement하는 역할
2.2. Bag of freebies
inference cost의 증가 없이 성능 향상(better accuracy)을 받을 수 있는 방법
- data augmentation : input image의 가변성을 증가시켜 object detection model이 다른 환경에서 얻어진 이미지에 대해 higher robustness를 갖도록 함
- Photometric distortions
- Geometric distortions
- random erase, CutOut, hide-and-seek, grid mask
- DropOut, DropConnect, DropBlock
- MixUp, CutMix
- style transfer GAN
- semantic distribution bias : 서로 다른 클래스 사이의 data imbalance 문제를 해결
- hard negative example mining, online hard example mining (two-stage detector)
- focal loss (one-stage detector)
- label smoothing
- objective function : 기존의 MSE를 대신하는 loss function
- IoU loss: 예측된 bounding box와 실제 bounding box의 coverage를 고려
- GIoU loss: coverage area와 shape 및 orientation을 포함
- DIoU loss: object의 중심 거리를 고려
- CIoU loss: overlapping area, center points 사이의 거리, aspect ratio를 동시에 고려
2.3. Bag of specials
inference cost가 조금 상승하지만, 크게 성능 향상(improve accuracy)을 받을 수 있는 방법
- Plugin modules: 모델에서 특정 속성 향상
- enhancing receptive field: SPP(SPM+CNN), ASPP, RFB
- introducing attention mechanism: channel-wise attention(Squeeze-and-Excitation(SE)), point-wise attention(Spatial Attention Module(SAM))
- strengthening feature integration capability: SFAM, ASFF, BiFPN
- activation function: LReLU, PReLU, ReLU6, Scaled Exponential Linear Unit(SELU), Swish, hard-Swish, Mish
- Swish, Mish: continuously differentiable activation function
- Post-processing: 모델 예측 결과 선별
- NMS(Non-Maximum Suppression): 동일한 object에 대하여 생성된 BBox중 high reponse를 가진 BBox만 남기고 필터링 하는 것
3. Methodology
3.1. Selection of architecture
목적
- input network resolution, convolutional layer number, parameter number, number of layer output 사이의 최적의 balance
- Receptive field를 늘리기 위한 additional block과 서로 다른 detector level에 대한 서로 다른 parameter aggregation의 최적 method
detector requires
- Higher input network size
- More layers
- More parameters

→ CSPDarknet53이 detector의 backbone 최적 모델임을 알 수 있음
influence of receptive field
- Up to the object size
- Up to network size
- Exceeding the network size
→ SPP block을 receptive field로 추가
최종 선택 기법
- backbone
- CSPDarknet53
- neck
- SPP additional module
- PANet path-aggregation neck
- head
- YOLOv3
3.2. Seletcion of BoF and BoS
- Activations: ReLU, leaky-ReLU, parametric-ReLU (X) ,ReLU6 (X) , SELU (X), Swish, Mish
- Bounding box regression loss: MSE, IoU, GIoU, CIoU, DIoU
- Data augmentation: CutOut, MixUp, CutMix
- Regularization method: DropOut, DropPath, Spatial DropOut, DropBlock
- Normalization of the network activations by their mean and variance: Batch Normalization (BN), Cross-GPU Batch Normalization (CGBN or SyncBN) (X), Filter Response Normalization (FRN), Cross-Iteration Batch Normalization (CBN)
- Skip-connections: Residual connections, Weighted residual connections, Multi-input weighted residual connections, Cross stage partial connections (CSP)
3.3. Additional improvements
Single GPU에서 detector가 더 suitable 하게 하도록 addtional design and improvement 추가
- 새로운 data augmentation 기법인 Mosaic과 Self-Adversarial Training (SAT)

- genetic algorithms 적용하여 최적의 hyper-parameters 선택
- modified SAM, modified PAN, and Cross mini-Batch Normalization (CmBN)
→CmBN: CBN의 수정된 버전으로 single batch 내에서 mini-batches 사이에 대한 통계를 수집
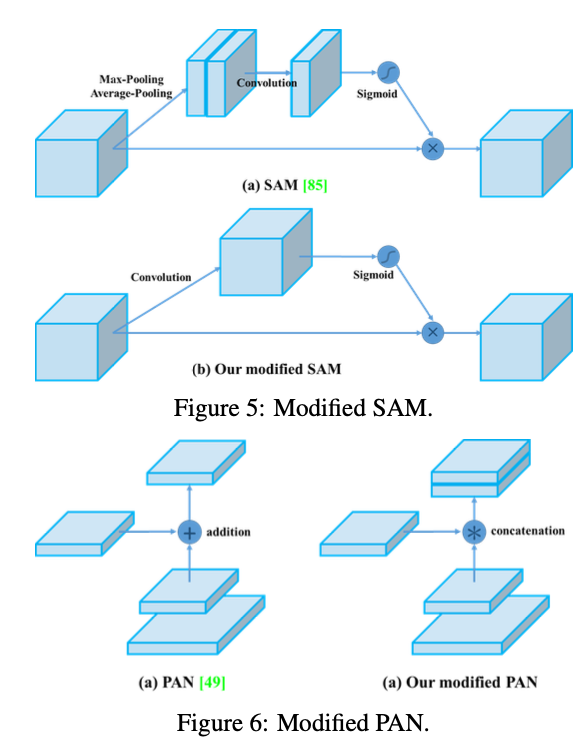
→ Modified SAM: Spatial-wise attention에서 point-wise attension으로 변경
→ Modified PAN: Shortcut connection을 concatenation으로 교체
3.4. YOLOv4
YOLOv4 consists of:
- Backbone: CSPDarknet53
- Neck: SPP, PAN
- Head: YOLOv3
YOLOv4 uses:
- BoF for backbone: CutMix and Mosaic data augmentation, DropBlock regularization, Class label smoothing
- BoS for backbone: Mish activation, Cross-stage partial connections (CSP), Multi-input weighted residual connections (MiWRC)
- BoF for detector: CIoU-loss, CmBN, DropBlock regularization, Mosaic data augmentation, Self-Adversarial Training (SAT), Eliminate grid sensitivity, Using multiple anchors for a single ground truth, Cosine annealing scheduler, Optimal hyper-parameters, Random training shapes
- BoS for detector: Mish activation, SPP-block, SAM-block, PAN path-aggregation block, DIoU-NMS
4. Experiments
classifier→ ImageNet datasets으로, detector → MS COCO dataset으로 실험 진행
4.1. Experiments setup
논문 참고
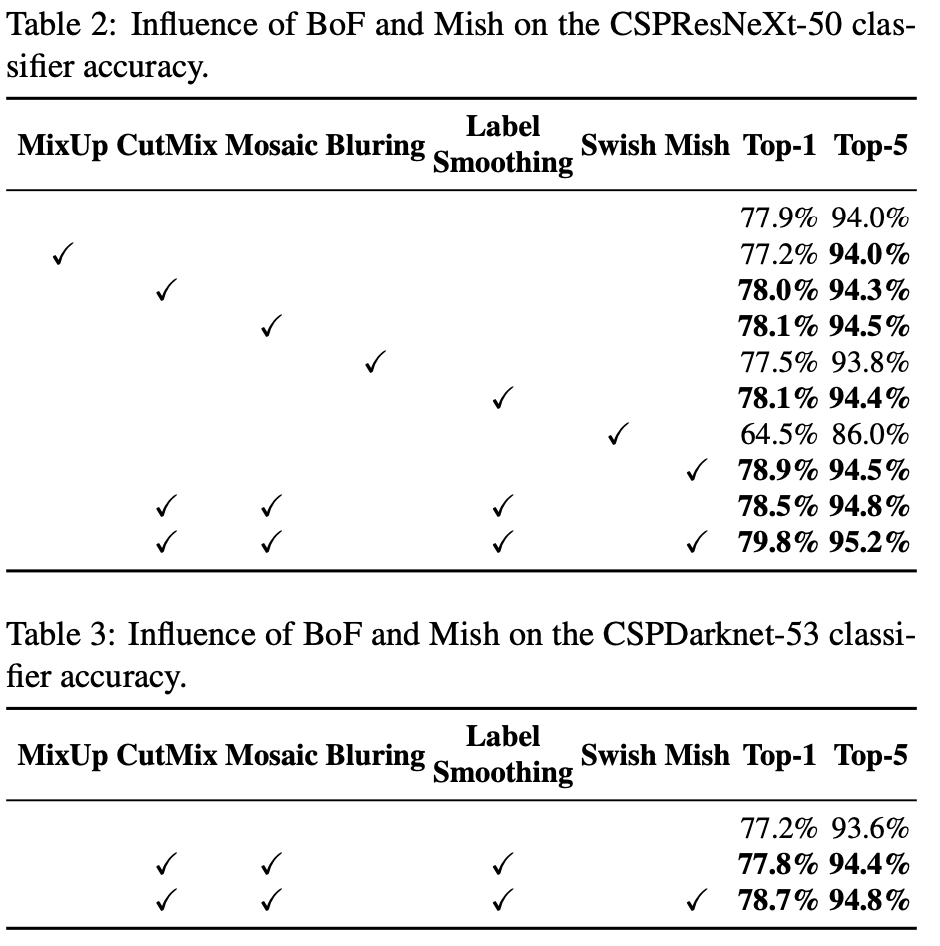
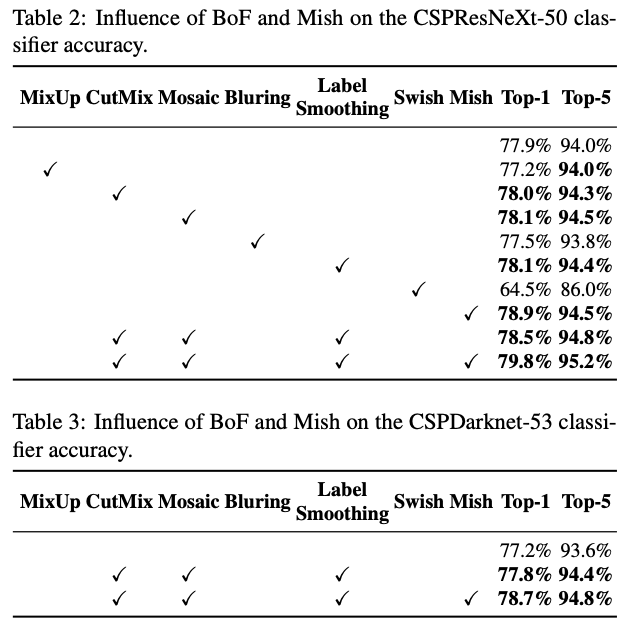
4.2. Influence of different features on Classifier training

classfier training 성능을 향상시키는 feature들은 CutMix and Mosaic for data augmentation, Class label smoothing, Mish activation
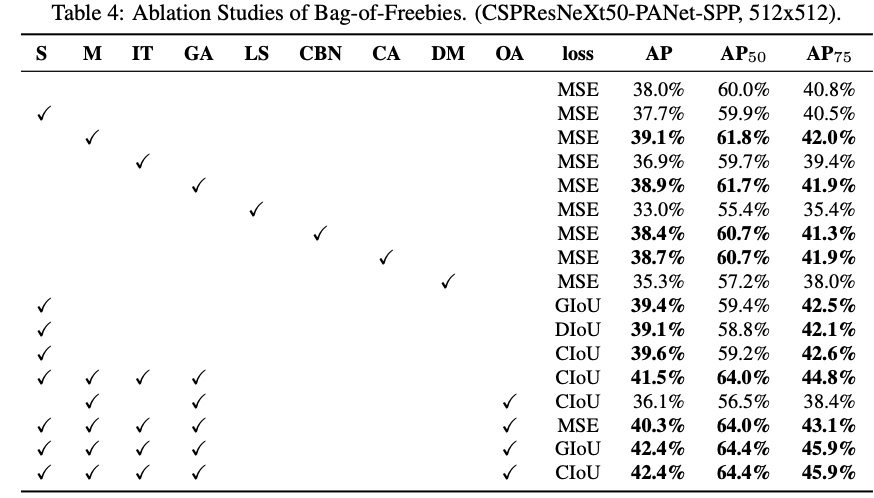
4.3. Influence of different features on Detector training
서로 다른 BoF-detector가 detector training accuracy에 주는 영향을 보기 위하여 추가적인 연구를 진행
- S: Eliminate grid sensitivity the equation bx=σ(tx)+cx,by=σ(ty)+cy where cx and cy are always whole numbers, is used in YOLOv3 for evaluating the object coordinates, therefore, extremely high tx absolute values are required for the bx value approaching the cx or cx+1 values.
- M: Mosaic data augmentation
- IT: IoU threshold - using multiple anchors for a single ground truth IoU (truth, anchor) > IoU threshold
- GA: Genetic algorithms - using genetic algorithms for selecting the optimal hyperparameters during network training on the first 10% of time periods
- LS: Class label smoothing
- CBN: CmBN - using Cross mini-Batch Normalization
- CA: Cosine annealing scheduler - altering the learning rate during sinusoid training
- DM: Dynamic mini-batch size - automatic increase of mini-batch size during small resolution training by using Random training shapes
- OA: Optimized Anchors - using the optimized anchors for training with the 512x512 network resolution
- GIoU, CIoU, DIoU, MSE- using different loss algorithms for bbox regression
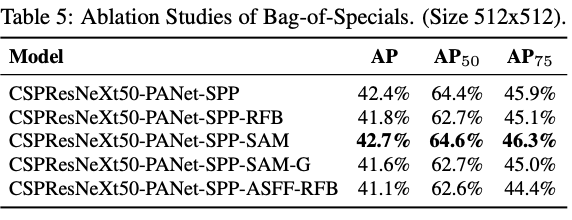
BoS-detector 또한 detector training accuracy의 향상에 있어서 많은 영향을 주는지 연구를 진행하였고 SPP, PAN, SAM을 사용하였을 때 가장 좋은 성능을 보임
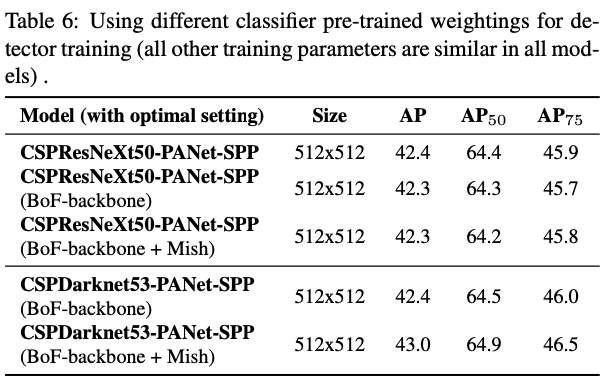
4.4. Influence of different backbones and pre-trained weightings on Detector training
다른 backbone model이 detector accuracy에 미치는 영향을 보기 위한 연구 진행
- CSPResNeXt-50 모델의 classification accuracy가 높은 반면, object detection에선 CSPDarknet53 모델이 더 높은 accuracy를 가짐
- CSPResNeXt50 classifier training 모델에 BoF와 Mish를 적용하여 classification accuracy를 향상시킨 반면, detector accuracy는 오히려 감소, 반대로 CSPDarknet53 classifier training 모델에 BoF와 Mish를 적용하였을 때는 classification accuracy와 detector accuracy 둘 다 상승
→ CSPDarknet53 모델이 detector accuracy를 높일 수 있는 더 능력을 보여줌
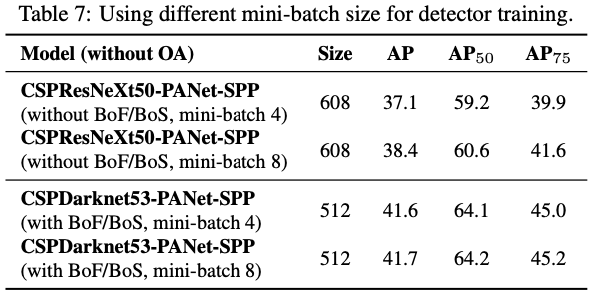
4.5. Influence of different mini-batch size on Detector training
서로 다른 mini-batch size로 training한 모델을 분석하는 연구 진행
- BoF와 BoS training 전략을 추가한 후, mini-batch size는 detector의 성능에 영향 미치지 않음
→ BoF와 BoS가 도입된 후 누구나 기존의 GPU만으로 학습 가능
5. Results
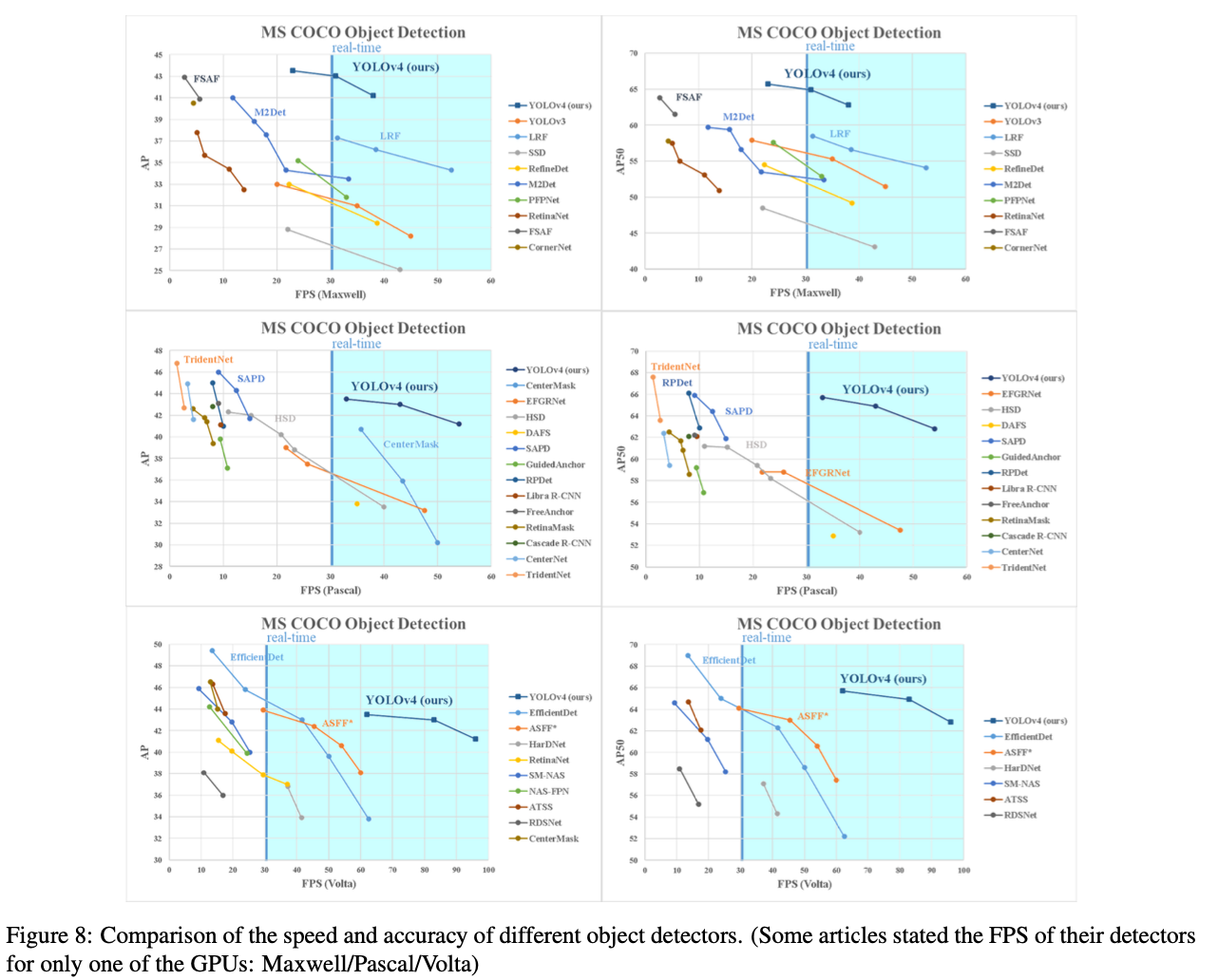
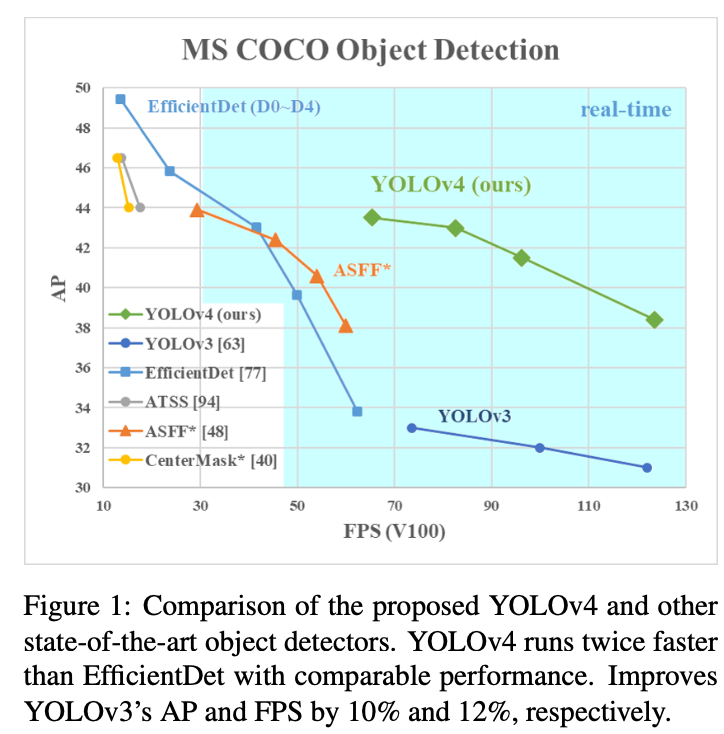
→ YOLOv4는 Pareto optimality curve에 위치하고 있고, 속도와 정확성 면에서 가장 빠르고 정확한 검출기보다 우수함
GPU 비교 table은 논문을 참조
6. Conclusions
논문에서 설명된 detector은 8-16GB-VRAM이 있는 기존 GPU에서 훈련되고 사용될 수 있어 광범위한 사용이 가능함
1-stage anchor-based detector가 증명되기 위해 많은 기능을 검증하여 classifier와 detector의 정확도를 향상
