
이번에 졸업프로젝트로 피치 감지를 통해 자신의 음역대에 맞는 음악을 추천해주는 서비스를 구현할 예정입니다. 그러기 위해서는 피치 감지가 필수적인데요, 이러한 피치 감지 구현하기 위해 FFT라는 기술과 SPICE라는 모델을 사용하여 개발했습니다.
FFT란?
FFT(고속 퓨리에 변환, Fast Fourier Transform)는 시간 영역의 신호를 주파수 영역으로 변환하는 효율적인 알고리즘입니다. 이를 통해 주파수 성분을 추출할 수 있습니다.
푸리에의 아이디어는 간단합니다.
1. 모든 소리는 기본 파형(Sine파 등) 여러 개의 합이다.
2. 따라서 모든 소리는 여러 개의 기본 파형으로 분리할 수 있다.
즉, 오디오 분석에서의 푸리에 변환은 소리의 파형을 여러 개의 기본파형으로 변환하는 알고리즘입니다.
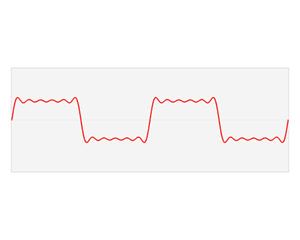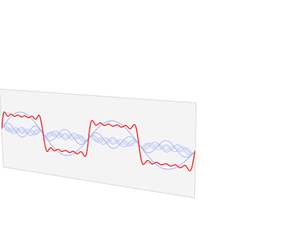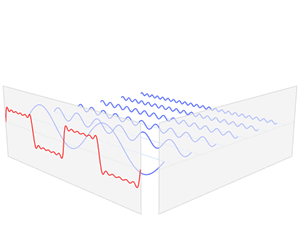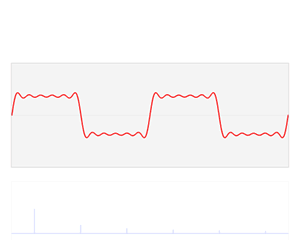
출처:https://en.wikipedia.org/wiki/Fourier_transform
위의 그림의 움직임을 유심히 살펴보면
퓨리에 변환의 아이디어를 쉽게 이해할 수 있습니다.
분리된 기본 파형(Sine파)들은 "특정 주파수"에서의 "진폭 값의 변화"를 나타내므로
이를 계산하면 복잡한 파형을 구성하는 각 주파수별 진폭값을 구해낼 수 있습니다.
필요한 라이브러리 설치
!sudo apt-get install -q -y timidity libsndfile1 #colab에서 리눅스 명령어를 사용할 때는 !을 붙여준다.
!pip install pydub librosa music21오디오 파일 입력 및 오디오 시각화
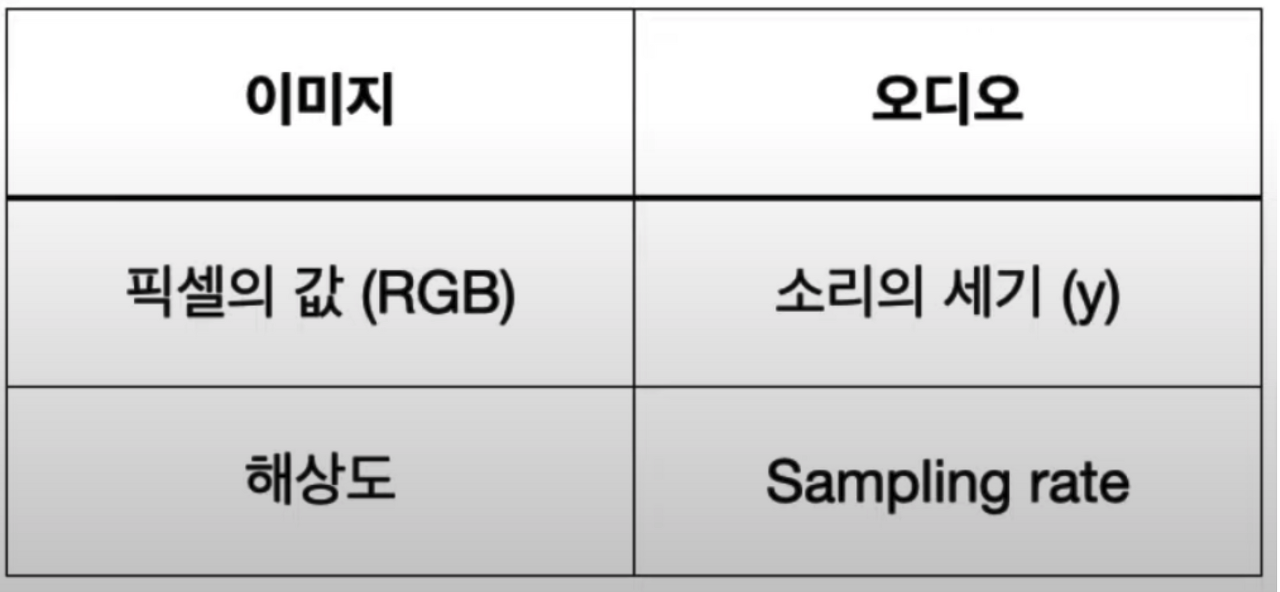
오디오 파일 이해하기 : 숫자로 이루어짐
-
y : 소리가 떨리는 세기(진폭)를 시간 순서대로 나열한 것
-
Sampling rate: 1초당 샘플의 개수, 단위 1초당 Hz 또는 kHz
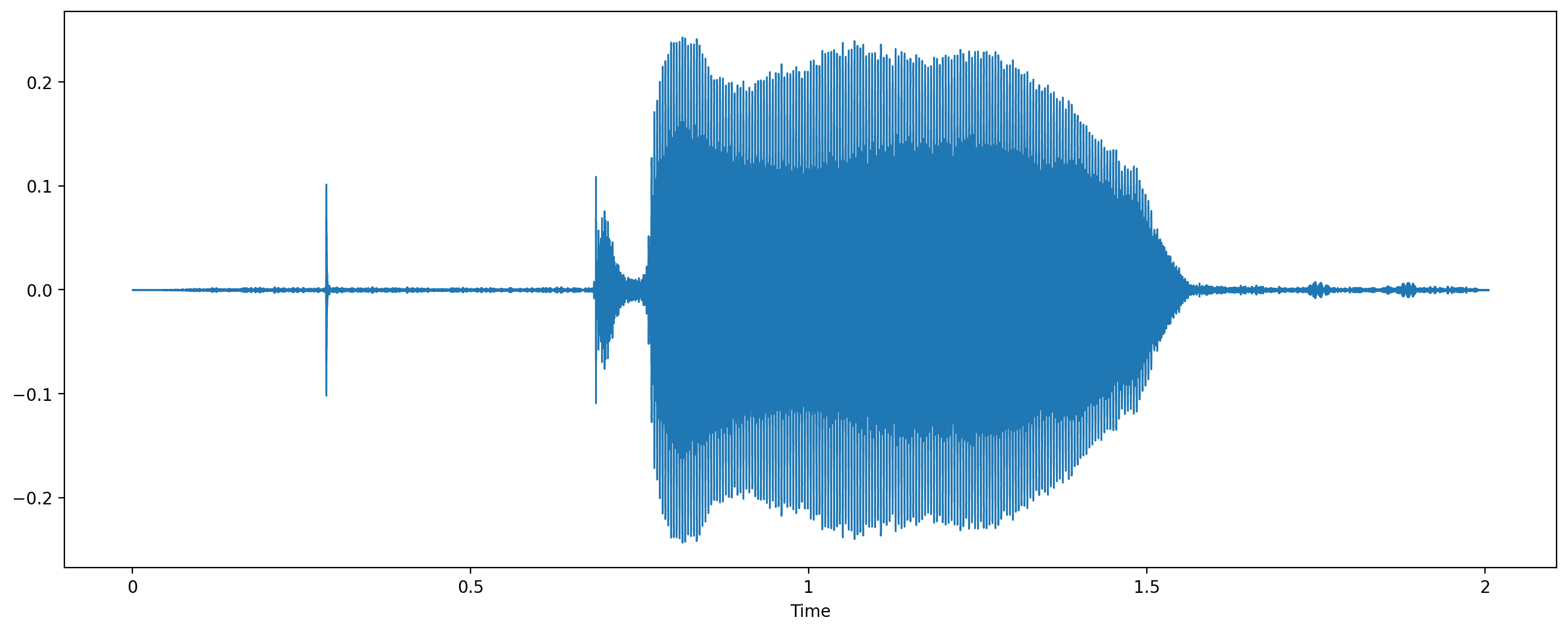
y, sr = librosa.load("test.wav", sr = None)
# 2D 음파 그래프
plt.figure(figsize =(16,6))
librosa.display.waveshow(y=y,sr=sr)
plt.show()
2D 음파 그래프
Fourier Transform(푸리에 변환)
-
시간 영역 데이터를 주파수 영역으로 변경 : time(시간) domain -> frequency(진동수) domain 변경 시 얻는 정보가 많아져 분석 용이.
-
y축: 주파수(로그 스케일)
-
color축:데시벨(진폭)
S = np.abs(librosa.stft(y, n_fft=1024, hop_length=512, win_length = 1024, window=signal.hann))
pitches, magnitudes = librosa.piptrack(S=S, sr=sr)
print(S.shape)
plt.figure(figsize=(16,6))
plt.plot(S)
plt.show()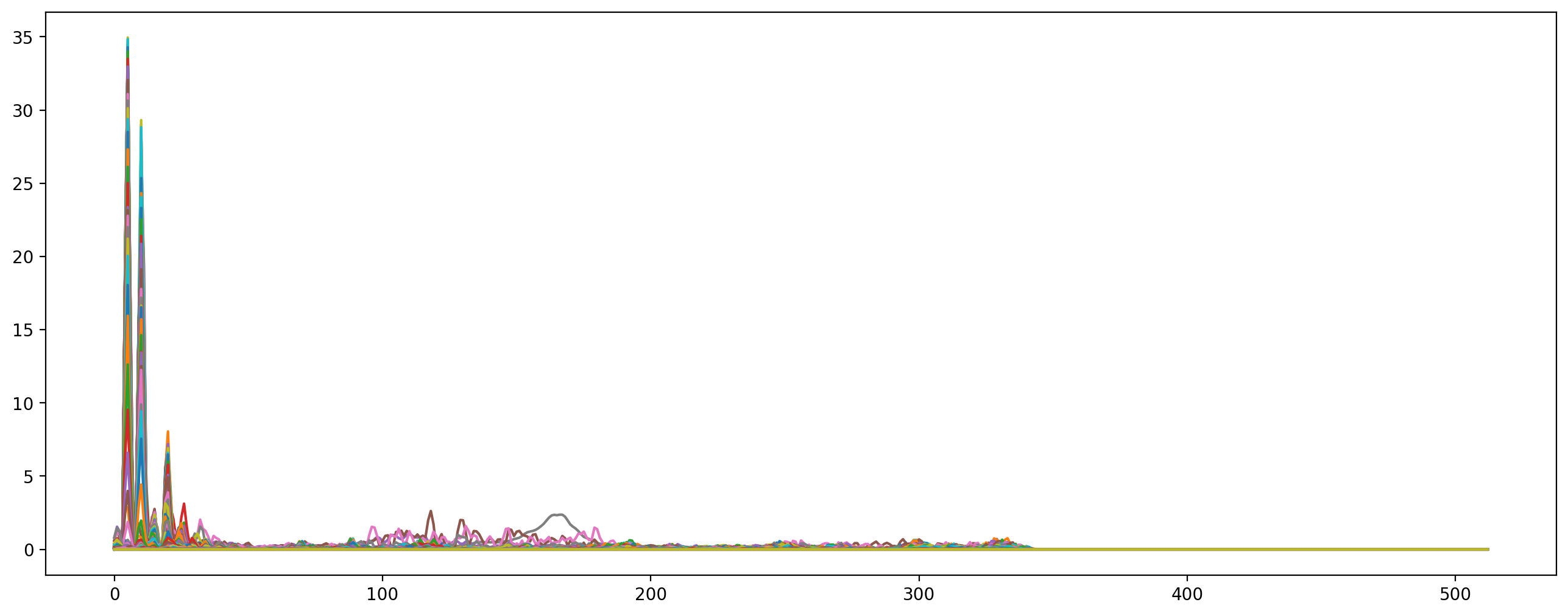
Spectogram
-
시간에 따른 신호 주파수의 스펙트럼 그래프
-
다른 이름 : Sonographs, Voiceprints, Voicegrams
DB = librosa.amplitude_to_db(S, ref=np.max) #amplitude(진폭) -> DB(데시벨)로 바꿔라
plt.figure(figsize=(16,6))
librosa.display.specshow(DB,sr=sr, hop_length=512, x_axis='time', y_axis='log')
plt.colorbar()
plt.show()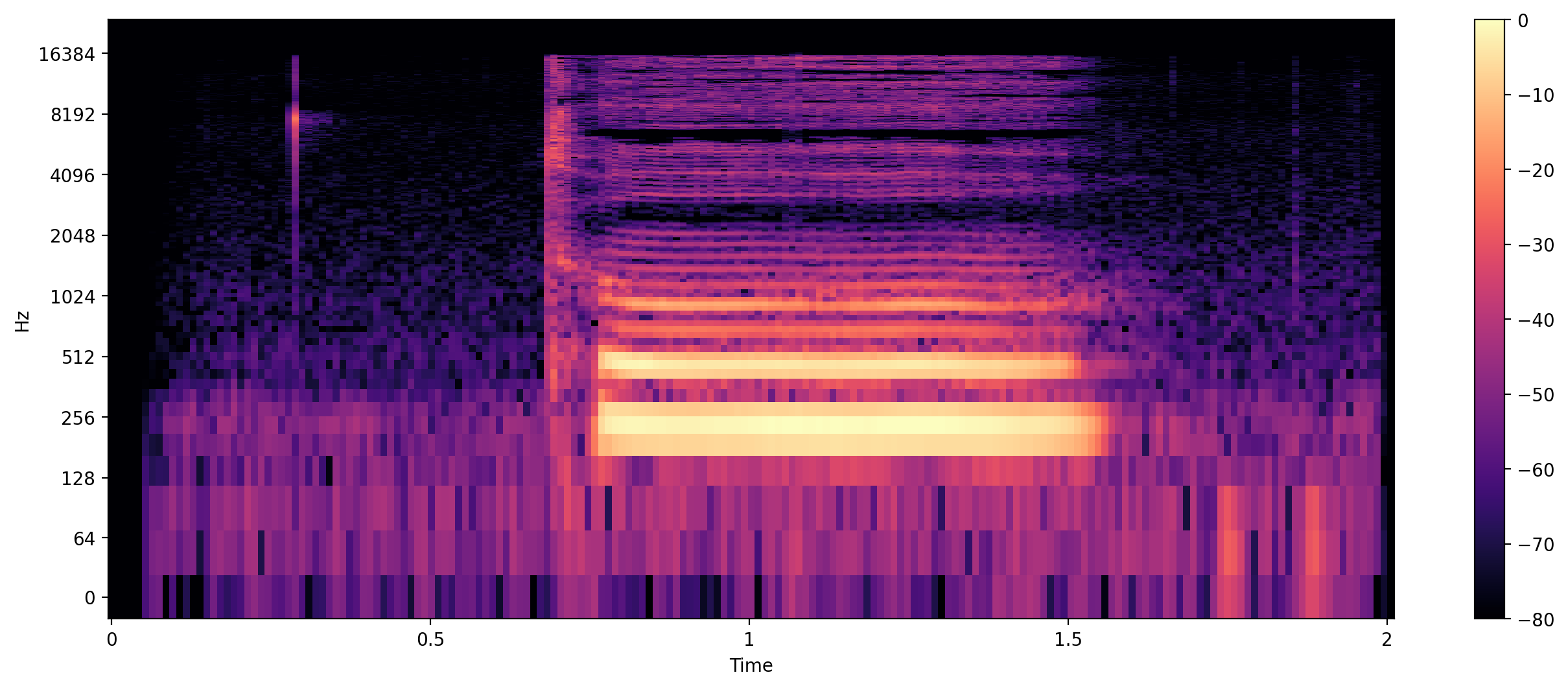
SPICE 모델 실행하기
모델을 로드하기 위해 허브 모듈과 모델을 가리키는 URL만 있으면 됩니다.
model = hub.load("https://tfhub.dev/google/spice/2")피치와 불확실성의 두 가지 출력을 얻기 위해 SPICE 모델에 오디오를 입력합니다.
model_output = model.signatures["serving_default"](tf.constant(audio_samples, tf.float32))
pitch_outputs = model_output["pitch"]
uncertainty_outputs = model_output["uncertainty"]불확실성은 확실의 반대이므로 1에서 불확실 output을 뺍니다.
confidence_outputs = 1.0 - uncertainty_outputs신뢰도가 낮은(신뢰도 <0.9) 모든 피치 추정치를 제거하고 나머지 값을 플롯하여 결과를 이해하기 쉽게 만들겠습니다.
confidence_outputs = list(confidence_outputs)
pitch_outputs = [ float(x) for x in pitch_outputs]
indices = range(len (pitch_outputs))
confident_pitch_outputs = [ (i,p)
for i, p, c in zip(indices, pitch_outputs, confidence_outputs) if c >= 0.9 ]
confident_pitch_outputs_x, confident_pitch_outputs_y = zip(*confident_pitch_outputs)
음표로 변환
이제 마지막 단계인 피치를 가지고 음표로 변환시키는 작업만 남아있습니다.
우선 가장 가능성이 높은 노래의 음표 시퀀스를 시도하고 추정해야 합니다.
0인 값은 rest값을 주고 나머지는 음표로 반화해줍니다.
def quantize_predictions(group, ideal_offset):
non_zero_values = [v for v in group if v != 0]
zero_values_count = len(group) - len(non_zero_values)
if zero_values_count > 0.8 * len(group):
return 0.51 * len(non_zero_values), "Rest"
else:
# 음표로 변환
h = round(
statistics.mean([
12 * math.log2(freq / C0) - ideal_offset for freq in non_zero_values
]))
octave = h // 12
n = h % 12
note = note_names[n] + str(octave)
error = sum([
abs(12 * math.log2(freq / C0) - ideal_offset - h)
for freq in non_zero_values
])
return error, note양자화와 에러를 구해주는 코드입니다.
def get_quantization_and_error(pitch_outputs_and_rests, predictions_per_eighth,
prediction_start_offset, ideal_offset):
pitch_outputs_and_rests = [0] * prediction_start_offset + \
pitch_outputs_and_rests
groups = [
pitch_outputs_and_rests[i:i + predictions_per_eighth]
for i in range(0, len(pitch_outputs_and_rests), predictions_per_eighth)
]
quantization_error = 0
notes_and_rests = []
for group in groups:
error, note_or_rest = quantize_predictions(group, ideal_offset)
quantization_error += error
notes_and_rests.append(note_or_rest)
return quantization_error, notes_and_rests
이제 get_quantization_and_error를 실행해줍니다.
best_error = float("inf")
best_notes_and_rests = None
best_predictions_per_note = None
for predictions_per_note in range(20, 65, 1):
for prediction_start_offset in range(predictions_per_note):
error, notes_and_rests = get_quantization_and_error(
pitch_outputs_and_rests, predictions_per_note,
prediction_start_offset, ideal_offset)
if error < best_error:
best_error = error
best_notes_and_rests = notes_and_rests
best_predictions_per_note = predictions_per_note
결과는 이런식으로 음표로 나옵니다.
print(best_notes_and_rests)
['D#2', 'D#2', 'D#2']