
Web Crawling
- 웹서비스의 여러 페이지를 이동하며 데이터를 수집하는 작업
웹크롤링 방법
웹페이지의 종류
- 정적인 페이지 : 웹 브라우져에 화면이 한번 뜨면 이벤트에 의한 화면의 변경이 없는 페이지
- 동적인 페이지 : 웹 브라우져에 화면이 뜨고 이벤트가 발생하면 서버에서 데이터를 가져와 화면을 변경하는 페이지
requests 이용
- json 문자열로 받아서 파싱하는 방법 : 주로 동적 페이지 크롤링할때 사용
- html 문자열로 받아서 파싱하는 방법 : 주로 정적 페이지 크롤링할때 사용
selenium 이용
- 브라우져를 직접 열어서 데이터를 받는 방법
속도 비교
requests json > requests html > selenium
requests 방식 크롤링
import
import requests
import pandas as pd # 데이터 처리를 위한
URL 구성하기
- 개발자 모드 -> 네트워크 상 URL을 가져옴
page, page_size = 1, 60
url = f'https://m.stock.naver.com/api/index/KOSPI/price?\pageSize={page_size}&page={page}'
요청하고 응답받기
response = requests.get(url)
response

다음과 같이 200을 출력한다면 정상적으로 응답을 받아온 것이다.
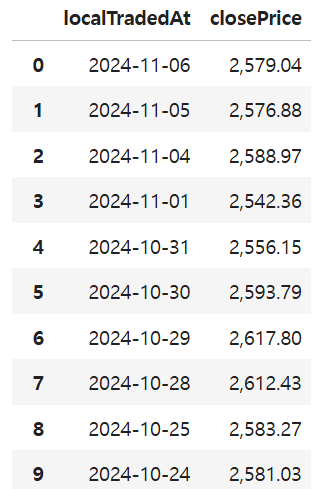
df 구성하기
columns = ["localTradedAt", "closePrice"]
data = response.json()
kospi_df = pd.DataFrame(data)[columns]
kospi_df
requests(REST API-공공데이터 포탈)
import
import requests, json
import pandas as pd # 데이터 처리를 위한
URL 구성하기
API 키 및 파라미터 설정
REST_API_KEY = "your-key"
resultType = 'json'
basDt = '20241105'
URL
url = f'http://apis.data.go.kr/1160100/service/GetStockSecuritiesInfoService/getStockPriceInfo?serviceKey={REST_API_KEY}&resultType={resultType}&basDt={basDt}'
요청하고 응답받기
response = requests.get(url)
response
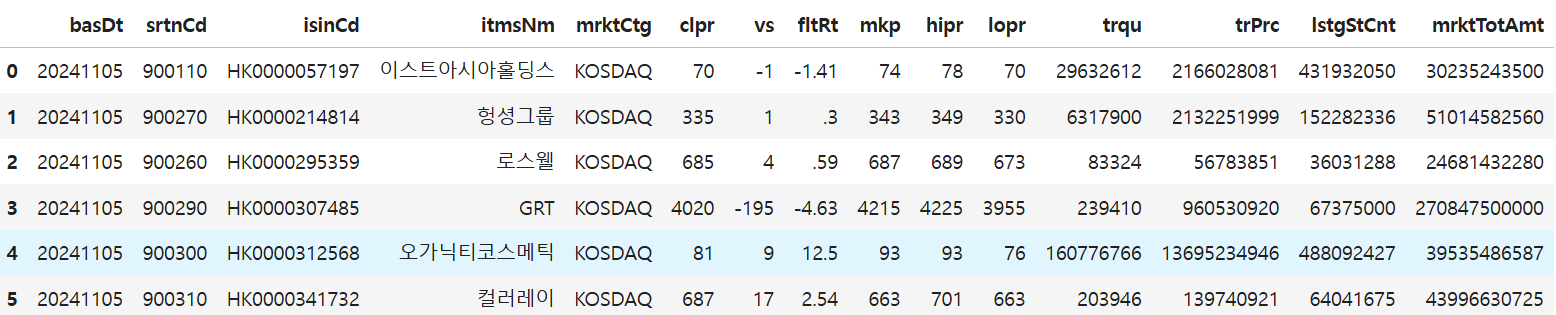
응답 분석하고 데이터로 json 형식 변경하기

- 다음과 같은 구조를 가진다.
- item들을 불러오기 위해서 response>body>items>item을 찾아야 한다.
data = repsonse.json()['response']['body']['items']['item']
df 구성하기
df = pd.DataFrame(data)
df
정정페이지 데이터 수집
import
import pandas as pd
import requests
from bs4 import BeautifulSoup
url 정의 및 호출
query = "삼성전자"
url = f"https://search.naver.com/search.naver?query={query}"
dom = BeautifulSoup(response.text, "html.parser")
정보가져오기
elements = dom.select(".fds-refine-query-grid a")
elements[0].text
element = elements[0]
link = element.get("href")
