What is?
- 데이터를 기반으로 학습하여 특정 작업을 수행하는 것
- 인간의 경험 = 머신의 데이터
- 데이터를 통해 학습을 하는 것
머신러닝 종류 분류
학습 방법에 따른 분류
지도학습
- 학습 대상이 되는 데이터에 정답을 주어 규칙성, 즉 데이터의 패턴을 배우게 하는 학습 방법
비지도 학습
- 정답이 없는 데이터 만으로 배우게 하는 학습 방법
강화 학습
- 선택한 결과에 대해 보상을 받아 행동을 개선하면서 배우게 하는 학습 방법
과제에 따른 분류
분류문제
- 이미 적절히 분류된 데이터를 학습하여 분류 규칙을 찾고, 그 규칙을 기반으로 새롭게 주어진 데이터를 적절히 분류하는 것을 목적으로 함(지도 학습)
회귀문제
- 이미 결과값이 있는 데이터를 학습하여 입력 값과 결과 값의 연관성을 찾고, 그 연관성을 기반으로 새롭게 주어진 데이터에 대한 값을 예측하는 것을 목적으로 함(지도 학습)
클러스터링
- 주어진 데이터를 학습하여 적절한 분류 규칙을 찾아 데이터를 분류함을 목적으로 함, 정답이 없어 성능 평가가 어려움(비지도 학습)
분류 vs 회귀
- 분류와 회귀에 따라 사용할 알고리즘과 평가 함수가 달라짐
- 예측 값에 연속성이 있으면 회귀
용어 정리
모델(Model)
- 데이터로부터 패턴을 찾아
- 수학식으로 정리해 놓은 것
- 모델링(Modeling): 오차가 적은 모델을 만드는 과정
모델의 목적
- 샘플을 가지고 전체를 추정
- 샘플: 표본, 부분집합, 일부, 과거의 데이터
- 전체: 모집단, 전체집합, 현재와 미래의 데이터
- 추정: 예측, 추론
행(Column)
열(Row)
독립변수, 종속변수
- 독립변수를 𝑥 로, 종속변수를 𝑦로 표시함
- 독립변수(원인)
- 종속변수(결과)
오차
- 통계학에서 사용되는 가장 단순한 모델 중 하나가 평균
- 관측값(=실젯값)과 모델 예측값의 차이: 이탈도(Deviance) → 오차
데이터 분리
- 데이터 셋을 학습용, 검증용, 평가용 데이터로 분리 함
- 평가용 데이터는 별도로 제공되는 데이터일 경우가 많음
- 검증용 데이터로 평가 전에 모델 성능을 검증해 볼 수 있음(튜닝 시 사용)
과대적합(Overfitting)
- 학습 데이터에 대해서는 성능이 매우 좋은데, 평가 데이터에 대해서는 성능이 매우 좋지 않은 경우
- 학습 데이터에 대해서만 잘 맞는 모델 → 실전에서 예측 성능이 좋지 않음
과소적합(Underfitting)
- 학습 데이터보다 평가 데이터에 대한 성능이 매우 좋거나, 모든 데이터에 대한 성능이 매우 안 좋은 경우
- 모델이 너무 단순하여 학습 데이터에 대해 적절히 훈련되지 않은 경우
모델링 코드
구조
- 불러오기
- 선언하기
- 학습하기
- 예측하기
- 평가하기
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_absolute_error
model = LinearRegression()
model.fit(x_train, y_train)
y_pred = model.predict(x_test)
mean_absolute_error(y_test, y_pred)
성능평가
회귀 모델 성능 평가
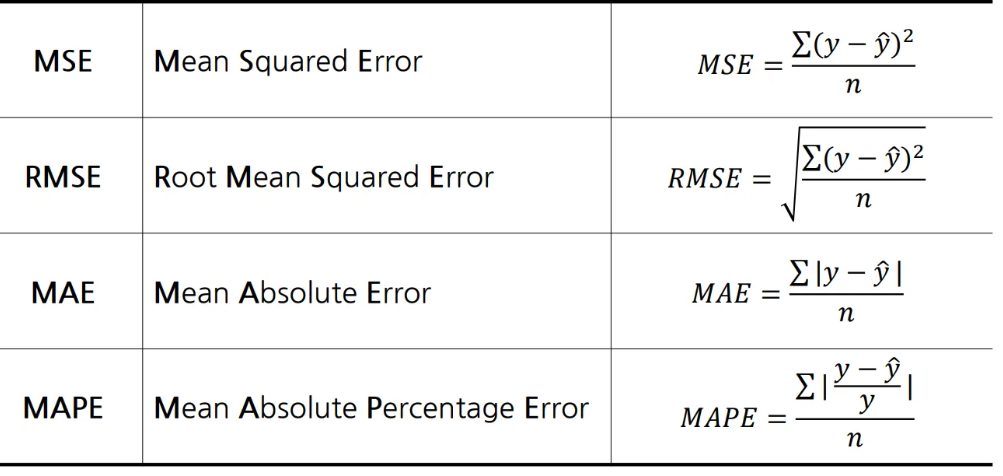
결정 계수 R^2(R-Squared)
- Coefficient of Determination
- MSE로 여전히 설명이 부족한 부분이 있음(성능이 확실히 와 닿지 않음)
- 모델 성능을 잘 해석하기 위해서 만든 MSE의 표준화된 버전이 결정 계수임
- 전체 오차 중에서 회귀식이 잡아낸 오차 비율(일반적으로 0 ~ 1 사이)
- 오차의 비 또는 설명력이라고도 부름
- 𝑅^2 = 1이면 𝑀𝑆𝐸 = 0이고 모델이 데이터를 완벽하게 학습한 것
code
from sklearn.metrics import mean_squared_error
from sklearn.metrics import mean_absolute_error
from sklearn.metrics import mean_absolute_percentage_error
from sklearn.metrics import r2_score
print(mean_absolute_error(y_test, y_pred))
분류 모델 성능 평가
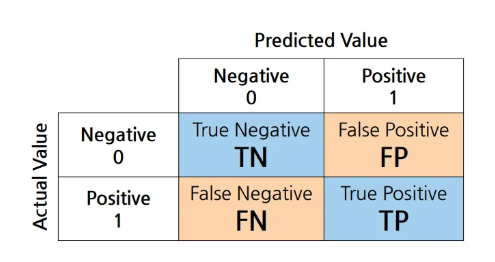
Accuracy(정확도)
- 정분류율 이라고 부르기도 함
- 전체 중에서 Positive와 Negative 로 정확히 예측한(TN + TP) 비율
- Negative를 Negative로 예측한 경우도 옳은 예측임을 고려하는 평가지표
- 가장 직관적으로 모델 성능을 확인할 수 있는 평가지표
Precision(정밀도) / 예측 관점
- Positive로 예측한 것(FP + TP) 중에서 실제 Positive(TP)인 비율
- 비가 내릴 것으로 예측한 날 중에서 실제 비가 내린 날의 비율
Recall(재현율) / 실제 관점
- 실제 Positive(FN + TP) 중에서 Positive로 예측한(TP) 비율
- 민감도(Sensitivity)라고 부르는 경우가 많음
- 실제 비가 내린 날 중에서 비가 내릴 것으로 예측한 날의 비율
Specificity(특이도)
- 실제 Negative(TN + FP) 중에서 Negative로 예측한(TN) 비율
- 실제 비가 내리지 않은 날 중에서 비가 내리지 않을 것으로 예측한 날의 비율
F1-Score
- 정밀도와 재현율의 조화 평균
- 분자가 같지만 분모가 다를 경우, 즉 관점이 다른 경우 조화 평균이 큰 의미를 가짐
- 정밀도와 재현율이 적절하게 요구 될 때 사용
code
from sklearn.metrics import accuracy_score
from sklearn.metrics import precision_score
from sklearn.metrics import recall_score
from sklearn.metrics import f1_score
from sklearn.metrics import confusion_matrix
from sklearn.metrics import classification_report
print(accuracy_score(y_test, y_pred))
print(precision_score(y_test, y_pred, average=None))

