
감성 분류 모델 구축과 예측
학습 내용
- 감성 분류 모델을 구축하여 새로운 데이터의 감성을 분석
- 과정 : 데이터 준비 -> 분석 모델 구축 -> 분석 모델 평가
모듈 설치
- JDK (Java SE Downloads)
- JAVA_HOME 설정
- JPype1설치(1.2.0) → 버전에 맞는 패키지 수동설치
- KoNLPy 설치 (파이참)
파이썬 3.8이하 (중요)
핵심 개념
-
텍스트 전처리 -> 특성 벡터화 -> 머신러닝 모델 구축 및 학습/평가 프로세스 수행
-
텍스트 전처리에는 토큰화, 불용어 처리, 형태소 분석 등의 작업이 포함

단어 표현의 카테고리화
- 머신러닝 알고리즘으로 분석하기 위해서는 텍스트를 구성하는 단어 기반의 특성 추출을 하
고 이를 숫자형 값인 벡터 값으로 표현해야 함 - 대표적인 방법으로 BoW(Bag of Words)와 Word2vec가 있음
- Bag of Words는 국소 표현에(Local Representation)에 속하며, 단어의 빈도수를 카운트하여 단어를 수치화 하는 단어 표현 방법
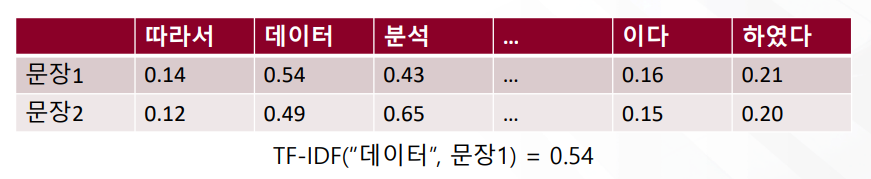
- DTM 내에 있는 각 단어에 대한 중요도를 계산할 수 있는 TF-IDF 가중치 방법이 있음
- TF-IDF를 사용하면, 기존의 DTM을 사용하는 것보다 보다 더 많은 정보를 고려하여 문서들을 비교할 수 있음
카운트 기반 벡터화
-
단어 피처에 숫자형 값을 할당할 때 각 문서에서 해당 단어가 등장하는 횟수(단어 빈도)를 부
여하는 벡터화 방식 -
문서 별 단어의 빈도를 정리하여 문서 단어 행렬(DTM)을 구성하는 데 단어 출현 빈도가 높을
수록 중요한 단어로 다루어 짐 -
문서 d에 등장한 단어 t의 횟수는 tf(t,d)로 표현
-
카운트 기반 벡터화는 사이킷런의 CountVectorizer 모듈에서 제공

TF-IDF 기반 벡터화
-
특정 문서에 많이 나타나는 단어는 해당 문서의 단어 벡터에 가중치를 높임
-
모든 문서에 많이 나타나는 단어는 범용적으로 사용하는 단어로 취급하여 가중치를 낮추는 방식
-
d에 등장한 단어 t의 TF-IDF
-
TfidfVectorizer함수 제공
감성 분석(오피니언 마이닝)
- 텍스트에서 사용자의 주관적인 의견이나 감성, 태도를 분석하는 텍스트 마이닝의 핵심 분석 기법 중 하나
- 텍스트에서 감성을 나타내는 단어를 기반으로 긍정 또는 부정의 감성을 결정
- 감성 사전 기반의 감성 분석은 감성 단어에 대한 사전(관련분야의 말뭉치 구축)을 가진 상태에서 단어를
검색하여 점수를 계산 - 최근에는 머신러닝 기반의 감성 분석이 늘어나고 있음
로지스틱 회귀(Logistic Regression)분석
- 일상 속 풀고자 하는 많은 문제 중에서는 두 개의 선택지 중에서 정답을 고르는 문제가 많음
- 감성분류에서는 긍정과 부정을 결정하는 문제에 활용
- 둘 중 하나를 결정하는 문제를 이진 분류(Binary Classification)라고 하며, 이런 문제를 풀기 위한 대표적인 알고리즘으로 로지스틱 회귀를 활용
데이터 수집
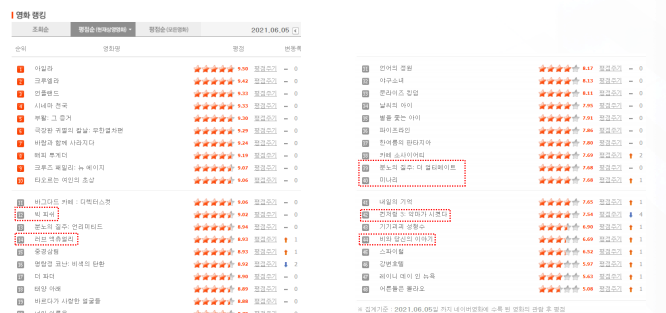
네이버 영화 댓글 크롤링
- 네이버 영화 페이지에서 리뷰를 크롤링하여 수집
- 평이 좋은 영화와 좋지않은 영화를 골고루 선택하여 15000개 댓글을 수집(50개 영화 권장)
네이버 영화 사이트
긍정/부정 분류
- 파일 내용은 3개의 컬럼 (no, score, text)으로 구성
- score 컬럼은 감성 분류 클래스 값, text 는 댓글
- 긍정/부정 값은 1~10점의 평점 중에서 중립적인 평점인 5~8점은 제외하고 1~4점을 부정 감성 0으로, 9~10점을 긍정 감성 1로 표시

패키지 설치 및 Train 데이터 불러오기
# 패키지 설치 import pandas as pd #warning 메시지 표시 안함 import warnings warnings.filterwarnings(action = 'ignore') from konlpy.tag import Okt # 형태소 분석에 사용할 konlpy 패키지의 Okt 클래스를 임포트하고 okt 객체를 생성 okt = Okt() # Train 데이터 불러오기 train_df = pd.read_excel('movie_data/5movies.xlsx') # 데이터 확인 print(train_df.head())

결측 값 처리
# 댓글이 있는 항목만 담기(빈 댓글 삭제) # text 컬럼이 non-null인 샘플만 train_df에 다시 저장 train_df = train_df[train_df['text'].notnull()] # 수정된 train_df의 정보를 다시 확인 print(train_df.info()) # 분류 클래스의 구성을 확인 print(train_df['score'].value_counts())
분석 불가능한 문자 제거
# 한글 외 문자 제거(옵션) import re # 정규식을 사용하기 위해 re 모듈을 임포트 # ‘ㄱ ~‘힣’까지의 문자를 제외한 나머지는 공백으로 치환, 영문: a-z| A-Z train_df['text'] = train_df['text'].apply(lambda x : re.sub(r'[^ ㄱ-ㅣ가-힣]+', " ", x)) print(train_df.head()) # Train용 데이터셋의 정보를 재확인 print(train_df.info()) text = train_df['text’] # 시리즈 객체로 저장 score = train_df['score']
데이터 셋 분리
# Train용 데이터셋과 Test용 데이터 셋 분리 # 1. 예측력을 높이기 위해 수집된 데이터를 학습용과 테스트 용으로 분리하여 진행 # 2. 보통 20~30%를 테스트용으로 분리해 두고 테스트 from sklearn.model_selection import train_test_split train_x, test_x, train_y, test_y = train_test_split(text, score , test_size=0.2, random_state=0) print(len(train_x), len(train_y), len(test_x), len(test_y))
토큰화 및 TF-IDF 벡터화
- 토큰화(tokenization)는 주어진 코퍼스(corpus)에서 토큰(token)이라 불리는 단위로 나눔
- 토큰화에서 고려해야 할 사항
- 구두점이나 특수문자를 단순 제외해도 무방한지 확인 (ex, Ph.D, AT&T, $2,000, 11/22/1990, 45.34)
- 줄임말과 단어 내 띄어쓰기 (we’re, thx, 고대, 영끌)
- 한국어는 어절 독립단어가 아니므로 형태소(자립, 의존) 분해가 필요
- 한국어는 띄어쓰기가 지켜지지 않고 있음
- TF-IDF 벡터화(단어 빈도-역 문서 빈도: Term Frequency-Inverse Document Frequency)
from sklearn.feature_extraction.text import TfidfVectorizer tfv = TfidfVectorizer(tokenizer=okt.morphs, ngram_range=(1,2), min_df=3, max_df=0.9) tfv.fit(train_x) tfv_train_x = tfv.transform(train_x) print(tfv_train_x)

감성 분석 모델 구축
- 로지스틱 회귀(Logistic Regression) (이진분류 알고리즘)
from sklearn.linear_model import LogisticRegression # 이진 분류 알고리즘 from sklearn.model_selection import GridSearchCV # 하이퍼 파라미터 최적화 clf = LogisticRegression(random_state=0) params = {'C': [15, 18, 19, 20, 22]} grid_cv = GridSearchCV(clf, param_grid=params, cv=3, scoring='accuracy', verbose=1) grid_cv.fit(tfv_train_x, train_y) # 최적의 평가 파라미터는 grid_cv.best_estimator_에 저장됨 print(grid_cv.best_params_, grid_cv.best_score_)# 가장 적합한 파라메터, 최고 정확도 확인
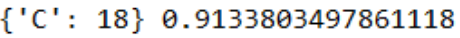
분석 모델 평가
- 평가용 데이터의 특징 벡터화
tfv_test_x = tfv.transform(test_x) # test_predict = grid_cv.best_estimator_.score(tfv_test_x,test_y) test_predict = grid_cv.best_estimator_.predict(tfv_test_x) from sklearn.metrics import accuracy_score print('감성 분류 모델의 정확도 : ',round(accuracy_score(test_y, test_predict), 3))

감성 예측
- 감성 예측하기
input_text = '딱히 대단한 재미도 감동도 없는데 ~! 너무 과대 평과된 영화 중 하나' #입력 텍스트에 대한 전처리 수행 input_text = re.compile(r'[ㄱ-ㅣ가-힣]+').findall(input_text) input_text = [" ".join(input_text)] # 입력 텍스트의 피처 벡터화 st_tfidf = tfv.transform(input_text) # 최적 감성 분석 모델에 적용하여 감성 분석 평가 st_predict = grid_cv.best_estimator_.predict(st_tfidf) #예측 결과 출력 if(st_predict == 0): print('예측 결과: ->> 부정 감성') else : print('예측 결과: ->> 긍정 감성')





데이터 분석 유튜버 "거친코딩"입니다.