
파이썬을 활용한 웹 크롤링 #1
크롤링이란?
- 크롤링(Crawling)이란 사전적 의미로 기어다니다를 뜻하고, Web에서는 돌아다니면서 원하는 정보를 수집하는 행위를 의미한다.
- 크롤링의 대상은 위에서 언급한 대로 웹 상에 존재하는 정보들이며, 해당 정보는 다양한 형태로 존재할 수 있다.(이미지, 텍스트, API 등)
- 크롤링은 크게 두 가지로 나누어 질 수 있다. (정적 크롤링 VS 동적 크롤링)
- 정적 크롤링
- 특별한 절차 없이 특정 URL을 통해 데이터 수집 가능
- 새로고침하지 않으면 페이지 안의 데이터는 변하지 않는다.
- 속도가 빠르다.
- 수집 대상에 한계 존재한다.
- 사용 가능 라이브러리 : requests
- 동적 크롤링
1. 특별한 절차 없이 특정 URL을 통해 데이터 수집 불가능(네이버 메일의 경우)
2. 속도가 느리다.
3. 수집 대상에 한계가 거의 존재하지 않는다.- 사용 가능 라이브러리 : selenium
실습 예제
- 가상 환경 구축(파이썬 가상환경 기준)
python -m venv [가상환경 이름]
- vscode 실행 -> Ctrl + Shift + P -> crawling 검색 및 클릭
<cmd 환경>
pip install requests
pip install bs4
pip install selenium
pip install numpy
- 설치 라이브러리 requirements.txt에 작성
(쇼핑몰) 크롤링하기
Http GET Request
req = requests.get(쇼핑몰 주소)
HTML 소스 가져오기
html = req.text
HTTP Header 가져오기
header = req.headers
HTTP Status 가져오기 (200: 정상)
status = req.status_code
HTTP가 정상적으로 되었는지 (True/False)
is_ok = req.ok
BeautifulSoup
- Requests를 통해서 html를 받아올 수는 있지만, Python이 이해하는 객체 구조로 직렬화시켜주지는 못한다.
- 받아온 html를 의미있는 형태로 만들어주기 위해서 BeautifulSoup을 사용하고 해당 라이브러리는 객체 구조를 변환시켜주는 Parsing 역할을 맡고있다.
from urllib.request import Request
from urllib.request import urlopen
from bs4 import BeautifulSoup
import urllib.request
import re
import numpy as np
import time
import os
import random
import timeHttp GET Request
url = [쇼핑몰주소]
req = Request(url,headers={'User-Agent':'Mozila/5.0'})
webpage = urlopen(req)
soup = BeautifulSoup(webpage)
- 이제 다시 해당 사이트의 개발자도구(F12)를 열고 필요한 데이터 태그를 파악하자
- soup.find
- 목적은 원하는 태그를 찾는 것
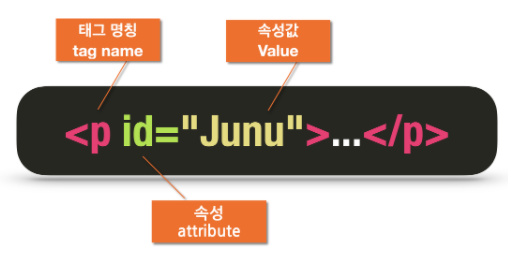
태그 이름과 속성 모두 특정
objects = soup.find('li',id='big_section')
- 태그 살펴보기
obejcts.text 태그에 담긴 텍스트
print(objects.text)
objects.name 태그의 이름
print(objects.name)
objects.attrs 태그의 속성과 속성값
print(objects.attrs)
- 실전 연습
길이가 1이 되는지 확인 (유일성 확인)
len(soup.find_all('div',id='big_section'))
gif 이미지가 나와서, 이건 내가 원하는 정적 이미지가 아니다.
soup.find('div',id='bigsection').find_all('li',class='goods-form')[0].find('div',class_='prdimg').find('img')['src']
gif 이미지 말고 정적 이미지를 얻기 위해 해당 url 접속
souphref = soup.find('div',id='big_section').find_all('li',class='goods-form')[0].find('div',class_='prdimg').find('a')['href']
base_site = 'https://attrangs.co.kr/'
detail_site = base_site+soup_href # detail한 page url 획득
req = Request(detail_site,headers={'User-Agent':'Mozila/5.0'})
webpage = urlopen(req) # 새로운 detail_site 접속
soup = BeautifulSoup(webpage) # 데이터 파싱
print(len(soup.findall('div',id='detail'))) (유일성 확인)
soup.find('div',id='detail').find('div',id='mimg_div',class='img').find('img')['src']
- 실전
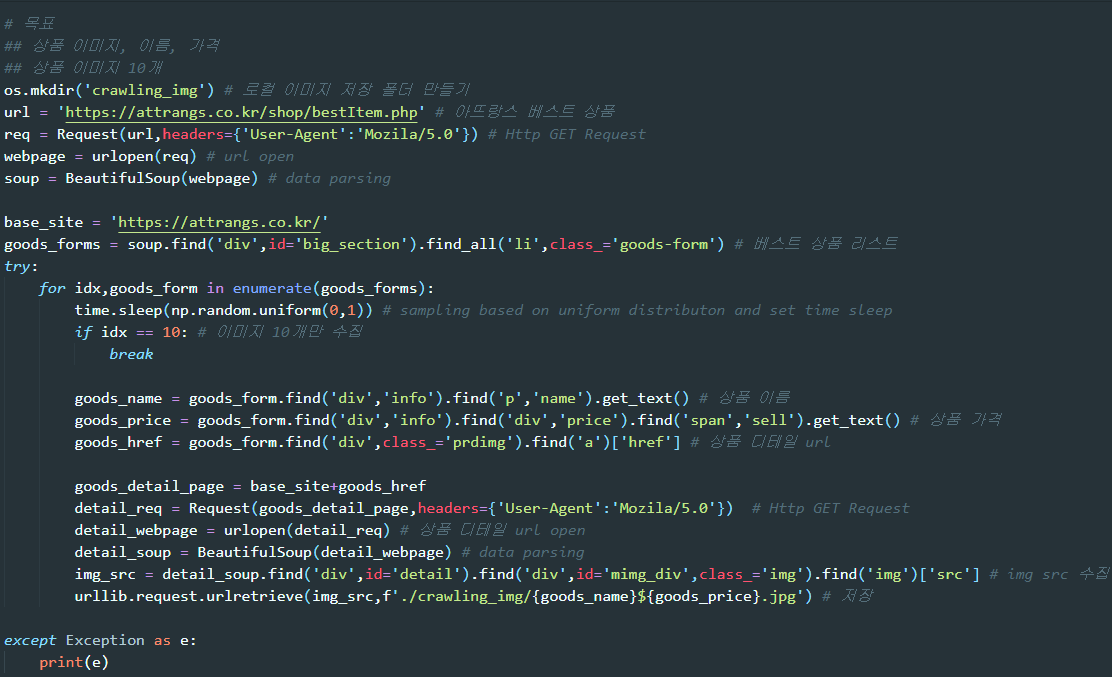
목표
상품 이미지, 이름, 가격 데이터 수집
상품 이미지 10개만 수집

많은 도움 됐습니다.
좋은글 감사합니다😊