파이썬을 활용한 웹 크롤링 #2
자연어 처리와 워드크라우드 과정

- BeutifulSoup 라이브러리를 통해 웹 데이터 크롤링
- 크롤링된 데이터를 KoNLPy 라이브러리를 통해 형태소 분석
- 형태소 분석된 데이터를 wordcloud로 시각화
고려대학교 커뮤니티 크롤링
import requests import pandas as pd url = 'https://www.koreapas.com/bbs/main.php' html = requests.get(url,headers={'User-Agent':'Mozila/5.0'}) pd.read_html(html.text)
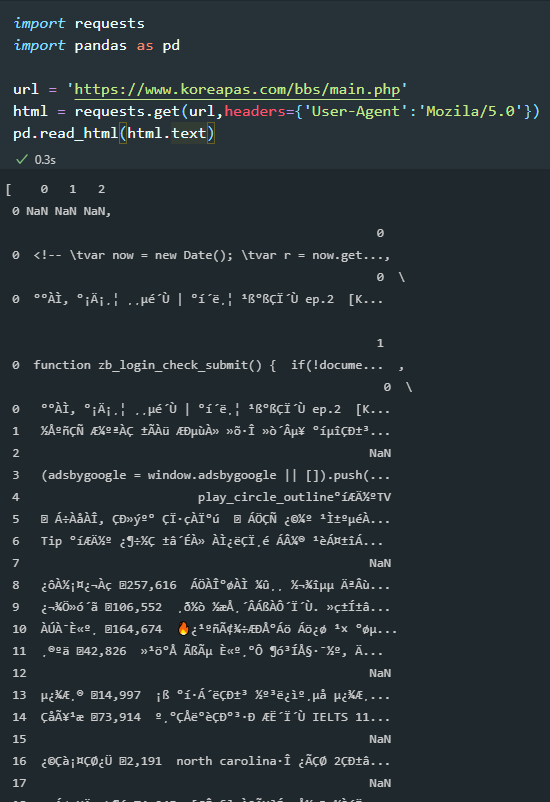
- 일반 request.get으로 가져온 html source를 pandas table로 parsing할 때는 우리가 알 수 없는 형태로 나와진다.
- 그래서 우리는 BeautifulSoup라이브러리를 사용해야 한다.
사용해야할 패키지
- urllib
- 파이썬에 내장되어 있고 URL를 다루는 모듈
- BeautifulSoup
- html의 데이터를 더 가시적으로 parsing하도록 도와주는 모듈
pip install beautifulsoup4 from bs4 import BeautifulSoup import urllib.request url = 'https://www.koreapas.com/bbs/main.php' html = urllib.request.urlopen(url) html.read() >b'<!DOCTYPE html> \r\n<html xmlns="http://www.w3.org/1999/xhtml" lang="ko" xml:lang="ko">\r\n<head>\r\n <meta http-equiv="Content-Type" content="text/html; charset=euc-kr" />\r\n<meta http-equiv="Content-Script-T ype" content="text/javascript" />\r\n< meta http-equiv="Content-Style-Type" content="text/css" />\r\n<meta http-equiv="X-UA-Compatible" conten>
- 일반 requests 라이브러리에서는 안되던 것들이 urllib.request를 사용하여 데이터를 가져올 수 있음
웹사이트 접근 및 개발자 도구(F12) 이해
- 크롬의 경우 F12를 누르고 Ctrl + Shift + C 키를 누르고 원하는 정보에 마우스 클릭
- 원하는 정보의 html tag이름, class과 id 확인
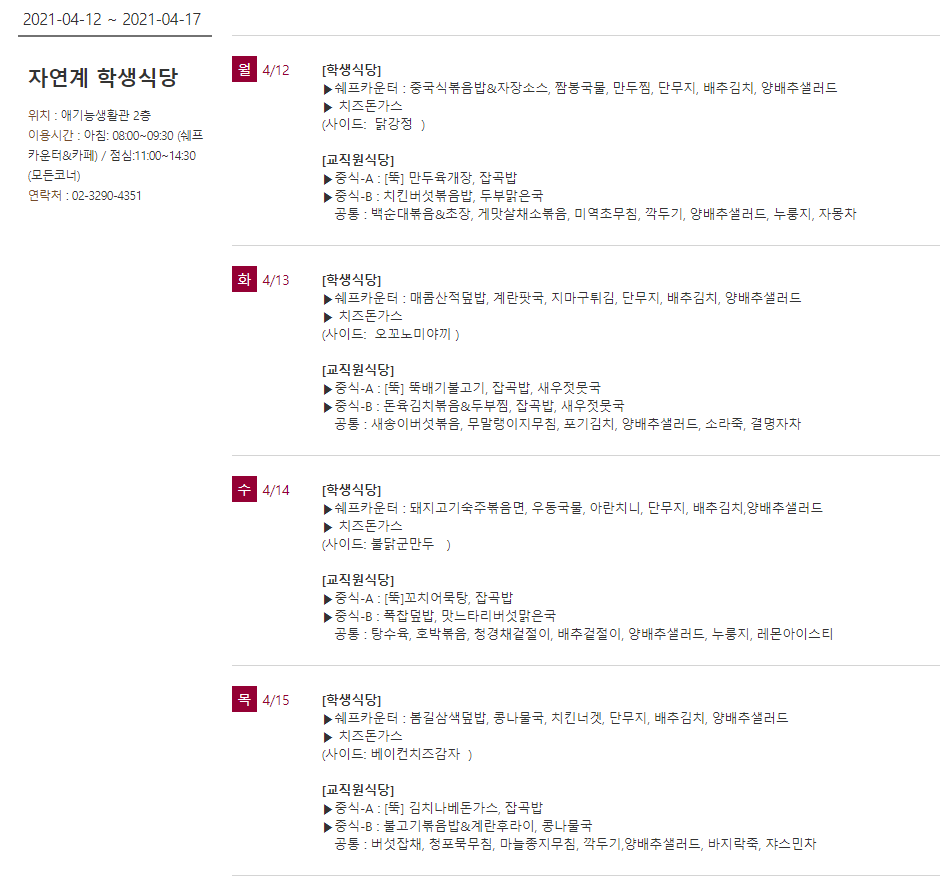
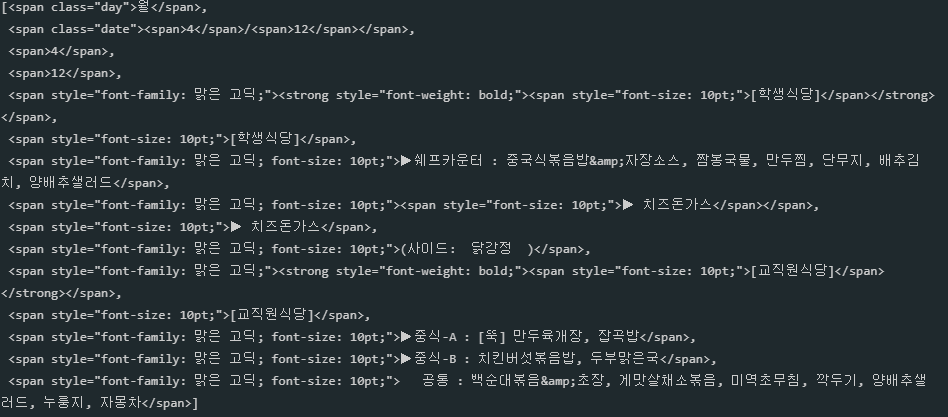
from bs4 import BeautifulSoup import urllib.request # 고려대학교 학생 식당 크롤링 url = 'https://www.koreapas.com/bbs/sik.php?back=1' html = urllib.request.urlopen(url) soup = BeautifulSoup(html,'html.parser') soup.find('div',class_='ku_restaurant mb60').find('li').find_all('ol')[0].find_all('span')
기상청 데이터 크롤링
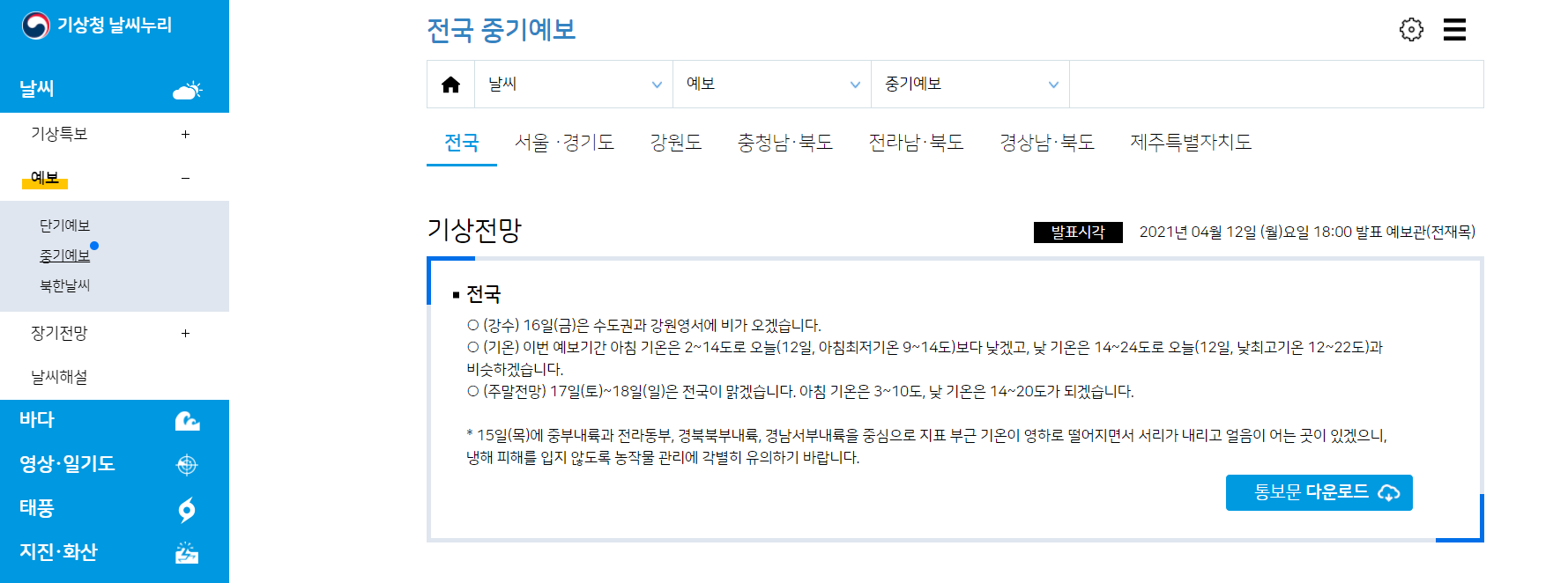
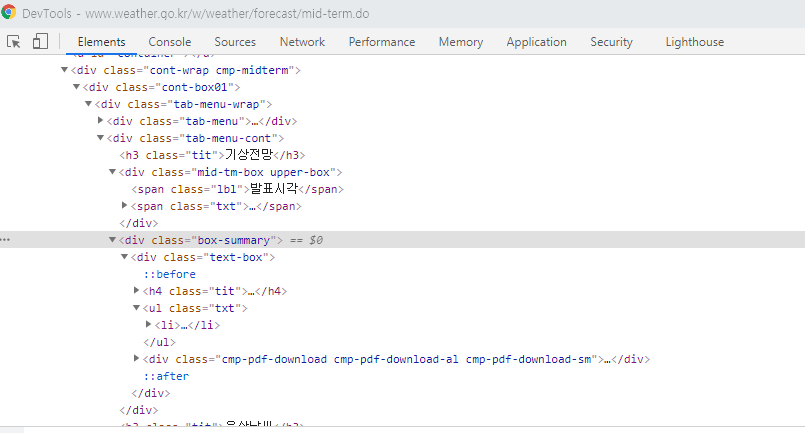
# 기상청 크롤링 url = 'https://www.weather.go.kr/w/weather/forecast/mid-term.do' html = urllib.request.urlopen(url) soup = BeautifulSoup(html,'html.parser') notified_at = soup.find('div',class_='mid-tm-box upper-box') print(notified_at.get_text()) print('===========================') contents = soup.find('div',class_='box-summary').find('li') print(contents.get_text())


데이터 분석 유튜버 "거친코딩"입니다.